本文主要是介绍特征共线性问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多重共线性是使用线性回归算法时经常要面对的一个问题。在其他算法中,例如决策树或者朴素贝叶斯,前者的建模过程时逐渐递进,每次都只有一个变量参与,这种机制含有抗多重共线性干扰的功能;后者假设变量之间是相互独立的。但对于回归算法来说,都要同时考虑多个预测因子,因此多重共线性不可避免。
多重共线性(Multicollinearity)是指线性回归模型中的自变量之间由于存在高度相关关系而使模型的权重参数估计失真或难以估计准确的一种特性,多重是指一个自变量可能与多个其他自变量之间存在相关关系。
1. LR中的共线性问题和解决方法
假设k个自变量的多元线性回归模型:
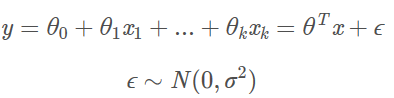
利用最小二乘法可得到参数的估计为:
![]()
如果X不是满秩的话,会有无穷多个解。如果变量之间存在共线性,那么X近乎是不满秩的,XTX近乎是奇异的。
从统计学的角度来看:
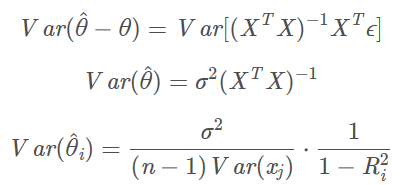
如果方差膨胀因子很大,也就是相关系数R趋向1的时候,方差就会变得异常大。
解决办法可以有:
- PCA等降维方法。因为在原始特征空间中变量之间相关性大,很容易想到通过降低维度的形式来去除这种共线性。
- 正则化。使用岭回归(L2)或者lasso回归(L1)或者elasticnet回归(L1+L2)
- 逐步回归法
特征共线性不影响模型的预测效果只要模型能够最终收敛,但是这个答案的前提假设是输入的数据是理想化的,不存在噪声的,然而实际应用工程中这是不太可能的,总会有一部分特征带有噪声,有可能是etl工程师的疏忽,有可能是数据来源受到了污染,这个问题在一些银行领域的业务中比较典型:
例如,现在许多银行系的金融科技子公司都开始渐渐使用一些机器学习的算法来对信贷风控进行建模,经常会涉及到对第三方数据的购买,我们假设从A、B、C三个渠道获取了3个特征,使用逻辑回归,标签为信用不良用户与信用优良用户的二分类问题,假设这个3个特征之间相关性很强,我们直接使用lr建模,模型收敛,通过oot,上线,嗯,第一个季度效果不错,到了第二个季度,模型需要进行迭代,结果A公司数据库工程师删库跑路了,A公司也没做备份,啥数据都拿不出来,得,这个月的A特征全是缺失值,模型不好迭代了,做个插补吧,误差太大,不做吧,又没法迭代,尴尬。 如果一开始考虑到特征之间相关性强的问题,删除了A、B这两特征留下C,那么这种问题的出现所带来的影响相对就要小的多了。
相关性强的特征如果同时建模,潜在的实际上是增大了模型受噪声干扰的面,还是上面强相关的A、B、C三个特征的例子,假设A、B、C三者收到噪声干扰的概率都是0.05,则当仅使用其中一个特征的时候,受到噪声干扰的概率为0.05,如果选择了3个特征,则受到噪声干扰的概率为1-0.95*0.95*0.95约为0.143,结果两种方案得到的模型的效果还差不多。
2. 为什么树模型对特征之间的共线性不强调呢?
在统计分析中,作推断时,如果自变量存在共线性,将无法区分它们对因变量的影响,因此无法对结果进行清楚的解释。但是有时候做预测(prediction)时,我们并不关心如何解释自变量对因变量的影响。GBDT、神经网络 也更像一个black-box,很适合做预测分析。(共线性不影响模型的预测而是影响对模型的解释),但是在一些特定的领域,比如金融,从业人员是非常强调模型的可解释性的,因为模型可解释就可以和从业人员的先验知识形成一个比较好的互补,从而提高模型的有效性。做预测时,往往用贪婪算法进行变量选择,只有新变量对结果影响比较大时,才会被加入到模型中,因此,在step-wise variable selection的过程中,共线性的变量只有一个会被选入到模型中。在决策树模型中,每一个树的构建都是贪婪的,因此,冗余的特征并不会被加入模型中,也就是说如果变量之间相关性非常强最终很可能只会选择部分进入模型。
3. 为什么会在训练的过程当中将高度相关的特征去掉?
- 去掉高度相关的特征会让模型的可解释性更好
- 可以大大提高训练的速度。如果模型当中有很多特征高度相关的话,就算损失函数本身收敛了,但实际上参数是没有收敛的,这样会拉低训练的速度。其次是特征多了,本身就会增大训练的时间。
- 用lgb来基于自身特征重要性做特征选择的时候,共线性是一个非常致命的问题,因为共线性会导致一些相关性高但是重要性高的特征在特征选择的过程中被排除掉,一开始是因为使用了特征重要性作为特征筛选的方法发现最终的泛化效果反而差了,最后仔细排查才发现了共线性的问题,因为有三个特征的相关性太高,训练的时候,每一颗树都是从这3个特征中随机选择一个,而选完了一个之后,另外两个由于相关度太高的问题,在下一次分裂的时候往往没有办法带来大的增益了(因为已经被选中的特征抢先分裂了),所以最终的结果就是,3个强大的特征最终的分裂次数或者分裂增益值都很小,看起来好像不是很重要的样子所以,在实际的过程中,还是建议要把特征相关性考虑进去,免得出现各种各样意想不到的幺蛾子。。。
- 最后一点的内容我在下面这幅图的段落中已经陈述过了,不要以为gbdt就可以为所欲为!
参考知乎:https://zhuanlan.zhihu.com/p/70124378?from_voters_page=true
这篇关于特征共线性问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








