本文主要是介绍【python】爬取酷狗音乐Top500排行榜【附源码】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、导入必要的模块:
这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图片信息并保存到本地。我们将使用requests模块发送HTTP请求和接收响应,以及os模块处理文件和目录操作。
如果出现模块报错
进入控制台输入:建议使用国内镜像源
pip install requests -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple阿里云
https://mirrors.aliyun.com/pypi/simple/豆瓣
https://pypi.douban.com/simple/ 百度云
https://mirror.baidu.com/pypi/simple/中科大
https://pypi.mirrors.ustc.edu.cn/simple/华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
二、发送GET请求获取响应数据:
设置了请求头部信息,以模拟浏览器的请求,函数返回响应数据的JSON格式内容。
def get_html(url):header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}response = requests.get(url=url, headers=header)# print(response.json())html = response.json()return html如何获取请求头:
火狐浏览器:
- 打开目标网页并右键点击页面空白处。
- 选择“检查元素”选项,或按下快捷键Ctrl + Shift + C(Windows)
- 在开发者工具窗口中,切换到“网络”选项卡。
- 刷新页面以捕获所有的网络请求。
- 在请求列表中选择您感兴趣的请求。
- 在右侧的“请求标头”或“Request Headers”部分,即可找到请求头信息。
将以下请求头信息复制出来即可
三、爬取酷狗TOP500排行榜
从酷狗音乐排行榜中提取歌曲的排名、歌名、歌手和时长等信息

具体步骤如下:
导入需要的模块:
requests用于发送HTTP请求,BeautifulSoup用于解析HTML,time用于控制爬虫的速度。设置请求头部信息:通过
headers字典设置了User-Agent,模拟浏览器发送请求,防止被网站封禁。定义函数
get_info(url):该函数接收一个URL参数,用于爬取指定网页的信息。发送网络请求并解析HTML:使用
requests.get()函数发送GET请求获取网页的HTML内容,并使用BeautifulSoup模块解析HTML。通过CSS选择器定位需要的信息:使用
select()方法根据CSS选择器定位到歌曲的排名、歌名和时长等元素。循环遍历每个信息并存储到字典中:使用
zip()函数将排名、歌名和时长等元素打包成一个迭代器,然后通过循环遍历,将每个信息存储到data字典中。打印获取到的信息:使用
print()函数打印data字典中的信息。主程序入口:使用
if __name__ == '__main__':判断当前文件是否被直接执行,如果是则执行以下代码。构造要爬取的页面地址列表:使用列表推导式构造一个包含要爬取的页面地址的列表。
调用函数获取页面信息:使用
for循环遍历页面地址列表,并调用get_info()函数获取每个页面的信息。控制爬虫速度:使用
time.sleep()函数控制爬虫的速度,防止过快被封IP。
源码:
import requests # 发送网络请求,获取 HTML 等信息
from bs4 import BeautifulSoup # 解析 HTML 信息,提取需要的信息
import time # 控制爬虫速度,防止过快被封IPheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"# 添加浏览器头部信息,模拟请求
}def get_info(url):# 参数 url :要爬取的网页地址web_data = requests.get(url, headers=headers) # 发送网络请求,获取 HTML 等信息soup = BeautifulSoup(web_data.text, 'lxml') # 解析 HTML 信息,提取需要的信息# 通过 CSS 选择器定位到需要的信息ranks = soup.select('span.pc_temp_num')titles = soup.select('div.pc_temp_songlist > ul > li > a')times = soup.select('span.pc_temp_tips_r > span')# for 循环遍历每个信息,并将其存储到字典中for rank, title, time in zip(ranks, titles, times):data = {"rank": rank.get_text().strip(), # 歌曲排名"singer": title.get_text().replace("\n", "").replace("\t", "").split('-')[1], # 歌手名"song": title.get_text().replace("\n", "").replace("\t", "").split('-')[0], # 歌曲名"time": time.get_text().strip() # 歌曲时长}print(data) # 打印获取到的信息if __name__ == '__main__':urls = ["https://www.kugou.com/yy/rank/home/{}-8888.html".format(str(i)) for i in range(1, 24)]# 构造要爬取的页面地址列表for url in urls:get_info(url) # 调用函数,获取页面信息time.sleep(1) # 控制爬虫速度,防止过快被封IP
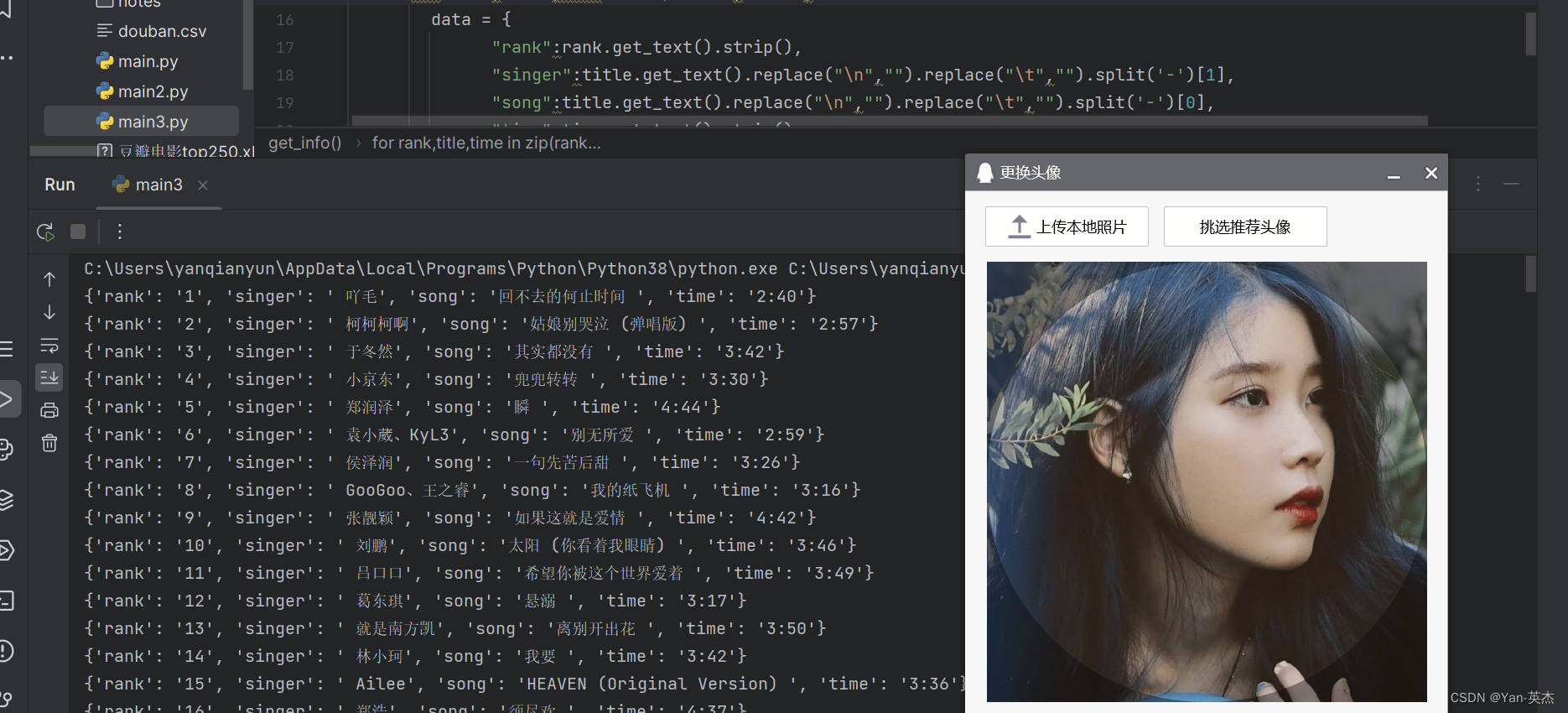
效果图:
给大家推荐一个网站
IT今日热榜 一站式资讯平台

里面包含了上百个IT网站,欢迎大家访问:IT今日热榜 一站式资讯平台
iToday,打开信息的新时代。作为一家创新的IT数字媒体平台,iToday致力于为用户提供最新、最全面的IT资讯和内容。里面包含了技术资讯、IT社区、面试求职、前沿科技等诸多内容。我们的团队由一群热爱创作的开发者和分享的专业编程知识爱好者组成,他们精选并整理出真实可信的信息,确保您获得独特、有价值的阅读体验。随时随地,尽在iToday,与世界保持连接,开启您的信息新旅程!
IT今日热榜 一站式资讯平台IT今日热榜汇聚各类IT热榜:虎嗅、知乎、36氪、京东图书销售、晚点、全天候科技、极客公园、GitHub、掘金、CSDN、哔哩哔哩、51CTO、博客园、GitChat、开发者头条、思否、LeetCode、人人都是产品经理、牛客网、看准、拉勾、Boss直聘http://itoday.top/#/
这篇关于【python】爬取酷狗音乐Top500排行榜【附源码】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






