取酷专题

爬虫(六):案例:爬取扇贝英语单词+爬取网易云所有歌手+爬取酷狗音乐所有歌手
文章目录 爬取网站的流程案例一:使用xpath爬取扇贝英语单词案例二:爬取网易云音乐的所有歌手名字案例三:爬取酷狗音乐的歌手和歌单 爬取网站的流程 确定网站的哪个url是数据的来源简要分析一下网站结构,查看数据存放在哪里查看是否有分页,并解决分页的问题发送请求,查看response.text是否有我们所需要的数据筛选数据 案例一:使用xpath爬取扇贝英语单词 需求:爬
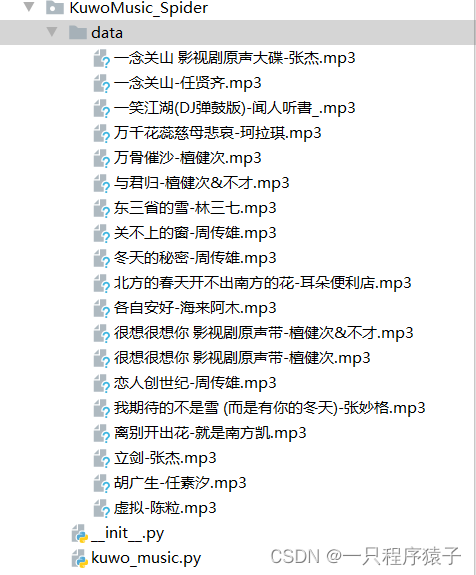
Python爬取酷我音乐
🎈 博主:一只程序猿子 🎈 博客主页:一只程序猿子 博客主页 🎈 个人介绍:爱好(bushi)编程! 🎈 创作不易:喜欢的话麻烦您点个👍和⭐! 🎈 欢迎访问我的主页(点我直达) 🎈 除此之外您还可以通过个人名片联系我 👉👉👉👉👉👉 额滴名片儿 目录 1.介绍 2.步骤分析 (1)登录酷我音乐 (2)找到歌曲信息 (3)找到歌曲播放地址 3.代码

python网络爬虫-爬取酷狗TOP500的数据 源码
一家懂得用细节留住客户的3年潮牌老店我必须支持!➕🛰:luyao1931 python网络爬虫-爬取酷狗TOP500的数据 import requestsfrom bs4 import BeautifulSoupimport timeheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537

【python】爬取酷狗音乐Top500排行榜【附源码】
一、导入必要的模块: 这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图片信息并保存到本地。我们将使用requests模块发送HTTP请求和接收响应,以及os模块处理文件和目录操作。 如果出现模块报错 进入控制台输入:建议使用国内镜像源 pip install requests -i https://mirrors.

Python网络爬虫实战13:爬取酷狗音乐中粤语金曲榜的歌曲
目录 1. 网页源码 2. 代码实例 3. 运行结果 1. 网页源码 2. 代码实例 # coding:utf8import requestsfrom bs4 import BeautifulSoupurl = "https://www.kugou.com/yy/rank/home/1-33165.html?from=rank" # 粤语金曲榜网
Python爬取酷我音乐
🎈 博主:一只程序猿子 🎈 博客主页:一只程序猿子 博客主页 🎈 个人介绍:爱好(bushi)编程! 🎈 创作不易:喜欢的话麻烦您点个👍和⭐! 🎈 欢迎访问我的主页(点我直达) 🎈 除此之外您还可以通过个人名片联系我 👉👉👉👉👉👉 额滴名片儿 目录 1.介绍 2.步骤分析 (1)登录酷我音乐 (2)找到歌曲信息 (3)找到歌曲播放地址 3.代码
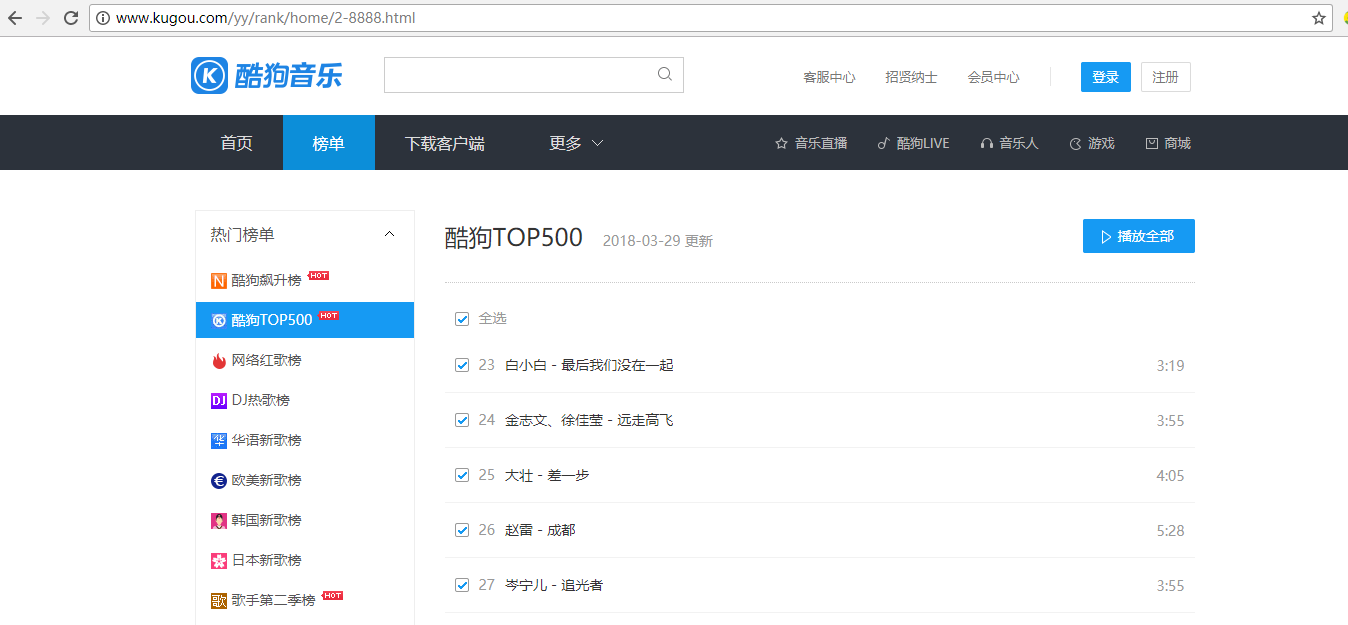
爬取酷狗榜单中的top500
首先先看到top500的页面,如下图所示 网页版的酷狗没有翻页的操作,所以不能看到后面页数的链接,根据第一页的链接,http://www.kugou.com/yy/rank/home/1-8888.html 我们尝试把链接里面的数字1改为2,果然跳转到第二页去了,这样就好办了,每页显示22条歌曲,所以经过计算,需要23条url链接,后面自己手动创建url 具体的操作和解释都下面代码中