共线性专题

R语言统计分析——线性模型假设的综合验证与多重共线性
参考资料:R语言实战【第2版】 1、线性模型假设的综合验证 gvlma包中的gvlma()函数,能对线性模型进行综合验真,同时还能做偏斜度、峰度和异方差性的评价。也就是说,它给模型提供了一个单独的综合验证(通过/不通过)。 # 加载gvlma包library(gvlma)# 获取数据states<-as.data.frame(state.x77[,c("Murder",
「JCVI教程」如何绘制CNS级别的共线性图(中)
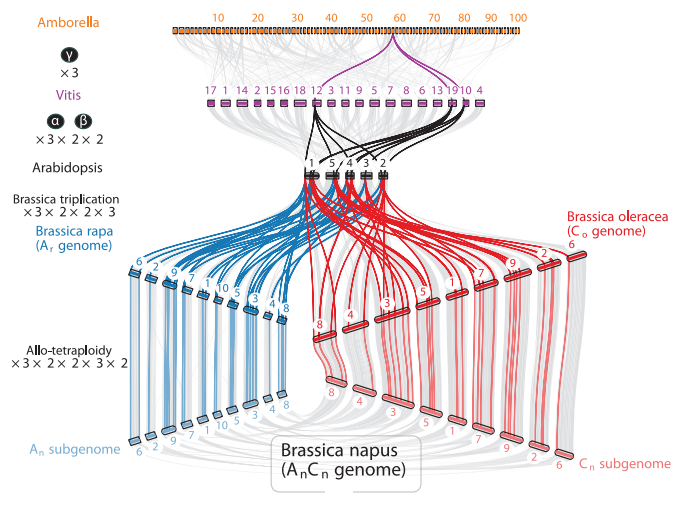
在「JCVI教程」编码序列或蛋白序列运行共线性分析流程(上)还是有一个尴尬的事情,就是只用到两个物种,不能展示出JCVI画图的方便之处,因此这里参考https://github.com/tanghaibao/jcvi/wiki/MCscan-(Python-version)的分析,只不过画图部分拓展下思路。 首先要运行如下代码获取目的数据 python -m jcvi.apps.fetch p

「JCVI教程」如何绘制CNS级别的共线性图(上)
本教程借鉴https://github.com/tanghaibao/jcvi/wiki/MCscan-(Python-version). 我们先从http://plants.ensembl.org/index.html选择两个物种做分析, 这里选择的就是前两个物种,也就是拟南芥和水稻(得亏没有小麦和玉米) 选择物种 我们下载它的GFF文件,cdna序列和蛋白序列 #A
如何用WGDI进行共线性分析(二)
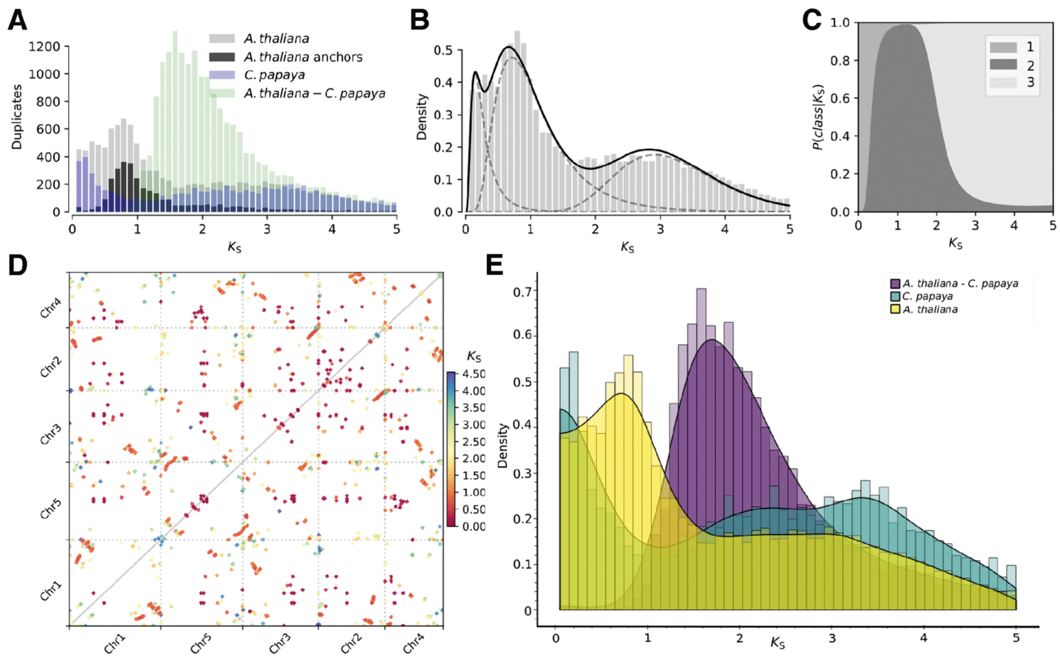
Ks可视化 我们在上一篇如何用WGDI进行共线性分析(一)得到共线性分析结果和Ks值输出结果的整合表格文件后,我们就可以绘制Ks点阵图和Ks频率分布图对共线性区的Ks进行探索性分析,从而确定可能的Ks峰值,用于后续分析。 Ks点阵图 最初绘制的点图信息量很大,基本上涵盖了历史上发生的加倍事件所产生的共线性区。我们能大致的判断片段是否存在复制以及复制了多少次,至于这些片段是否来自于同一次加倍事件则

如何用WGDI进行共线性分析(上)
多倍化以及后续的基因丢失和二倍化现象存在于大部分的物种中, 是物种进化的重要动力。如果一个物种在演化过程中发生过多倍化,那么在基因组上就会存在一些共线性区域(即两个区域之间的基因是旁系同源基因,其基因的排布顺序基本一致)。 例如拟南芥经历了3次古多倍化,包括2次二倍化,一次3倍化 (Tang. et.al 2008 Science). ..For example, Arabidopsis th

Python统计实战:一题搞定多元线性回归、共线性、相对重要性分析
为了解决特定问题而进行的学习是提高效率的最佳途径。这种方法能够使我们专注于最相关的知识和技能,从而更快地掌握解决问题所需的能力。 (以下练习题来源于《统计学—基于Python》。联系获取完整数据和Python源代码文件。) 练习题 为了分析影响不良贷款的因素,一家商业银行在所属的多家分行中随机抽取25家,得到的不良贷款、贷款余额、应收贷款、贷款项目个数、固定资产投资等有关数据如下(前3行

R语言-数据预处理的一些实用(万能)办法:缺失值、数据重复、共线性等等的处理
#在这里呢主要是想介绍一下数据预处理的一些常用问题:缺失值、数据重复、共线性等等的处理办法,自己写了一点代码,希望能帮助到有需要的朋友 #删除缺失比例达到20%的列,并打印出删除的列 fun1<-function(data,naratio=0.2){ na_ratio<-apply(is.na(data),2,sum)/nrow(data)#求每列的缺失比例 x<-data
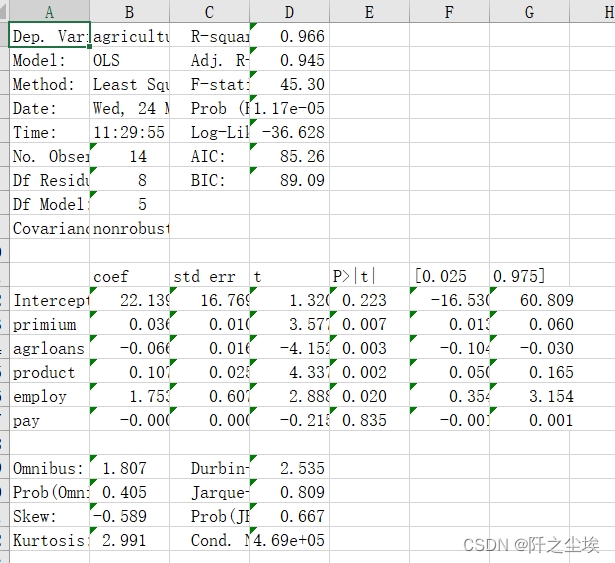
Python数据分析案例35——多元线性回归全流程 (数据探索可视化,回归分析,多重共线性,残差检验,异方差检验,自相关检验)
案例背景 很多经济学同学用Python做传统统计学的回归分析时可能没有R或者Stata,Eviews,SPSS方便,他们对回归分析里面常用的检验过程不熟悉。 Python做回归这些当然没有这些统计学,计量经济学常用的软件方便,但是都能做,只是没有人总结一个系统的完整的回归分析的流程。他们做回归往往忽略了,传统统计学还需要做的多重共线性的检验,残差检验,异方差检验,自相关检验等等。 本次案例就

多重共线性的处理方法(转载)
(一)删除不重要的自变量 自变量之间存在共线性,说明自变量所提供的信息是重叠的,可以删除不重要的自变量减少重复信息。但从模型中删去自变量时应该注意:从实际经济分析确定为相对不重要并从偏相关系数检验证实为共线性原因的那些变量中删除。如果删除不当,会产生模型设定误差,造成参数估计严重有偏的后果。 (二)追加样本信息(不过实际操作中,这个方法实现率不高) 多重共线性问题的实质是样本信息的不充分而导

风控建模 数据对照篇:WOE IV 回归系数 P值 相关系数 共线性指标 膨胀因子 KS AUC GINI PSI
最重要的事情开始都会讲:建模是始终服务于业务的,没有业务的评分卡就没有灵魂 每一个指标段对应的评价如下,就当做各位的参考表数据吧。希望可以对大家有帮助 第一部分 指标图表以及英文简介 第二部分 指标对应参考数据 需要说明的是,由于对应的目标客群不同,可能各个指标所提供标准不同,可能银行和小贷公司对于KS的标准不相同,银行相对严格,小贷公司可能包含其余的策略性规则,因此可能KS相对比较小
应用回归分析:多重共线性
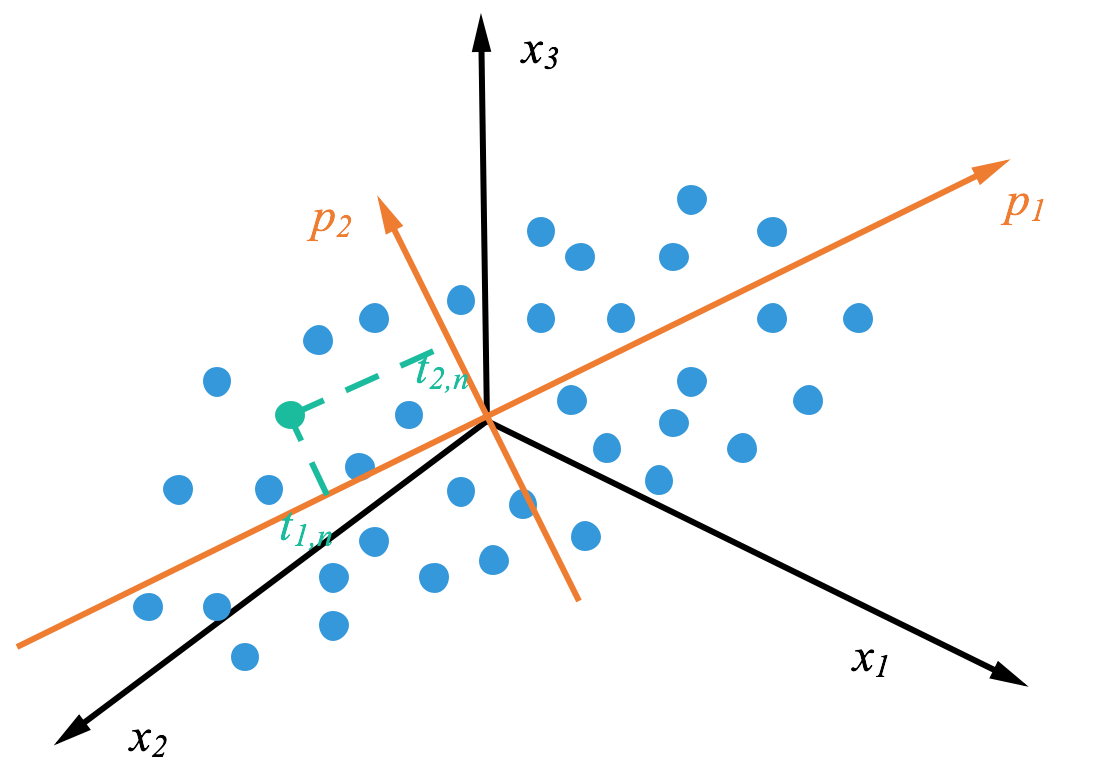
多重共线性的概念 在回归分析中,我们通常关注的是如何利用一个或多个自变量(解释变量)来预测一个因变量(响应变量)。当我们使用多元线性回归模型时,理想的情况是模型中的每一个自变量都能提供独特的、对因变量有用的信息。然而,如果两个或两个以上的自变量之间存在强烈的线性关系,就会出现多重共线性的问题。 识别多重共线性 识别多重共线性通常可以通过以下几种方法: 方差膨胀因子(VIF): VIF测
2017.06.06回顾 三种构造dataframe的方法 多重共线性开坑
1、和星期一上午一样的问题,就是精神不好,打瞌睡,我后面的主要工作就是把注册信息变量提取整理做到建模表中,上午还日常看了下股票,亏得他妈一塌糊涂 2、下午一来就是继续v7的开发,关于上一个工作日的两个list合成dataframe的方法,我觉得是存在问题,感觉到太繁琐了,我于是查了下资料,我震惊了,原来那么简单,我并且根据这个总结了三种不同的构造dataframe的方法 #三种构造data

另眼看待变量间多重共线性
多重共线性是使用回归算法时经常要面对的一个问题。在其他算法中,例如决策树和Naïve Bayes,前者的建模过程是逐步递进,每次拆分只有一个变量参与,这种建模机制含有抗多重共线性干扰的功能;后者干脆假定变量之间是相互独立的,因此从表面上看,也没有多重共线性的问题。但是对于回归算法,不论是一般回归,逻辑回归,或存活分析,都要同时考虑多个预测因子,因此多重共线性是不可避免需要面对的。而在营销数据中,多

异方差与多重共线性对回归问题的影响
异方差的检验 1.异方差的画图观察 2.异方差的假设检验,假设检验有两种,一般用怀特检验使用方法在ppt中,课程中也有实验,是一段代码。 异方差的解决办法 多重共线性 多重共线性可能带来的影响: 多重共线性的检验 多重共线性的处理方法: 一般也是直接删除 或者使用 不要轻易使用逐步回归,因为剔除
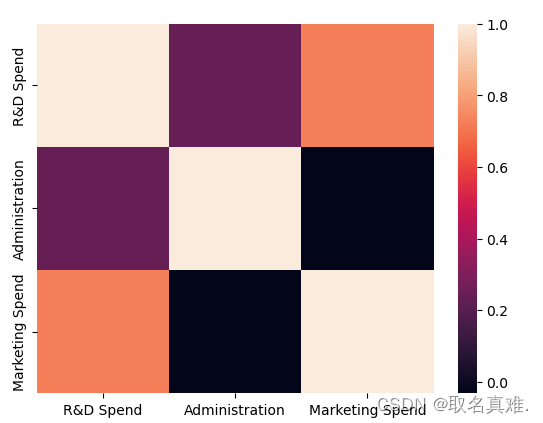
Linear Regression多重共线性
目录 介绍: 一、 corr 二、pairplot 三、VIF 3.1自带vif 3.2自定义函数vif 四、heatmp(直观感受) 介绍: 多重共线性是指在线性回归模型中,自变量之间存在强相关性或线性关系,从而导致模型的稳定性和可解释性受到影响。 在线性回归中,我们希望自变量与因变量之间有一定的线性关系,且自变量之间尽可能不相关,这样可以更好地解释因变量的变化。然而
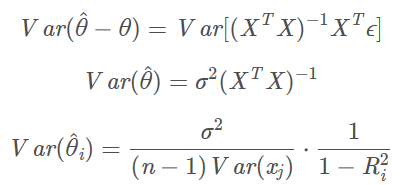
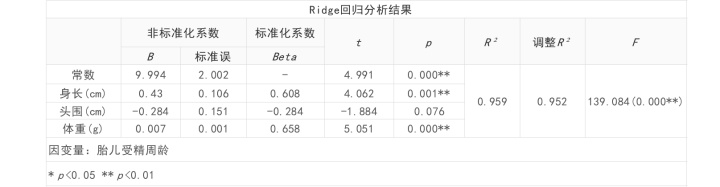
评价最小二乘法回归模型的优劣用什么方法?_解决多重共线性之岭回归分析
上篇文章,我们介绍了几种处理共线性的方法。比如逐步回归法、手动剔除变量法是最常使用的方法,但是往往使用这类方法会剔除掉我们想要研究的自变量,导致自己希望研究的变量无法得到研究。因而,此时就需要使用更为科学的处理方法即岭回归。 岭回归 岭回归分析(Ridge Regression)是一种改良的最小二乘法,其通过放弃最小二乘法的无偏性,以损失部分信息为代价来寻找效果稍差但回归系数更符合实际情