tune专题

How to train openai model using fine tune in nodejs
题意: 如何在 Node.js 中使用微调来训练 OpenAI 模型 问题背景: I need to train my openai model using nodejs programming language. 我需要使用 Node.js 编程语言来训练我的 OpenAI 模型。 I just got python script to train my openai mode

Transformer微调实战:通过低秩分解(LoRA)对T5模型进行微调(LoRA Fine Tune)
scient scient一个用python实现科学计算相关算法的包,包括自然语言、图像、神经网络、优化算法、机器学习、图计算等模块。 scient源码和编译安装包可以在Python package index获取。 The source code and binary installers for the latest released version are available at t
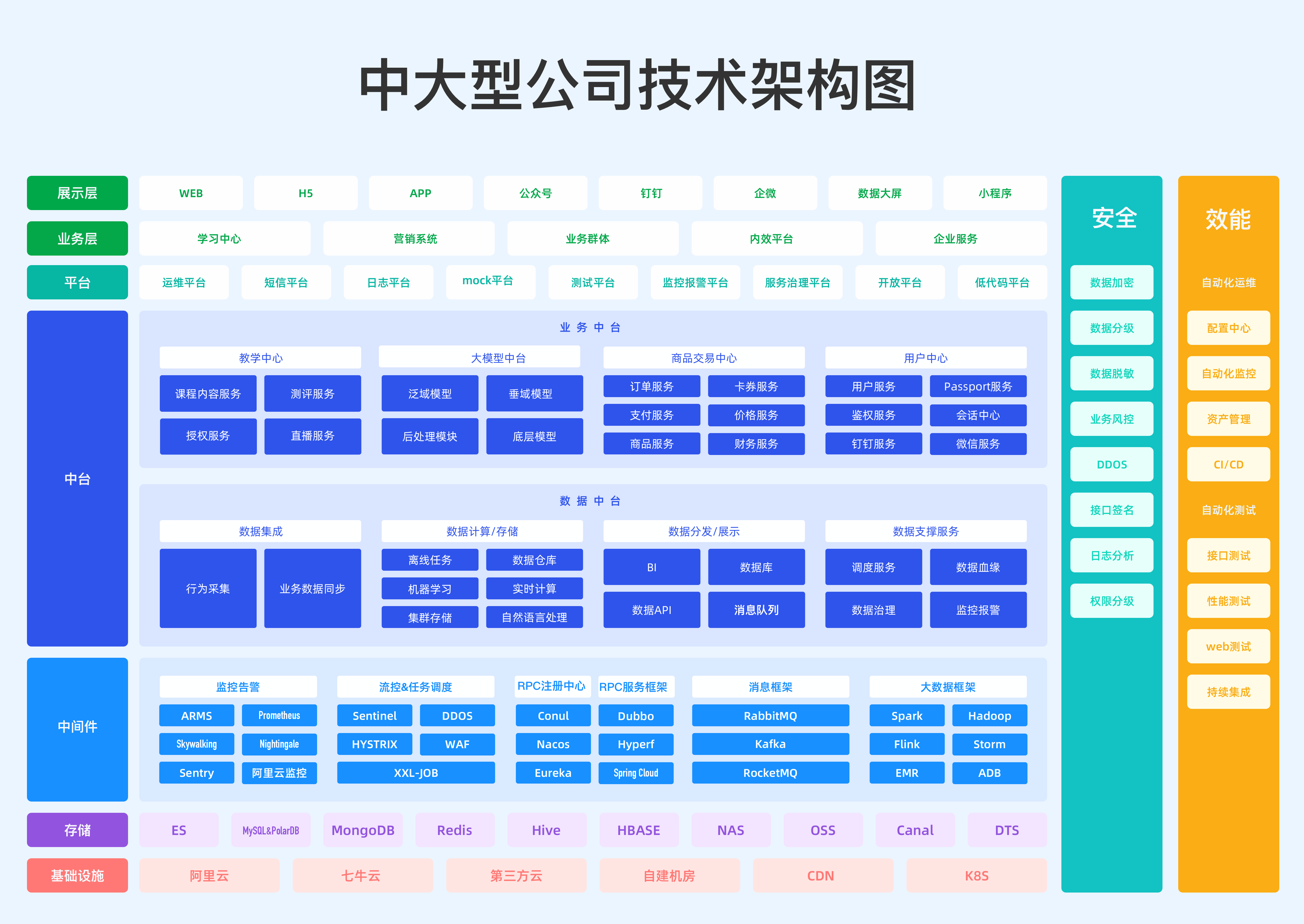
AI全栈大模型工程师(二十七)如何部署自己 fine-tune 的模型
服务器价格计算器 火山引擎提供的这个价格计算器很方便,做个大概的云服务器 GPU 选型价格参考。其它服务厂商价格相差不是很多。 https://www.volcengine.com/pricing?product=ECS&tab=2 高稳定和高可用地部署模型 序号模块名称描述1负载均衡将流入的请求分发到多个模型实例上,如 Nginx, K8S 等2模型服务层(Torch Serve)托

使用RAG与Fine-tune技术
当使用RAG与精调技术 在利用大型语言模型(LLMs)的潜力时,选择RAG(检索增强生成)和精调(fine-tuning)技术至关重要。本文探讨两种技术的适用场景,包括LLMs、不同规模的模型及预训练模型。 简介 LLMs:通过大规模文本数据预训练,具备生成文本、回答问题等能力。RAG:增强LLMs,通过检索数据库中的相关知识为文本生成提供上下文。精调:通过域特定数据训练,使预训练LLM适应

关于迁移学习与fine-tune的关系(借鉴引用参考)
—————————————————————————————————————— 引用:https://www.zhihu.com/question/49534423 —————————————————————————————————————— 假设有个新的数据集,需要做一下图片分类,这个数据集是关于Flowers的。问题是,数据集中flower的类别很少,数据集中的数据也不多,你发现从零训练开始
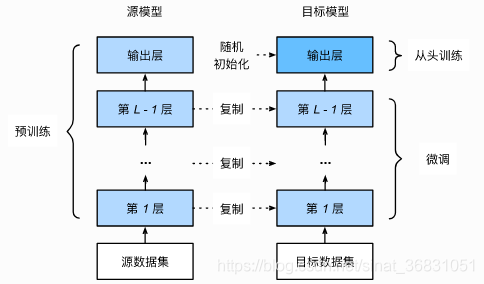
深度学习笔记(一):模型微调fine-tune
深度学习中的fine-tuning 一. 什么是模型微调 1. 预训练模型 (1) 预训练模型就是已经用数据集训练好了的模型。 (2) 现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数; ( 3 ) 正常情况下,我们常用的VG
如何Fine-Tune微调SAM
转眼已经到了2023年的末尾,年初ChatGPT爆火,随后SAM横空出世,给今年的科技圈带来了众多看点,在SAM刚刚发布的时候我们也做过相关的实践,感兴趣的话可以自行移步阅读: 《Segment Anything Model (SAM)——卷起来了,那个号称分割一切的CV大模型他来了》 《Segment Anything Model (SAM)——分割一切,具有预测提示输入的图像分割实践》
Ray.tune可视化调整超参数Tensorflow 2.0
Ray.tune官方文档 调整超参数通常是机器学习工作流程中最昂贵的部分。 Tune专为解决此问题而设计,展示了针对此痛点的有效且可扩展的解决方案。 请注意,此示例取决于Tensorflow 2.0。 Code: ray/python/ray/tune at master · ray-project/ray · GitHub Examples: https://github.com/ra
How to Fine-Tune BERT for Text Classification 论文笔记
How to Fine-Tune BERT for Text Classification 论文笔记 论文地址:How to Fine-Tune BERT for Text Classification? BERT在NLP任务中效果十分优秀,这篇文章对于BERT在文本分类的应用上做了非常丰富的实验,介绍了一些调参以及改进的经验,进一步挖掘BERT的潜力。 实验主要在8个被广泛研究的数据集上进
【tensorflow】slim模块中fine-tune中的BatchNormalization的设置
tensorflow的BatchNorm 应该是tensorflow中最大的坑之一。大家遇到最多的问题就是在fine-tune的时候,加载一个预模型然后在训练时候发现效果良好,但是在测试的时候直接扑街。 这是因为batch normalization在训练过程中需要去计算整个样本的均值和方差,而在代码实现中,BN则是采取用移动平均(moving average)来求取批均值和批方差来,所以在每一
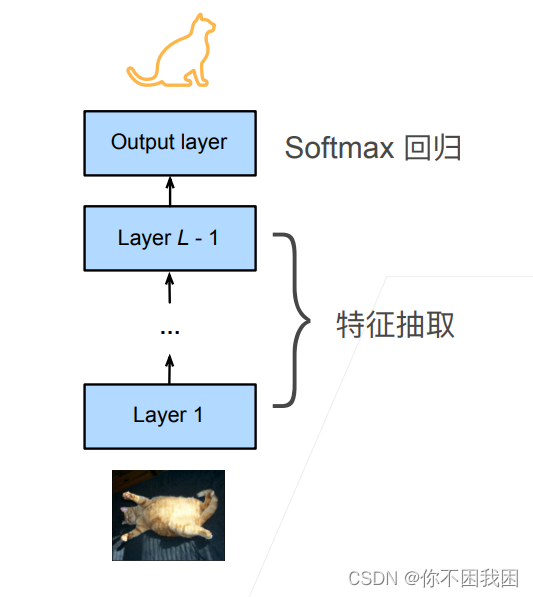
微调Fine tune
网络架构 一个神经网络一般可以分为两块 特征抽取将原始像素变成容易线性分割的特征线性分类器来做分类 微调:使用之前已经训练好的特征抽取模块来直接使用到现有模型上,而对于线性分类器由于标号可能发生改变而不能直接使用 训练 是一个目标数据集上的正常训练任务,但使用更强的正则化 使用更小的学习率使用更小的数据迭代 源数据集远复杂于目标数据,通常微调效果会更好 重用分类器权重 源数据集可能也

大模型fine-tune 微调
大模型的 Fine-tune 我们对技术的理解,要比技术本身更加重要。 正如我在《大模型时代的应用创新范式》一文中所说,大模型会成为AI时代的一项基础设施。 作为像水、电一样的基础设施,预训练大模型这样的艰巨任务,只会有少数技术实力强、财力雄厚的公司去做。 绝大多数人,是水、电的应用者。对这部分人来说,掌握如何用好大模型的技术,更加重要。 用好大模型的第一个层次,是掌握提示词工程(P
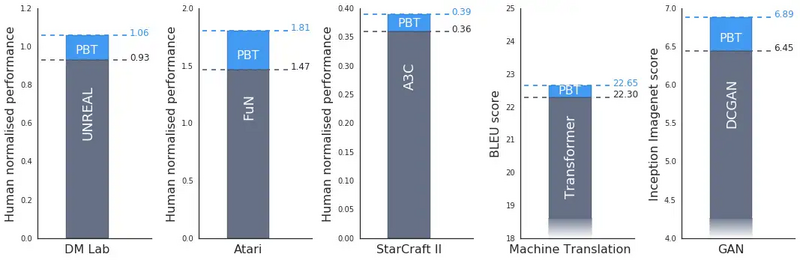
python炼丹师是什么意思_Ray Tune: 炼丹师的调参新姿势
在机器学习的大多数漂亮的结果背后,是一个研究生(我)或工程师花费数小时训练模型和调整算法参数。正是这种乏味无聊的工作使得自动化调参成为可能。 在 RISELab 中,我们发现越来越有必要利用尖端的超参数调整工具来跟上最先进的水平。深度学习性能的提高越来越依赖于新的和更好的超参数调整算法,如基于分布的训练(PBT) ,HyperBand,和 ASHA。 Source: 基于分布的训练大大提高了
[sd_scripts]之fine_tune
https://github.com/kohya-ss/sd-scripts/blob/main/docs/fine_tune_README_ja.mdhttps://github.com/kohya-ss/sd-scripts/blob/main/docs/fine_tune_README_ja.md fine-tune微调是指使用图像和文本对来训练模型,不包括lora、textual inv