本文主要是介绍深度学习笔记(一):模型微调fine-tune,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
深度学习中的fine-tuning
-
一. 什么是模型微调



1. 预训练模型
(1) 预训练模型就是已经用数据集训练好了的模型。
(2) 现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数;
( 3 ) 正常情况下,我们常用的VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
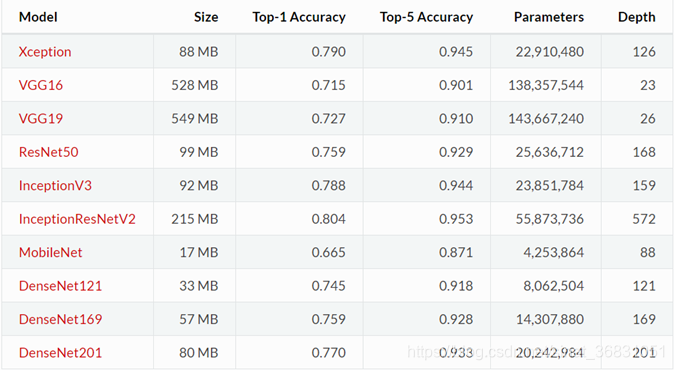
2. 常用的预训练模型
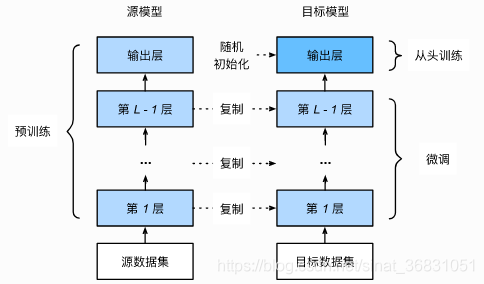
3. 微调的四个步骤
1. 在源数据集(如 ImageNet 数据集)上预训练一个神经网络模型,即源模型。
2. 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集;还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
3. 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
4. 在目标数据集(例如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
-
二. 为什么要微调
卷积神经网络的核心是:
(1)浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
(2)深层卷积层提取抽象特征,比如整个脸型。
(3)全连接层根据特征组合进行评分分类。
普通预训练模型的特点是:
用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
所以,不做微调会:
(1)从头开始训练,需要大量的数据,计算时间和计算资源。
(2)存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
使用微调会:
有效避免了上述可能存在的问题。
-
三. 什么情况下使用微调?
- (1) 要使用的数据集和预训练模型的数据集相似。
- 如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。
- (2) 自己搭建或者使用的CNN模型正确率太低。
- (3)数据集相似,但数据集数量太少。
- (4)计算资源太少。
不同类型数据集下使用微调
- 1. 数据集1 - 数据量少,但数据相似度非常高:
- 在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
- 2. 数据集2 - 数据量少,数据相似度低 :
- 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
- 3. 数据集3 - 数据量大,数据相似度低:
- 在这种情况下,由于我们有一个大的数据集,神经网络训练将会很有效。但是由于该数据与用于训练预训练模型的数据相比有很大不同,直接使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
- 4. 数据集4 - 数据量大,数据相似度高:
- 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后可以使用在预先训练的模型中的权重来重新训练该模型。
-
四. 微调注意事项
- (1)通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。
- 例如,ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
- (2)使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
- (3)如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
这篇关于深度学习笔记(一):模型微调fine-tune的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



