副本专题

副本技能-Amazon开放平台MWS的API接入
Amazon官方工具各类地址 亚马逊订单提供接口调试地址: https://mws.amazonservices.com/scratchpad/index.html 亚马逊MWS 端点及MarketplaceId查询地址: http://docs.developer.amazonservices.com/zh_CN/dev_guide/DG_Endpoints.html 亚马逊MWS官方开发者文

副本技能-maven打包仓库常用配置与上传指定制品仓库
1.找到本地Maven的配置文件settings.xm 2.配置setting文件中的服务器远程仓库地址 <servers><!-- 正式包仓库 --><server><id>xt-releases</id><username>UTmQqF</username><password>******</password></server><!-- 开发中的镜像包仓库 --><server><id>x

副本技能-亚马逊SP-API的依赖SDK包生产
1.环境配置 需求:Java环境,Maven环境,均需配置环境变量(可自行百度)! 2.下载api的接口模块代码 selling-partner-api-models项目GitHub库 3.下载 Swagger 代码生成器 Swagger代码生成器下载地址 自己找个目放着就好 4.查找SDK的配置JSON文件 SDK的接口配置JSON路径:selling-partner-api-mo

副本技能-使用RabbitMQ做即时消息通讯,使用STOMP协议
1.消息通讯的基础环境 技术使用: 后端使用Spring Websocket通讯,前端使用SocketJS,非长连接,有心跳检测信息交互使用RabbitMQ的插件Stomp 给RabbitMQ安装Stomp的插件 安装前: 安装后: 安装步骤(我的RabbitMQ是使用的Docker) 1.进入Docker容器RabbitMQ的后台(docker exec -it 容器ID /bin

副本技能-Ebay系统对接获取Token【多店铺版本】
流程逻辑: 1.使用ebay配置获取多店铺的授权连接 2.在页面访问多店铺的授权链接 3.确定授权链接,后端获取店铺访问的token 1.调用自身的服务获取店铺授权链接 https://[访问地址]/ebay/[应用ID]/getEbayShopAuthUrl/[店铺名称] 2.页面授权多店铺链接 相同的链接,后面店铺名称修改不同,进入页面授权即可 查看返回结果:自己写的代码,格式可以

副本技能-eBay店铺指标调用评论限制
参考资料 eBay API 支持大量应用程序,但是eBay 限制了 API 调用的使用。总调用数限制和调用速率取决于不同的 API。 默认的 API 速率限制是为个人和小型企业设计的。如果您的数量增加,您可以在完成eBay的兼容应用程序检查流程后获得更多的调用次数 。 API 调用使用报告,可以获知当前的每日限额和每日调用量。对于限制, 一天 从太平洋时间 00:00:00(午夜)【北京时间:1

Vue 3 Composition API 中如何正确添加表单项副本到数组
在 Vue 3 中,使用 Composition API 时,如果你尝试直接通过引用(如 formState)来填充 formList 数组,你会遇到一个问题:所有通过 addForm 方法添加的表单项实际上都是对 formState 的同一个引用。这意呀着,如果你修改了任何一个表单项,所有其他通过 formState 添加的表单项也会同时被修改,因为它们实际上都是指向同一个对
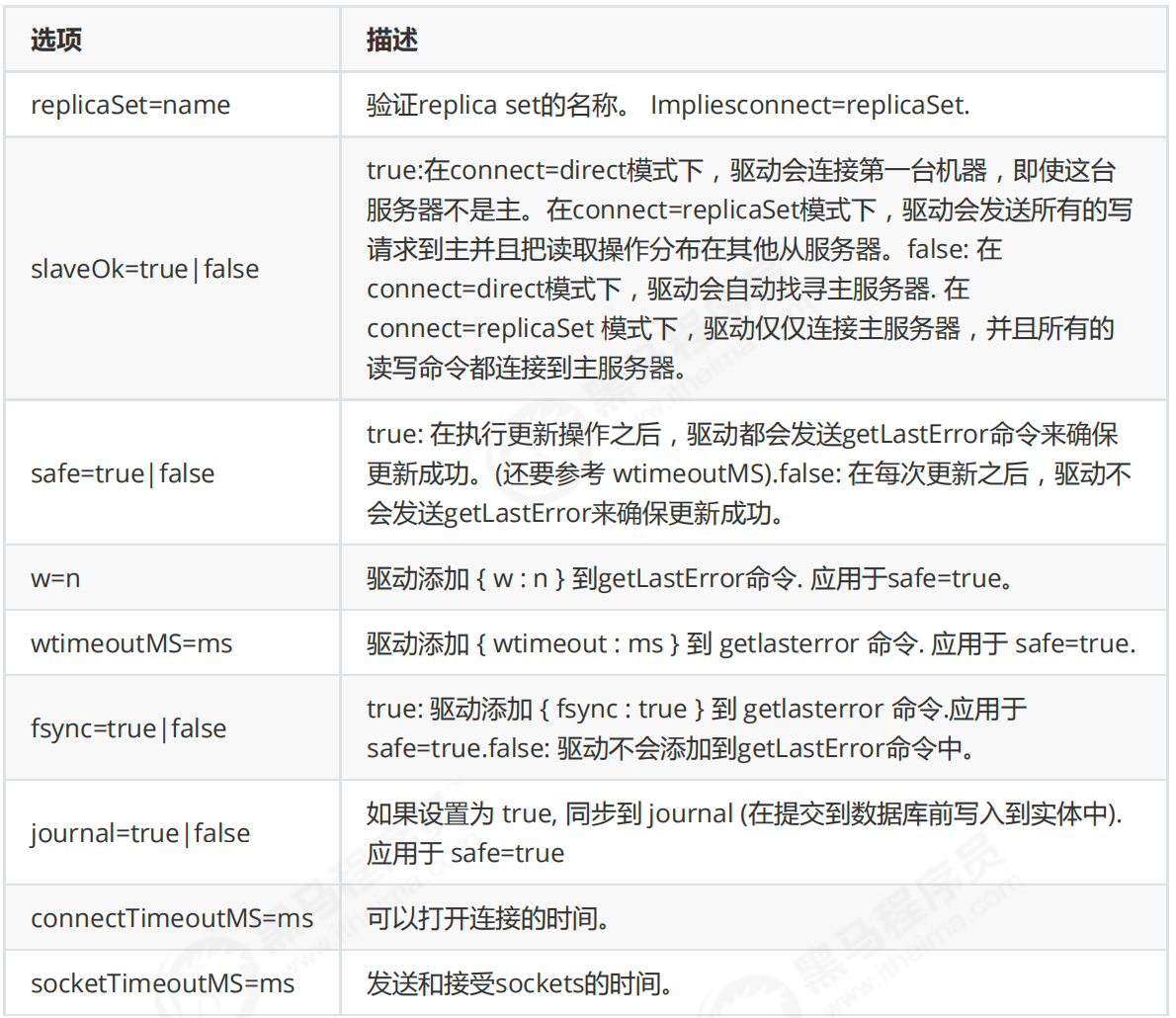
MongoDB-副本集-Replica Sets
(一) 副本集-Replica Sets 1. 简介 MongoDB中的副本集(Replica Set)是一组维护相同数据集的mongod服务。 副本集可提供冗余和高 可用性,是所有生产部署的基础。也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异步同步,从而使多台机器拥有同一数据的多个副本,并且当主库当掉时在不需要用户干预的情况下自动切换其他备份服务

vue学习七(v-for数组和对象、v-if、监测索引值、监测对象属性增删、副本、组件v-for)
文章目录 用 v-for 将数组对应为一组元素一个对象的 v-forkey复用数组利用索引设置项值对象属性的添加或删除显示过滤/排序结果v-for on a templatev-for with v-if组件v-for 用 v-for 将数组对应为一组元素 在 v-for 块中,我们拥有对父作用域属性的完全访问权限。v-for 还支持一个可选的第二个参数为当前项的索引

HDFS介绍(四)HDFS副本存放策略(转)
转自:https://blog.csdn.net/lb812913059/article/details/78713467 数据分块存储和副本的存放,是保证可靠性和高性能的关键 将每个文件的数据进行分块存储,每一个数据块又保存有多个副本。这些数据块副本分布在不同的机器节点上 设置备份数 方法一:配置文件hdfs-site.xml <property>

Kafka 不同步的副本首领选举探究
测试版本模拟场景测试结果相关建议 测试版本 kafka 1.1.1 模拟场景 依次挂掉集群每一台机器,但是中间不间断发消息,然后按照挂掉的顺序依次重启 测试程序采用每10s发送一批消息,在中间停顿这10s有序停止副本。然后再顺序重启 测试结果 如果启动的是未同步的副本,那么集群就不会处理生产者和消费者的请求。 因为在0.11版本默认改为关闭不完全副本首领选举。需要

ClickHouse分布式部署搭建单分片二副本集群
搭建单分片二副本集群,使用MergeTree引擎测试数据同步 服务器: 127.0.0.1 clickhouse 127.0.0.2 clickhouse + keeper 结构图 1.修改hosts vi /etc/hosts 添加需要部署的ip和名字 127.0.0.1 node1127.0.0.2 node2 2. node1配置文件修改 2.1 修改/etc/

Kakfa的核心概念-Replica副本(kafka创建topic并指定分区和副本的两种方式)
Kakfa的核心概念-Replica副本(kafka创建topic并指定分区和副本的两种方式) 1、kafka命令行脚本创建topic并指定分区和副本2、springboot集成kafka创建topic并指定分区和副本2.1、springboot集成kafka2.1.1、springboot集成kafka创建topic并指定5个分区和1个副本2.1.2、往分区中发送消息2.1.3、sprin

CDH修改HDFS以及存储的副本数量由备份3到备份2
首先第一个问题,我们修改CDH的HDFS副本设置后,历史的备份3数据是否会删除,还是从设置后才开始遵守备份2的?都需要操作哪些? 好的,我们带着问题来具体操作一下; 1.首先在CDH,HDFS中配置找到复制因子(dfs.replication),如下: 将原有dfs.replication的值 3 改为 2。 2.然后所有服务列表会出现如下显示: 3.我们只需要点击随意的一个fl

瑞_MongoDB_MongoDB副本集
文章目录 1 MongoDB副本集-Replica Sets1.1 简介1.2 副本集的三个角色1.3 副本集架构目标1.4 副本集的创建1.4.1 创建主节点1.4.2 创建副本节点1.4.3 创建仲裁节点1.4.4 初始化配置副本集和主节点1.4.5 查看副本集的配置内容 rs.conf()1.4.6 查看副本集状态1.4.7 添加副本从节点1.4.8 添加仲裁从节点 1.5 副本集的数
docker搭建mongo副本集
1、mongo集群分类 MongoDB集群有4种类型,分别是主从复制、副本集、分片集群和混合集群。 MongoDB的主从复制是指在一个MongoDB集群中,一个节点(主节点)将数据写入并同步到其他节点(从节点)。主从复制提供了数据的冗余备份,并且可以实现高可用性和故障恢复。 副本集(Replica Set):副本集由一个主节点和多个从节点组成。主节点负责处理写入操作和数据同步,从节点负责处
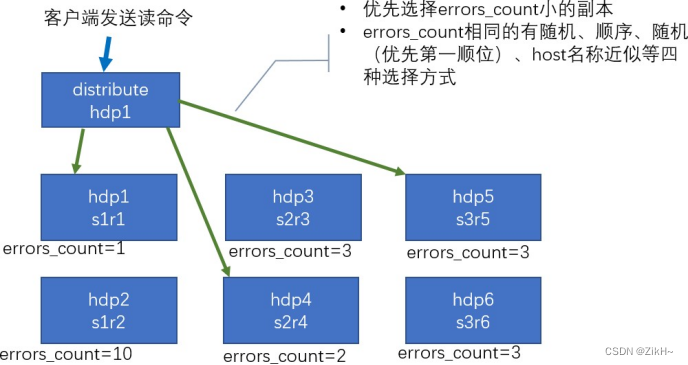
【ClickHouse】副本、分片集群 (六)
副本 副本的目的主要是保障数据的高可用性,即使一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据。 https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/ 副本写入流程 写入流程如图-18所示: 图-18 写入流程 配置步骤 1)启动zookeeper
数据库修复实例2(副本出入口修复)
修复目标 修复Bfa-5人副本出入口(Bfa 为 WOW 争霸艾泽拉斯版本) SET @OGUID := 7000316;SET @ATID := 69;SET @ATCP := 56;SET @ATIDSPAWN := 70;SET @SPAWNGROUP := 1251;SET @WORLDSAFELOCID := 100042;-- Adjust GameObjectsDEL

用paxos实现多副本日志系统--multi paxos部分
接下来,我们来讲解multi-paxos。大家应该还记得我们开始时提到的multi-paxos的目标是实现多副本log系统。要实现多副本log系统的一种方法就是,使用一组彼此独立的basic paxos实例,每个独立的basic paxos实例用来决定一系列log当中的一条。为了做到这一点,我们需要给Prepare和Accept两个rpc增加一个参数,index,用来表示这个basic

k8s学习--kubernetes服务自动伸缩之水平收缩(pod副本收缩)VPA策略应用案例
文章目录 前言应用环境1.VPA应用案例 updateMode: "Off"(1)创建应用实例(2)创建vpa 2.VPA应用案例 updateMode: "Auto"(1)创建应用 (2)创建vpa(3)执行压测 前言 有任何疑问或不懂的地方均可评论或私信,欢迎交流 关于VPA的详细解释 链接: VPA的详细解释 策略 在VPA中,updateMode 是一个重要的
MongoDB 部署副本集 + 代码中开启事务
首先,指定副本名称: vim /etc/mongod.conf replication:replSetName: shard1 在replication里面加入副本名称,多个相同副本,应该使用同样的名称 如果要修改mongodb占用的内存,可以这样设置: storage:wiredTiger:engineConfig:cacheSizeGB: 1 进入mongo客户端: mon

TortoiseSVN创建分支,创建项目副本
TortoiseSVN—>分支/标记 将从地址svn://119.119.119.119/snqk-information/password_error_lock原样复制到地支 svn://119.119.119.119/snqk-information/password_error_lock3,然后点击确定

HDFS的写入流程及副本复制策略
步骤补充 1.向namenode发送请求上传文件 然后在namenode里会进行检查是否存在该文件,权限问题 通过则给一个输出流对象 2.建立好pipeline管道后,客户端先把文件写入缓存中,达到一个块的大小时,会与第一个datanode建立连接开始流式的传输数据,这个datanode会一小部分一小部分的(4k)接受数据然后写入本地仓库,同时把这些数据传输到第二个datano

docker搭建mongo单机单节点副本集模式
1.先说问题 现有如下问题: 1.在springboot环境下,连接mongo,报如下错误: Caused by: com.mongodb.MongoCommandException: Command failed with error 20 (IllegalOperation): 'Transaction numbers are only allowed on a replica set

Apache IoTDB 分布式架构三部曲(三)副本与共识算法
IoTDB 首创并应用的共识协议统一框架,为用户提供了灵活选择不同共识算法的可能性。 对于一个分布式集群而言,为了使得海量数据场景下集群能够横向扩展,集群需要按照一定的规则将全部数据分成多个子集存储在不同的节点上,从而能够更加充分地利用到集群中各个节点的存算资源。对于集群中的任何一个分片而言,为了满足高可用的需求,需要将数据在多个物理节点上冗余存储多个副本,进而避免单点故障的出现。 由于同一份
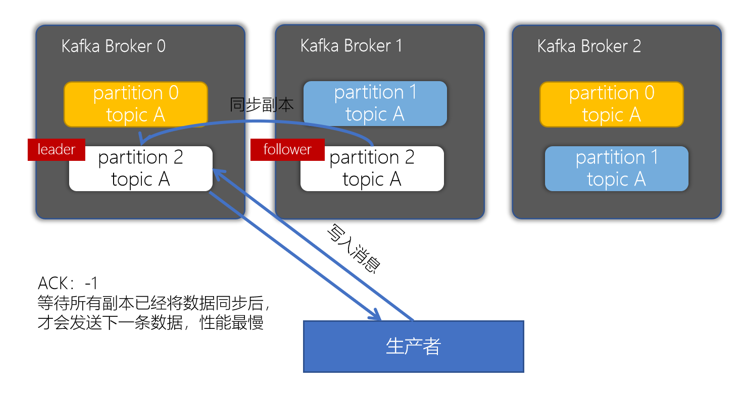
kafka的副本机制
目录 Producer的ACKs参数 配置 acks配置为0 acks配置为1 acks配置为-1或者all 副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的。 Producer的ACKs参数 对副本关系较大的是,producer配置的ack参数了,acks参数表示当生产者生产消息的时候写入到副本的