取虎专题

nodeJS爬虫-爬取虎嗅新闻
1.安装依赖库到本地,需要的库有:安装方法见Node.js笔记说明 const superagent = require('superagent');const cheerio = require('cheerio');const async = require('async');const fs = require('fs');const url = require('url'

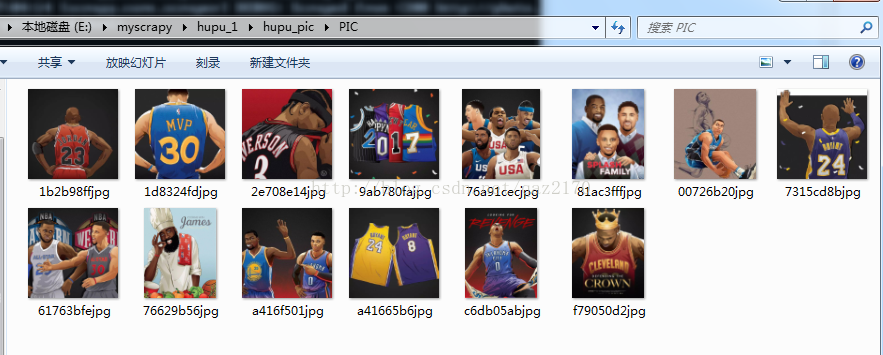
菜鸟用scrapy爬取虎扑图片
注意:以下代码是参考网上各路大神爬虫的代码,然后根据自己要爬的网站对代码进行修改,如有雷同,那必须是参考了您的代码。 转载请注明出处,谢谢!!!!! 一、首先,我们需要先装scrapy,可以参考http://www.cnblogs.com/txw1958/archive/2012/07/12/scrapy_installation_introduce.html这篇文章来安装,这里
![[python爬虫] Selenium定向爬取虎扑篮球海量精美图片](https://img-blog.csdn.net/20151025024227472)
[python爬虫] Selenium定向爬取虎扑篮球海量精美图片
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队、CBA明星、花边新闻、球鞋美女等等,如果一张张右键另存为的话真是手都点疼了。作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取。 前面讲过太多Python爬虫相关的文

利用BeautifulSoup库爬取虎扑湖区评论并且制作词云(二)
通过之前使用request库和BeautifulSoup库爬取得到了虎扑湖区前几页的帖子评论,接下里就要通过这些评论来制作词云。 1利用中文分词库jieba来分词 要想从评论中获取话题热度最高的词汇,我们需要将这些评论分成一个个的词汇,中文分词不像英文那般简单,还好jieba为我们提供了这样的功能。 首先通过pip安装jieba库,管理员权限打开cmd,输入pip install jieba ji

python爬取网页数据 ajax_python 爬取虎嗅网-post方法抓取ajax动态页面(上)
一、分析背景: 1,为什么要选择虎嗅 「关于虎嗅」虎嗅网创办于 2012 年 5 月,是一个聚合优质创新信息与人群的新媒体平台。 2,分析内容 分析虎嗅网 5 万篇文章的基本情况,包括收藏数、评论数等; 发掘最受欢迎和最不受欢迎的文章及作者; 分析文章标题形式(长度、句式)与受欢迎程度之间的关系; 展现近些年科技互联网行业的热门词汇 3,分析工具: python3.6 scra
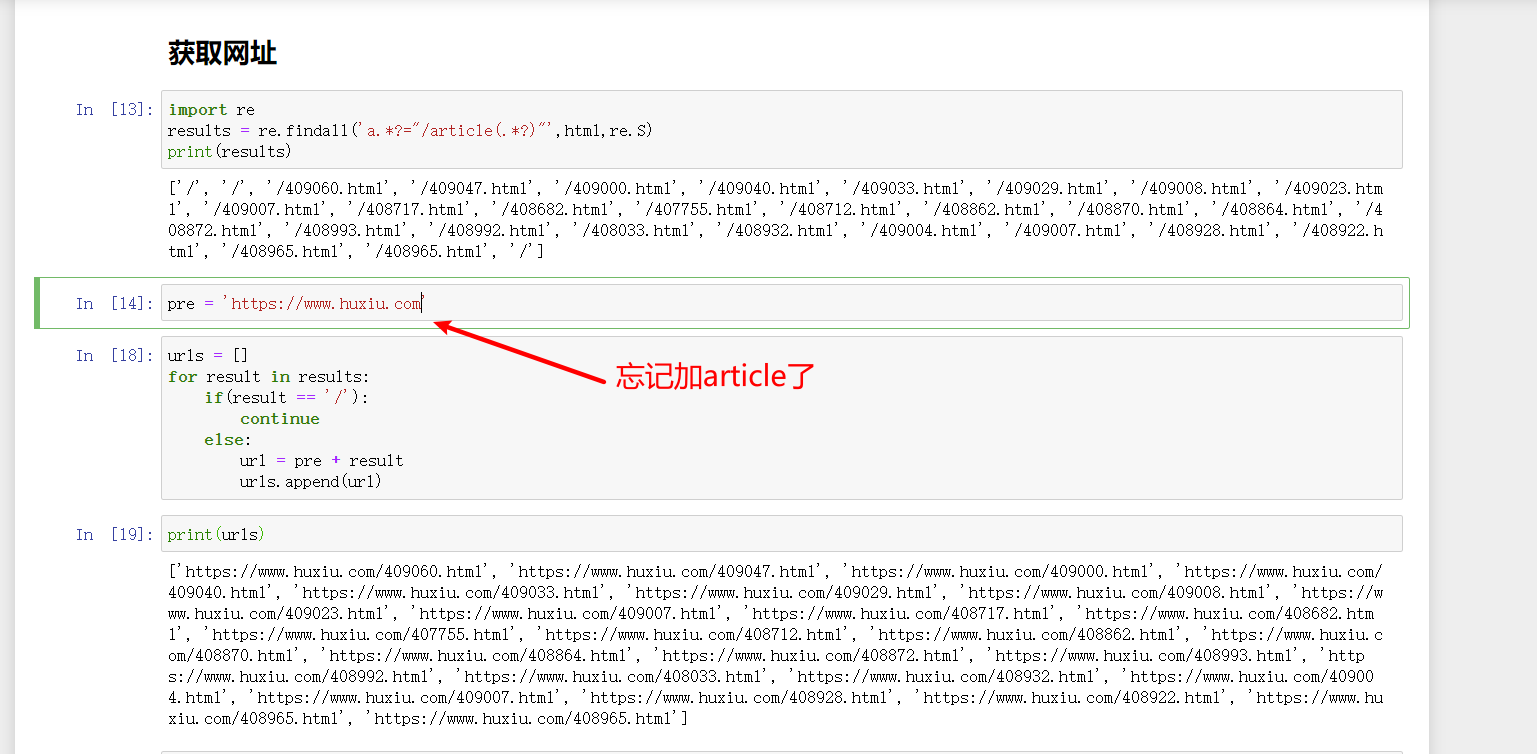
python爬取虎嗅网首页新闻超链接、图片链接、标题
要求:爬取该网站首页内容,即获取每一个超链接、图片链接、标题,以.CSV存储(一行就是一个新闻的超链接、图片链接、标题) 文章目录 用不上的思考过程正文1.观察新闻页面源码2.编写代码提取信息3.观察首页源码并编写正则表达式 源码 建议直接点正文👆 用不上的思考过程 1.新闻超链接存在于a的herf属性中,/article/408795.html,前面要加上https: