transfomer专题

大模型Transfomer算法工程师学习路径(ChatGPT版)
学习Transformer模型的原理并实现大模型是一个复杂但非常有价值的目标。下面是一个详细的学习路径,帮助你从基础到实现逐步掌握: 1. 打好基础 数学基础:掌握线性代数(矩阵乘法、特征向量等)、微积分(导数、积分、链式法则等)和概率统计(分布、期望、方差等)。这些知识对理解机器学习中的概念至关重要。编程基础:熟练掌握Python,因为Python是机器学习领域的主要编程语言。可以通过练习L

transfomer中attention为什么要除以根号d_k
简介 得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下: A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d k ) V Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=Softmax(dk

【NLP】从变形金刚到Transfomer 01
Transformer是一种非常强大的模型,在自然语言处理(NLP)领域里引起了一场革命。 "从变形金刚到技术革命家,Transformer不再仅是儿时屏幕上的英雄。🤖✨ 在今天的AI领域,它变身成为自然语言处理的超级英雄,领导着一场深刻的学习革命。🚀💡 现在我们一起探索这个使机器理解人类语言成为可能的技术奇迹。#NLP #AI革命 #Transformer” 目录 01 基本
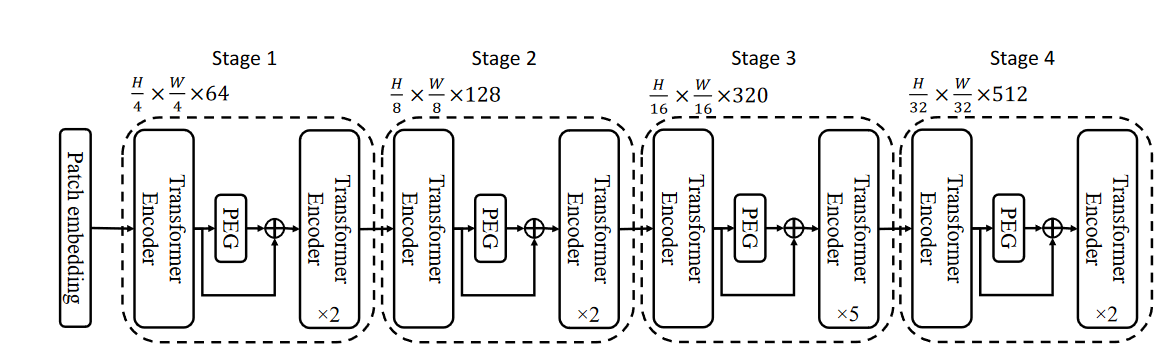
注意力与transformer:位置编码与vision transfomer
个人博客:Sekyoro的博客小屋 个人网站:Proanimer的个人网站 这里介绍一些细节信息.有关位置编码信息和用于图像的transformer. 线性注意力 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ ) V Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}

Vision Transfomer系列第一节---从0到1的源码实现
本专栏主要是深度学习/自动驾驶相关的源码实现,获取全套代码请参考 这里写目录标题 准备逐步源码实现数据集读取VIt模型搭建hand类别和位置编码类别编码位置编码 blocksheadVIT整体 Runner(参考mmlab)可视化 总结 准备 本博客完成Vision Transfomer(VIT)模型的搭建和flowers数据集的训练测试.整个源码包括如下几个任务: 1.读取

Transfomer完整学习笔记一:Encoder-Decoder,Seq2Seq
最近常看到transformer框架下的论文,且知道transformer势头大盛,但对transformer缺乏了解,所以就记录下关于transformer的完整学习过程,从最基本的部分开始学习这里做以记录。 Encoder-Decoder,Seq2Seq 什么是seq2seq& encoder-decoderEncoderDecoder 本篇学习笔记主要参考 这篇blog
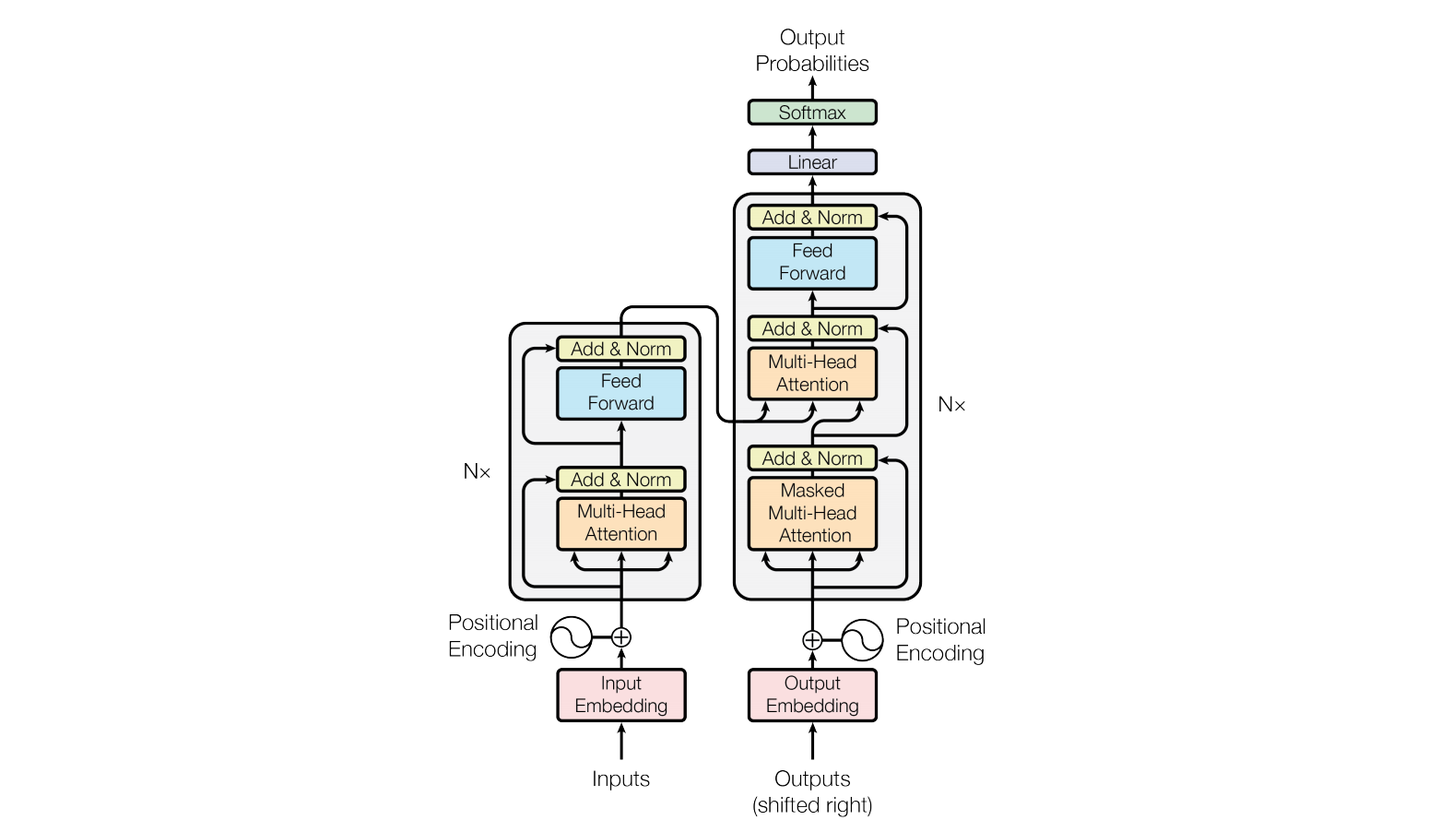
自然语言处理:transfomer架构
介绍 transfomer是自然语言处理中的一个重要神经网络结构,算是在传统RNN和LSTM上的一个升级,接下来让我们来看看它有处理语言序列上有哪些特殊之处 模型整体架构 原论文中模型的整体架构如下,接下来我们将层层解析各层的作用和代码实现 该模型架构主要包含的基本层有 嵌入层(Input Embedding)位置编码层(Positional Encoding)多头注意力层(Multi-

transfomer中正余弦位置编码的源码实现
简介 Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)就是用来解

transfomer中Multi-Head Attention的源码实现
简介 Multi-Head Attention是一种注意力机制,是transfomer的核心机制,就是图中黄色框内的部分. Multi-Head Attention的原理是通过将模型分为多个头,形成多个子空间,让模型关注不同方面的信息。每个头独立进行注意力运算,得到一个注意力权重矩阵。输出的结果再通过线性变换和拼接操作组合在一起。这样可以提高模型的表示能力和泛化性能。 在Multi-Head
transfomer中Decoder和Encoder的base_layer的源码实现
简介 Encoder和Decoder共同组成transfomer,分别对应图中左右浅绿色框内的部分. Encoder: 目的:将输入的特征图转换为一系列自注意力的输出。 工作原理:首先,通过卷积神经网络(CNN)提取输入图像的特征。然后,这些特征通过一系列自注意力的变换层进行处理,每个变换层都会将特征映射进行编码并产生一个新的特征映射。这个过程旨在捕捉图像中的空间和通道依赖关系。 作用:通过处
Transfomer重要源码解析:缩放点击注意力,多头自注意力,前馈网络
本文是对Transfomer重要模块的源码解析,完整笔记链接点这里! 缩放点积自注意力 (Scaled Dot-Product Attention) 缩放点积自注意力是一种自注意力机制,它通过查询(Query)、键(Key)和值(Value)的关系来计算注意力权重。该机制的核心在于先计算查询和所有键的点积,然后进行缩放处理,应用softmax函数得到最终的注意力权重,最后用这些权重对值进

通俗理解词向量模型,预训练模型,Transfomer,Bert和GPT的发展脉络和如何实践
最近研究GPT,深入的从transfomer的原理和代码看来一下,现在把学习的资料和自己的理解整理一下。 这个文章写的很通俗易懂,把transformer的来龙去脉,还举例了很多不错的例子。 Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT_v_JULY_v的博客-CSDN博客 有了原理还需要进行代码实践,这篇文章从0开始讲解了一个简易的Tra

FPT: Feature Pyramid Transfomer
导言: 本文介绍了一个在空间和尺度上全活跃特征交互(fully active feature interaction across both space and scales)的特征金字塔transformer模型,简称FPT。该模型将transformer和Feature Pyramid结合,可用于像素级的任务,在论文中作者进行了目标检测和实力分割,都取得了比较好的效果。为了讲解清楚,

video-swin-transfomer代码讲解
原文链接:https://blog.csdn.net/ly59782/article/details/120823052 Swin-Transformer和Video Swin-Transformer大同小异,感觉最大的区别就是2D的改到了3D,其实操作都是一样的,就是多了一个维度,所以主要还是基于2d讲解的,然后类比一下3d就好啦,讲的是tiny版本的。 源码git传送门:https://g
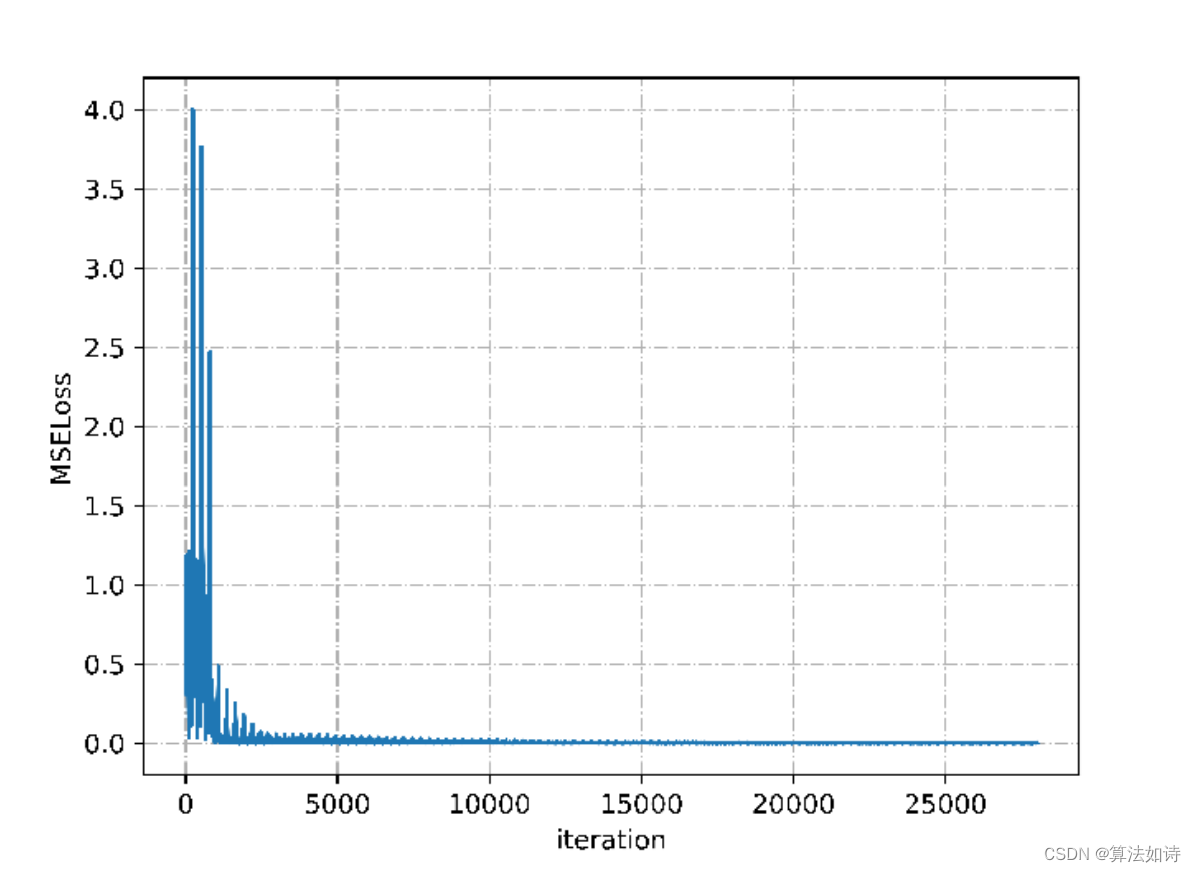
Transformer模型 | Python实现基于LSTM与Transfomer的股票预测模型(pytorch)
文章目录 效果一览文章概述LSTM模型原理时间序列模型从RNN到LSTM LSTM预测股票模型实现结语程序设计参考资料 效果一览 文章概述 基于LSTM与Transfomer的股票预测模型 股票行情是引导交易市场变化的一大重要因素,若能够掌握股票行情的走势,则对于个人和企业的投资都有巨大的帮助。然而,股票走势会受到多方因素的影响,因此难以从影响因素入手定量地