本文主要是介绍kafka的副本机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Producer的ACKs参数
配置
acks配置为0
acks配置为1
acks配置为-1或者all
副本的目的就是冗余备份,当某个Broker上的分区数据丢失时,依然可以保障数据可用。因为在其他的Broker上的副本是可用的。
Producer的ACKs参数
对副本关系较大的是,producer配置的ack参数了,acks参数表示当生产者生产消息的时候写入到副本的要求严格程度。它决定了生产者如何再性能和可靠性之间取舍。
配置
Properties props = new Properties();
props.put("bootstrap.servers", "node1.itcast.cn:9092");
props.put("acks", "all");
Properties props = new Properties();
props.put("bootstrap.servers", "node1.itcast.cn:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
acks配置为0
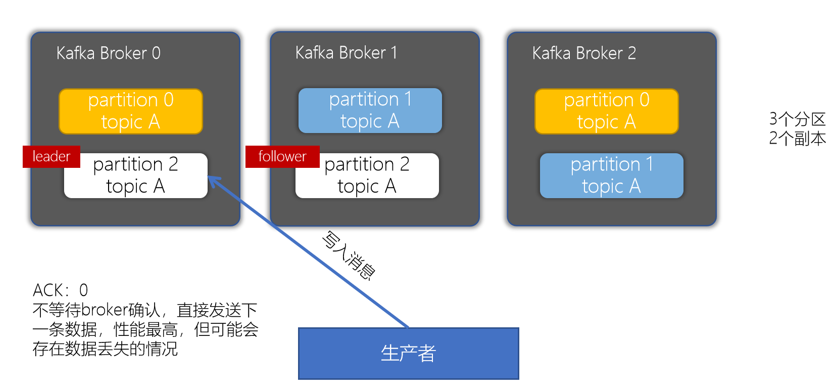
ack为0,表示发生消息不要等到broker确认,直接发送下一条数据,性能最高,但可能存在数据丢失的情况。
acks配置为1

当生产者的ACK配置为1时,生产者会等待leader副本确认接收后,才会发送下一条数据,性能中等。
acks配置为-1或者all
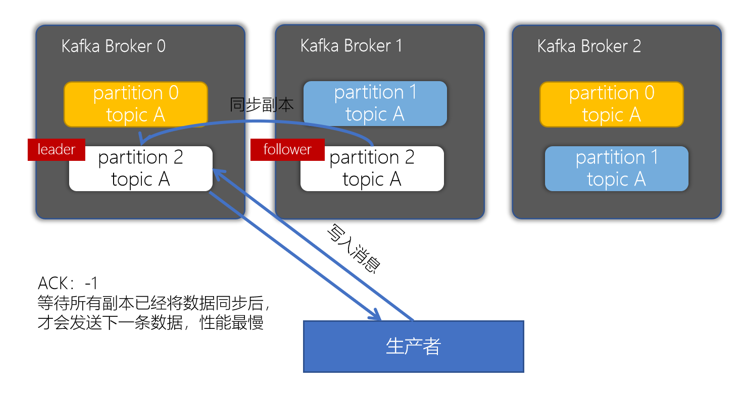
ack为-1,表示等待所有副本以及将数据同步后,才会发送下一条数据,性能最慢
这篇关于kafka的副本机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



