本文主要是介绍Python爬取酷我音乐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🎈 博主:一只程序猿子
🎈 博客主页:一只程序猿子 博客主页
🎈 个人介绍:爱好(bushi)编程!
🎈 创作不易:喜欢的话麻烦您点个👍和⭐!
🎈 欢迎访问我的主页(点我直达)
🎈 除此之外您还可以通过个人名片联系我 👉👉👉👉👉👉

额滴名片儿
目录
1.介绍
2.步骤分析
(1)登录酷我音乐
(2)找到歌曲信息
(3)找到歌曲播放地址
3.代码实现
4.效果展示
1.介绍
本文将介绍Python爬虫如何实现爬取网页版酷我的榜单音乐并下载到本地!
2.步骤分析
(1)登录酷我音乐
这一步的目的是获取cookie!
(2)找到歌曲信息
找到榜单中歌曲的列表 ,获取歌曲的关键信息!
 这里我们只需要其中的三个值:
这里我们只需要其中的三个值:
1.arltist: 歌手名
2.name: 歌曲名
3.rid: 歌曲id
歌手名和歌曲名用来给爬取到的.mp3文件命名,通过歌曲id获取歌曲的播放地址
(3)找到歌曲播放地址
随便点击播放一首歌,就可以找到这个数据包!

大致流程如下:
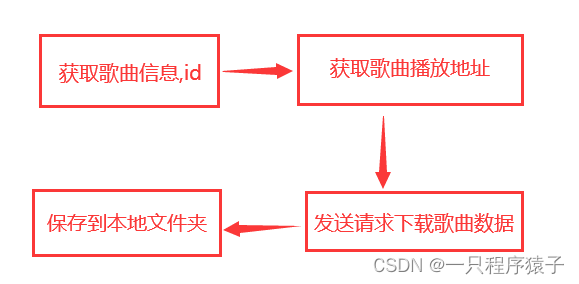
由于CSDN的版权限制,有很多截图我都被迫删掉了,可能你暂时无法理解如何找到的请求地址和参数!但是在代码中你可以看到每个url的作用!
现在我们已经找到了歌曲信息和歌曲的播放地址,就可以用python的requests构建请求了!
3.代码实现
import timeimport requests# cookies,登录账号后很容易在请求头中找到自己的cookies
cookies = "换成你的"
# 构造请求头
headers = {'Accept': 'application/json, text/plain, */*','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive',# 'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1702174705; _ga=GA1.2.1391285853.1702174705; _gid=GA1.2.1100462848.1702174705; uname3=%u6C34%u661F.; t3kwid=460193919; userid=460193919; websid=1549266808; pic3="http://img4.kuwo.cn/star/userhead/19/42/1553316725038_460193919.jpg"; t3=qq; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1702174821; _ga_ETPBRPM9ML=GS1.2.1702174705.1.1.1702174820.49.0.0; Hm_Iuvt_cdb524f42f0cer9b268e4v7y735ewrq2324=rb5taJN4jXjZc7tSBEQkHNDJ2aRmMNxj','Referer': 'https://kuwo.cn/rankList','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','Secret': 'f1b6c63024e699d98cd436c1b1e8527a9ce1cdb90f538ef8f2698760e9071b0503035497','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36','sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}# 获取歌曲的播放地址
def get_play_url(song_id):# 请求时需要的参数params = {'mid': song_id,'type': 'music','httpsStatus': '1',# 'reqId': 'ff7eebd1-9706-11ee-bb7a-9939365fab80','plat': 'web_www','from': '',}# 设置最大尝试次数,因为有时候网络连接不稳定可能会请求不到数据,需要重试max_try = 3for i in range(max_try):try:response = requests.get('https://kuwo.cn/api/v1/www/music/playUrl',params=params, cookies=cookies, headers=headers)code = response.json()['code']breakexcept:code = -1time.sleep(1)if code == 200:play_url = response.json()['data']['url']else:play_url = ""return play_url# 获取歌曲的歌曲名,歌手名,歌曲id的信息
def get_song_info(page):# 请求时需要的参数params = {'bangId': '93','pn': page,'rn': '20','httpsStatus': '1',# 'reqId': 'e8516040-9702-11ee-bb7a-9939365fab80','plat': 'web_www','from': '',}response = requests.get('https://kuwo.cn/api/www/bang/bang/musicList',params=params, cookies=cookies, headers=headers)music_list = response.json()['data']['musicList']for music in music_list:singer = music['artist']song_name = music['name']song_id = music['rid']play_url = get_play_url(song_id)# print(singer, song_name, song_id, play_url)# 判断播放地址是否不为空if play_url:song_content = requests.get(url=play_url, headers=headers,cookies=cookies).content# 保存歌曲的二进制数据,以"歌曲名称-歌手名"的命名方式保存with open(f'data/{song_name}-{singer}.mp3', 'wb') as f:f.write(song_content)print(f'已下载------{song_name}\n')else:# 播放地址为空时输出以下内容print(f'{song_name} 为付费内容,请下载酷我音乐客户端后付费收听!\n')time. Sleep(1)4.效果展示
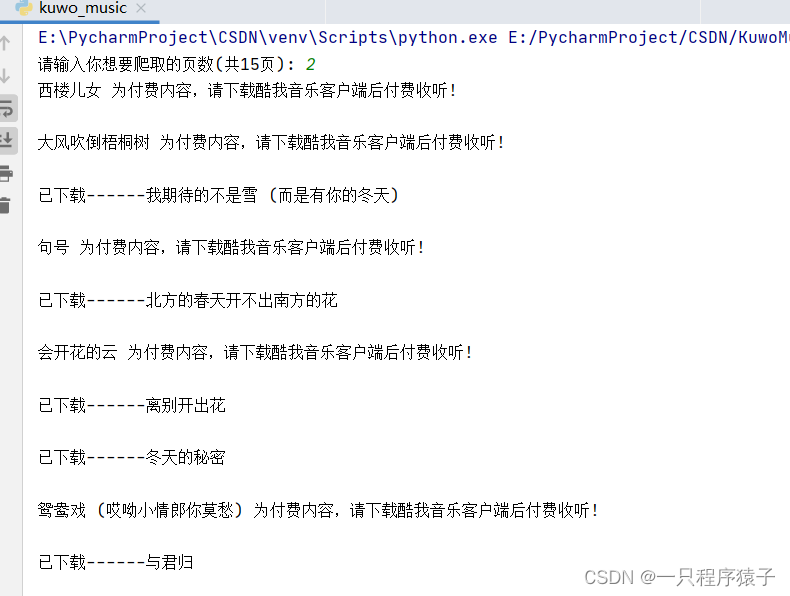
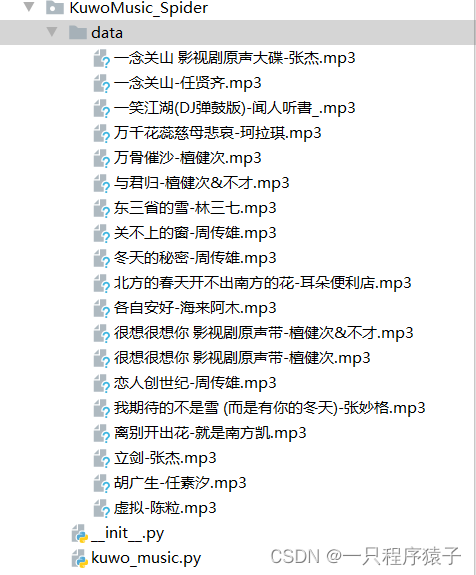
缺点: 有些歌需要vip账号才能获取到播放地址,建议用vip账号的cookies爬取!
优点: 凡是可以下载的歌都是完整版的,和某狗的一分钟试听不同!
注意:本教程仅供学习交流!
这篇关于Python爬取酷我音乐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








