本文主要是介绍菜鸟用scrapy爬取虎扑图片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载请注明出处,谢谢!!!!!
一、首先,我们需要先装scrapy,可以参考http://www.cnblogs.com/txw1958/archive/2012/07/12/scrapy_installation_introduce.html这篇文章来安装,这里就不细说了。
二、安装成功之后,打开cmd命令行,输入:scrapy startproject hupu_pic,创建自己的scrapy项目
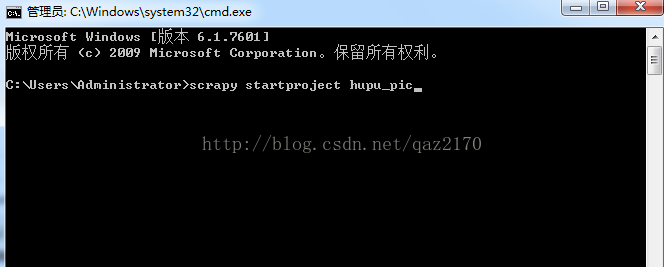
三、创建成功之后,我们可以看到hupu_pic这个项目里面的框架。PS:spiders文档里面的hupu_spdier.py这个文件这个是要自己另外创建的
四、建好之后我们就可以开始写代码了,首先,先确定我们要爬的网站地址,我选择的是虎扑篮球里的一个图片网址:http://photo.hupu.com/nba/p33886.html
1、打开items.py
# -*- coding: utf-8 -*-
import scrapyclass HupuPicItem(scrapy.Item):# define the fields for your item here like:
# name = scrapy.Field()
hupu_image_url = scrapy.Field()
创建一个Field用于存储图片url
2、打开settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'hupu_pic'
SPIDER_MODULES = ['hupu_pic.spiders']
NEWSPIDER_MODULE = 'hupu_pic.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {'hupu_pic.pipelines.HupuPicPipeline': 1,
}
IMAGES_STORE = 'E:\myscrapy\hupu_1\hupu_pic'
IMAGES_EXPIRES = 90
PS:一定要注意,爬虫的话一定要在settings.py中加上USER_AGENT语句,作用是模拟浏览器访问,如果不加的话会被网站拒绝;
ROBOTSTXT_OBEY = False 这个语句必须改为False,True的话会下载不了图片
3、在spiders文档下新建hupu_spider.py,需要说明的是,我自己写了两种方法,第一种是只爬取当前图片集,
第二种是抓取网站的翻页标签,一直爬下去,直到在cmd命令行按CTRL+C,令代码停止为止。
我们可以先看下网页标签,我用的是Chrome浏览器,按F12就可以看到我们想看到的网页代码,现在我们可以看下要爬的图片的标签是在什么地方:
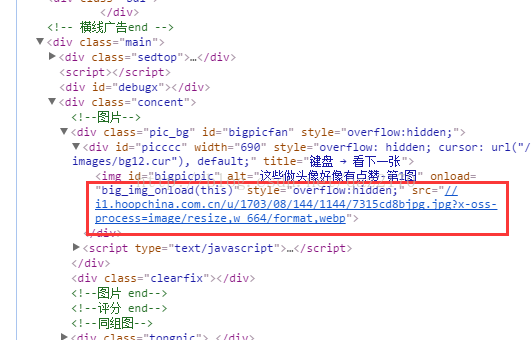
可以看到src属性就是我们要爬的目标,因此,用xpath语句选出scr元素,下面就看下代码。
第一种 hupu_spider.py:
from scrapy.spiders import CrawlSpider,Rule
from scrapy.selector import Selector
from scrapy import Request
from scrapy.linkextractors import LinkExtractorfrom hupu_pic.items import HupuPicItemclass HupuPicSpider(CrawlSpider):name = 'hupu_pic_spider'
allowed_domains = []download_delay = 1
start_urls = ['http://photo.hupu.com/nba/p33886.html'
]rules = (Rule(LinkExtractor(allow=('http://photo.hupu.com/nba/p33886-\d+.html')), callback='parse_item'),)def parse_item(self, response):sel = Selector(response)image_url = sel.xpath('//div[@id="picccc"]/img[@id="bigpicpic"]/@src').extract()print 'the urls:\r\n'
print image_urlprint '\r\n'
item = HupuPicItem()item['hupu_image_url'] = image_urlyield item上面代码中name的名字必须唯一,稍后我们启动爬虫的时候用到的就是这个名字。
allowed_domains是我们限定的爬虫区域网址,这里就为空,不做限制。
star_urls是我们开始爬虫的网址,必须是dic,因此要加上[]。
rules是制定的一个规则,可以看到allow中就是我们要求遵守的规则,可以看到我们不断翻页,网址中只有p33886-X在变化,
因此写了个正则表达式来爬这一图集下的所有图片。
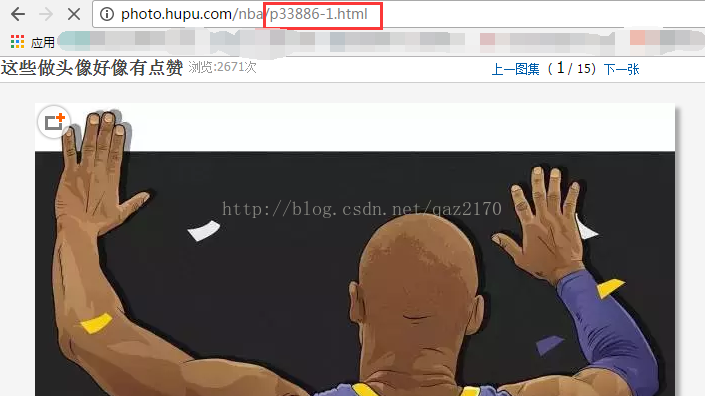
parse_item函数中image_url就是通过xpath语句选取src元素,而爬取出来图片的网址。
第二种 hupu_spider.py:
from scrapy.spiders import CrawlSpider,Rule
from scrapy.selector import Selector
from scrapy import Request
from scrapy.linkextractors import LinkExtractorfrom hupu_pic.items import HupuPicItemclass HupuPicSpider(CrawlSpider):name = 'hupu_pic_spider'
allowed_domains = []download_delay = 1
start_urls = ['http://photo.hupu.com/nba/p33886.html'
]rules = (Rule(LinkExtractor(allow=('http://photo.hupu.com/nba/p33886.html')), callback='parse_item'),)def parse_item(self, response):sel = Selector(response)image_url = sel.xpath('//div[@id="picccc"]/img[@id="bigpicpic"]/@src').extract()print 'the urls:\r\n'
print image_urlprint '\r\n'
item = HupuPicItem()item['hupu_image_url'] = image_urlyield itemnew_url = sel.xpath('//span[@class="nomp"]/a[2]/@href').extract_first()print 'new_url:\r\n', new_urlprint '\r\n'
if new_url:yield Request('http://photo.hupu.com/nba/' + new_url, callback=self.parse_item)而第二种代码是通过抓取翻页标签,来实现图片的爬取,这个方法可以一直爬下去,直到图片爬完或者手动cmd命令行按CTRL+C来停止爬取。
可以看到,我们要抓取的翻页标签href元素如图所示:
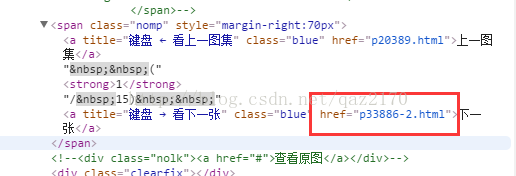
new_url就是我们选取翻页标签元素的url,然后通过Request来响应我们抓取的url。PS:注意,不知道是虎扑的网站是不是故意设计成这样,我们抓到的url是p33886-2.html,但是如果我们直接用这个抓取的url,是会报错的,因此我们在Request语句中要加上前缀,'http://photo.hupu.com/nba/'+ new_url,这个是我之前被坑了的地方,希望大家注意。
4、pipelines.py
# -*- coding: utf-8 -*-
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy import Requestclass HupuPicPipeline(ImagesPipeline):def file_path(self, request, response=None, info=None):image_guid = request.url.split('/')[-1]return 'PIC/%s' % (image_guid)def get_media_requests(self, item, info):for image_url in item['hupu_image_url']:image_urls = 'http:' + image_urlyield Request(image_urls)def item_completed(self, results, item, info):image_paths = [x['path'] for ok, x in results if ok]if not image_paths:raise DropItem('图片未下载好 %s' % image_paths)
PS:这里要注意,因为抓取下来的url是没有前缀'http:',因此我们要自己加上,不然爬取会失败
file_path函数作用是返回图片的原格式和原名字
get_media_request函数作用是从字典item中取出我们抓到的url,然后返回响应的url图片地址
item_completed函数作用是如果爬取某个图片失败,会提示‘图片未下载好’
现在我们就可以开始运行爬虫了,在cmd命令行输入scrapy crawl hupu_pic_spider
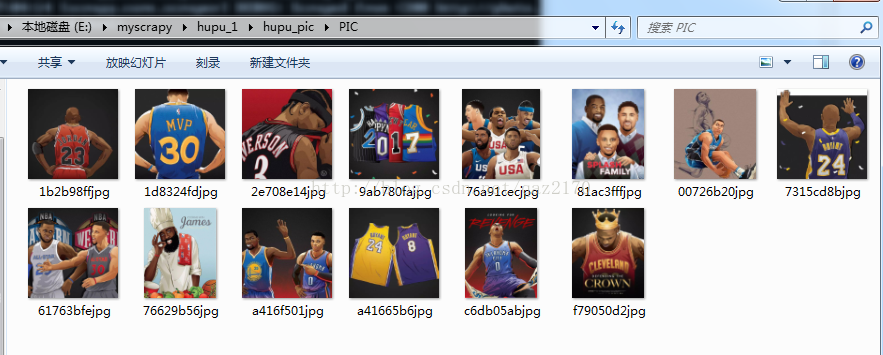
上面就是我用第二种hupu_spider.py方法爬到的图片,因此我只是爬了10几张就被我中断了,有意愿的童鞋可以一直爬下去试下。
代码就是以上这些,上面都是根据我自己遇到的一些问题,然后整理出来的东西,其实主要是写给我自己看的,由于是第一次写博客,写的不好的地方望指出,谢谢!
这篇关于菜鸟用scrapy爬取虎扑图片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




