本文主要是介绍微调Fine tune,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
网络架构
一个神经网络一般可以分为两块
- 特征抽取将原始像素变成容易线性分割的特征
- 线性分类器来做分类
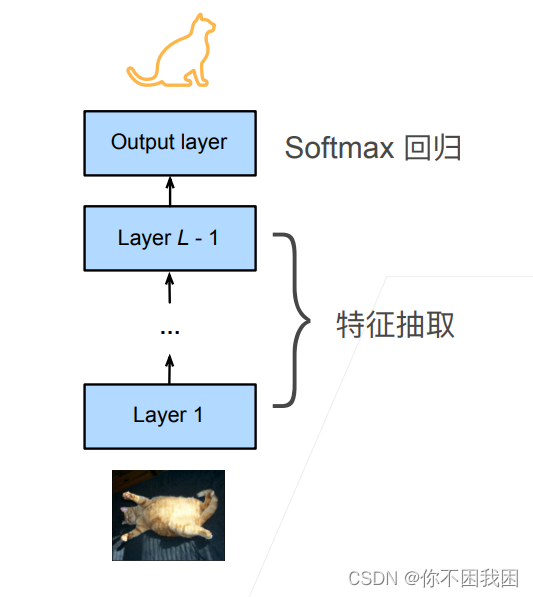
微调:使用之前已经训练好的特征抽取模块来直接使用到现有模型上,而对于线性分类器由于标号可能发生改变而不能直接使用
训练
是一个目标数据集上的正常训练任务,但使用更强的正则化
- 使用更小的学习率
- 使用更小的数据迭代
源数据集远复杂于目标数据,通常微调效果会更好
重用分类器权重
- 源数据集可能也有目标数据中的部分标号
- 可以使用预训练好模型分类器中对应标号对应的向量来做初始化
固定一些层
神经网络通常学习有层次的特征表示
- 低层次的特征更加通用
- 高层次的特征则更和数据集相关
可以固定底部一些层的参数,不参与更新来减小模型的复杂度 - 更强的正则
微调通过使用在大数据上得到的预训练好的模型来初始化模型权重来完成提升精度
预训练模型质量很重要
微调通常速度更快,精度更好
就是重用在大数据集上训练好的模型的特征提取模块,用来做自己模型的特征提取的初始化,用来使得相比于随机初始化有更好的效果
1. 实现
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
# 热狗数据集来源于网络d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')data_dir = d2l.download_extract('hotdog')train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 图像的大小和纵横比各有不同hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4)
# 数据增广normalize = torchvision.transforms.Normalize([0.485, 0.456, 0.406], # 因为要使用imageNet上的特征提取模块,所以要对数据先进行归一化【方差,均值】[0.229, 0.224, 0.225])train_augs = torchvision.transforms.Compose([torchvision.transforms.RandomResizedCrop(224),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(), normalize])test_augs = torchvision.transforms.Compose([torchvision.transforms.Resize(256),torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(), normalize])
# 定义和初始化模型pretrained_net = torchvision.models.resnet18(pretrained=True)pretrained_net.fc # 输出Linear(in_features=512, out_features=1000, bias=True)finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) # 只对最后一层的类别改变
nn.init.xavier_uniform_(finetune_net.fc.weight)
# 微调模型def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,param_group=True):train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'),transform=train_augs),batch_size=batch_size, shuffle=True)test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'),transform=test_augs),batch_size=batch_size)devices = d2l.try_all_gpus()loss = nn.CrossEntropyLoss(reduction="none")if param_group:params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]trainer = torch.optim.SGD([{'params': params_1x}, {'params': net.fc.parameters(), # 最后一层分类器的学习率提高十倍,为了使其能够更快的学习'lr': learning_rate * 10}], lr=learning_rate,weight_decay=0.001)else:trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0.001)d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
# 使用较小的学习率train_fine_tuning(finetune_net, 5e-5)# 为了进行比较, 所有模型参数初始化为随机值 -》结果没有之前微调的效果好
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
train_fine_tuning(scratch_net, 5e-4, param_group=False)
这篇关于微调Fine tune的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









