本文主要是介绍自然语言处理:transfomer架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
transfomer是自然语言处理中的一个重要神经网络结构,算是在传统RNN和LSTM上的一个升级,接下来让我们来看看它有处理语言序列上有哪些特殊之处
模型整体架构
原论文中模型的整体架构如下,接下来我们将层层解析各层的作用和代码实现
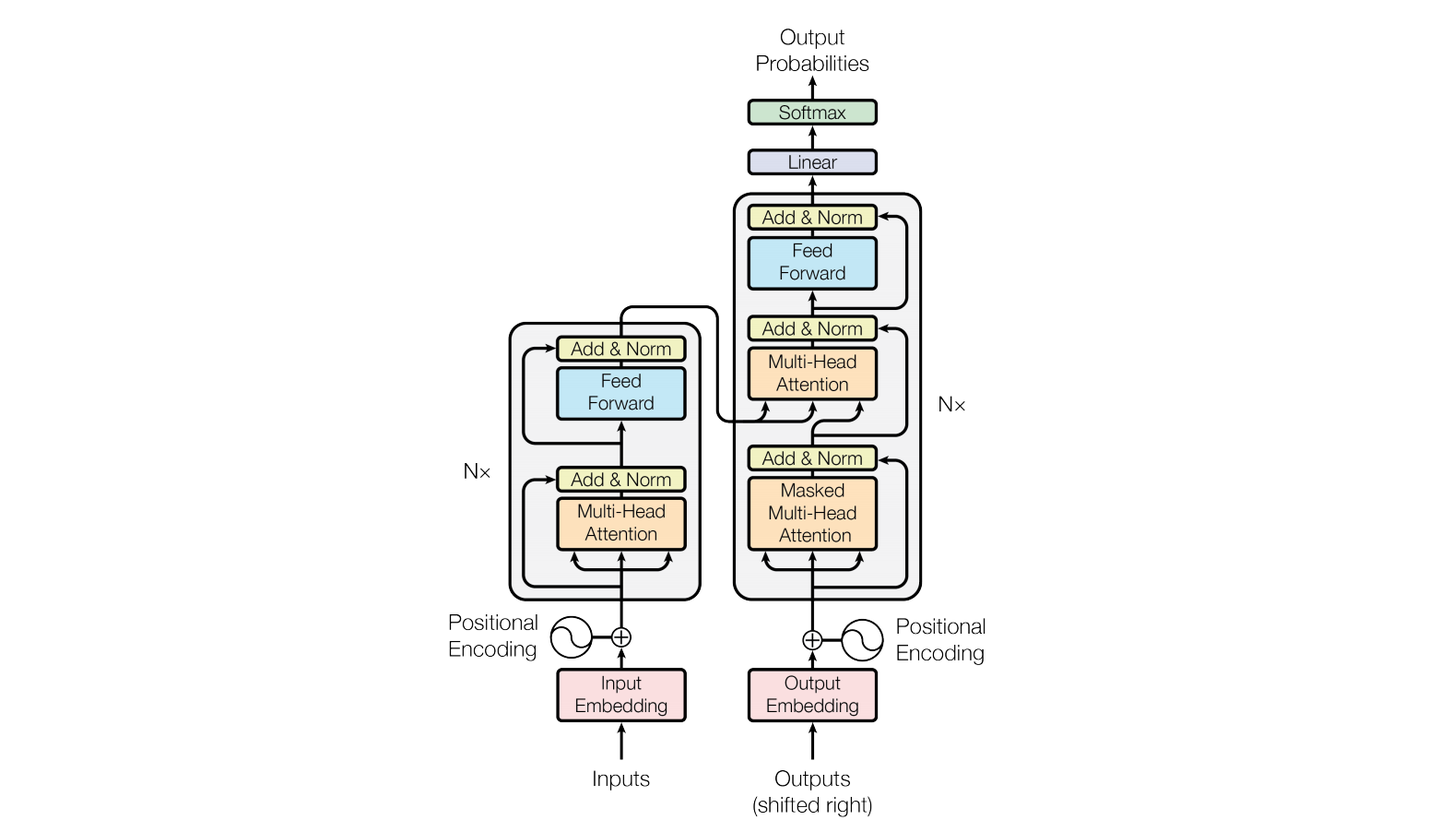
该模型架构主要包含的基本层有
- 嵌入层(Input Embedding)
- 位置编码层(Positional Encoding)
- 多头注意力层(Multi-Head Attention)
- 全连接层(Feed Forward)
位置编码层
作用
顾名思义,位置编码层使模型能够记住输入句子的位置信息,语序在理解自然语言方面起到很大的作用
位置编码层的结构
- 嵌入层(Input Embedding)
- 位置编码层(Positional Encoding)
嵌入层扩充句子维度,这也是模型训练的关键数据,位置编码层则给句子中的每个词赋予位置信息,因为嵌入层在torch中有函数可以直接调用,所以这里和位置编码层放在一起处理
位置编码的方法
我们将pe当作位置编码,pos为句子当中的第pos个词,i是第i个词向量维度,dmodel为编码维度总数。则
P E p o s , 2 i = s i n ( p o s 1000 0 i / d m o d e l ) PE_{pos, 2i}=sin(\frac{pos}{10000^{i/dmodel}}) PEpos,2i=sin(10000i/dmodelpos)
P E p o s , 2 i + 1 = c o s ( p o s 1000 0 i / d m o d e l ) PE_{pos, 2i+1}=cos(\frac{pos}{10000^{i/dmodel}}) PEpos,2i+1=cos(10000i/dmodelpos)
使用正弦和余弦函数有几个原因:
-
可学习性: 通过使用正弦和余弦函数,模型可以学习位置编码的参数。这允许模型自动调整和适应不同任务和数据集的序列长度,而无需手动调整位置编码的固定参数。
-
连续性: 正弦和余弦函数是连续的,这有助于确保位置编码的连续性。这对于模型学习和推广到未见过的序列长度是有益的。
-
相对位置信息: 正弦和余弦函数的组合能够编码相对位置信息。这意味着不同位置之间的距离和关系可以以一种更灵活的方式进行编码,而不是简单的线性关系。
-
周期性: 正弦和余弦函数具有周期性,这有助于模型在处理不同尺度的序列时更好地捕捉全局位置信息。
具体代码
接下来我们来看实现位置编码层的代码
这里以输入句子长度为50来举例
# 定义位置编码层
class PositionEmbedding(torch.nn.Module) :def __init__(self):super().__init__()# pos是第几个词,i是第几个词向量维度,d_model是编码维度总数def get_pe(pos, i, d_model):d = 1e4**(i / d_model)pe = pos / dif i % 2 == 0:return math.sin(pe) # 偶数维度用sinreturn math.cos(pe) # 奇数维度用cos# 初始化位置编码矩阵pe = torch.empty(50, 32)for i in range(50):for j in range(32):pe[i, j] = get_pe(i, j, 32)pe = pe. unsqueeze(0) # 增加一个维度,shape变为[1,50,32]# 定义为不更新的常量self.register_buffer('pe', pe)# 词编码层self.embed = torch.nn.Embedding(39, 32) # 39个词,每个词编码成32维向量# 用正太分布初始化参数self.embed.weight.data.normal_(0, 0.1)def forward(self, x):# [8,50]->[8,50,32]embed = self.embed(x)# 词编码和位置编码相加# [8,50,32]+[1,50,32]->[8,50,32]embed = embed + self.pereturn embed
文章将三天一更,将结构详细解析完为止,下一次将讲解掩码Mask的作用…
这篇关于自然语言处理:transfomer架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



