本文主要是介绍【NLP】从变形金刚到Transfomer 01,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Transformer是一种非常强大的模型,在自然语言处理(NLP)领域里引起了一场革命。

"从变形金刚到技术革命家,Transformer不再仅是儿时屏幕上的英雄。🤖✨ 在今天的AI领域,它变身成为自然语言处理的超级英雄,领导着一场深刻的学习革命。🚀💡 现在我们一起探索这个使机器理解人类语言成为可能的技术奇迹。#NLP #AI革命 #Transformer”
目录
01 基本概念:
02 关键特点:
03 应用领域:
04 编码器原理
4.1 位置编码(Position Embedding)
4.2 自注意力机制(self-attention)
4.3 多头机制 multi-head
4.4 残差机制
4.5 Feed Forward
01 基本概念:
Tansformer模型最初是在2017年由谷歌团队发表的论文《Attention is All You Need》中被提出的。它的核心思想是利用“自注意力(Self-Attention)”机制来处理序列数据,这让它处理长距离依赖问题时能欧表现出非常优异的性能。与此同时,Transformer模型的并行处理能力**,大大减少了训练时间。

02 关键特点:
- 自注意力机制(self-Attention):使模型能够关注序列中的不同位置,为每个位置的词生成上下文相关的表示。
- 多头注意力(Multi-Head Attentio):通过并行学习序列中不同子空间的信息,增强了模型捕捉不同上下文信息的能力。
- 位置编码(Positional Encodding):由于Transformer完全基于注意力机制,没有循环(RNN)或卷积(CNN)结构,它通过位置编码来了解单词在句子中的位置关系。
- 层归一化(Layer Normalization)和残差连接(Residul Connection):这些技术帮助模型在训练深层网络时保持稳定,加速收敛。
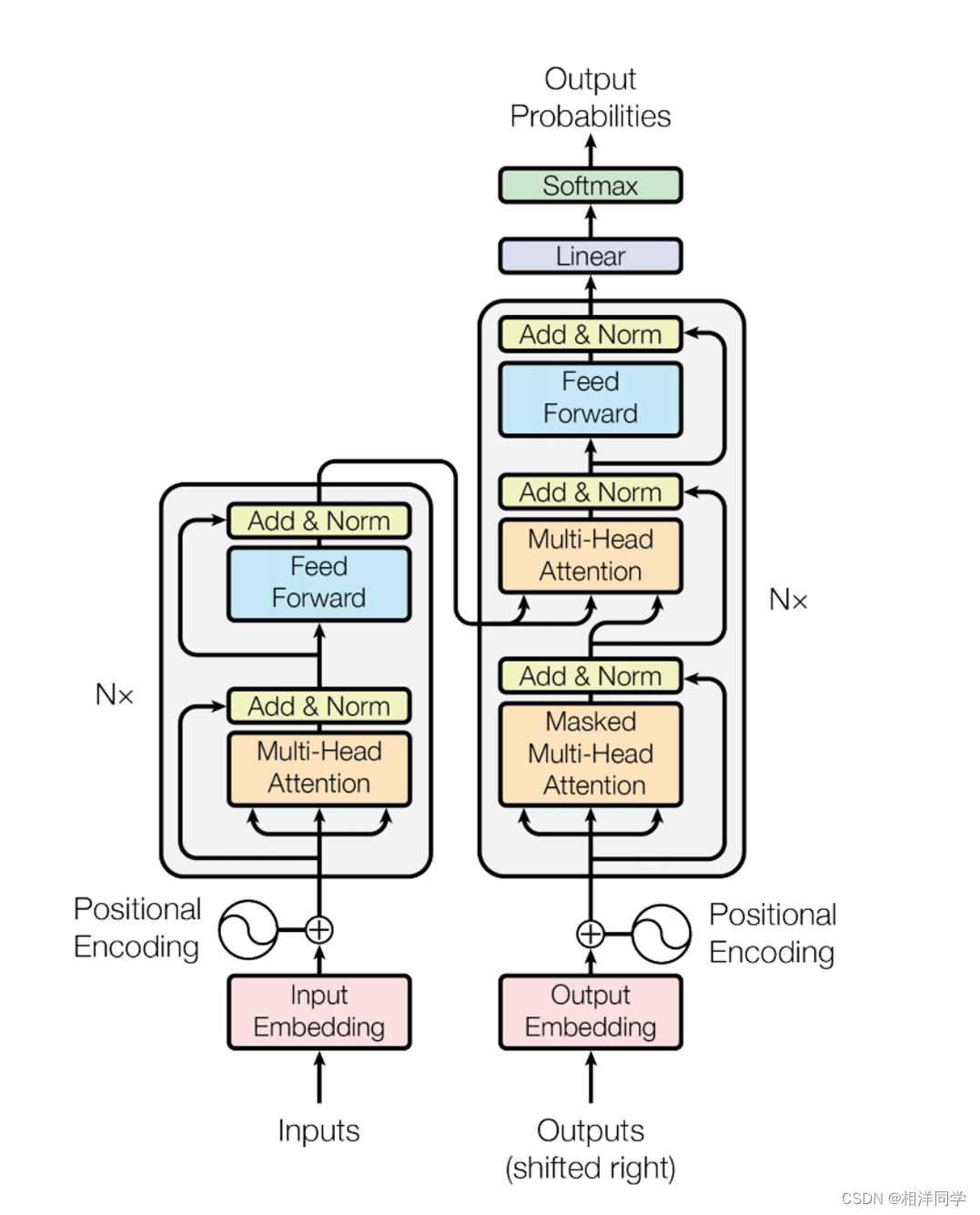
03 应用领域:
Transformer模型的出现推动了许多NLP任务的发展
- 机器翻译
- 文本摘要
- 问答系统和文本生成等
- 它也是后来诸如Bert、GPT系列强大模型的基础。
04 编码器原理
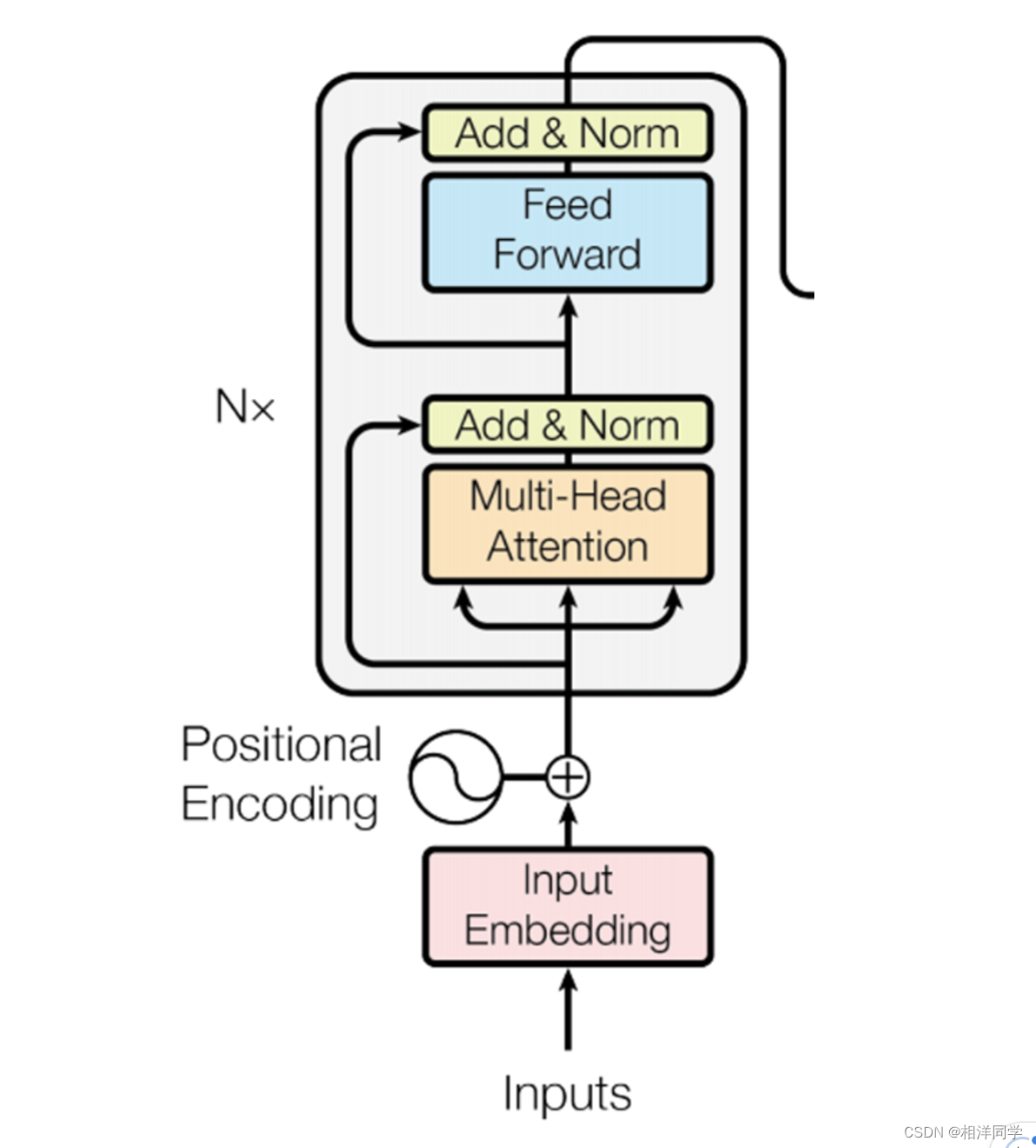
4.1 位置编码(Position Embedding)
在RNN模型训练过程中,需要对词进行向量处理,通过RNN的特殊结构,可以使得模型具备短期记忆的能力。
【深度学习】手动实现RNN循环神经网络-CSDN博客
Transformer中为了更好地记录位置信息,需要在词向量的基础上加上位置编码
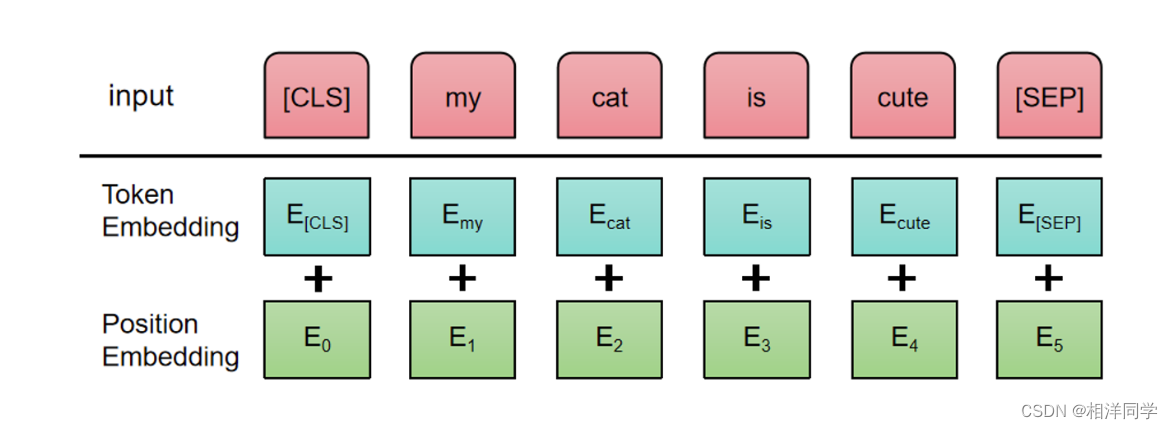
这样词向量就能够代入语序信息,加和之后再做一下归一化,能够使模型能加稳定
4.2 自注意力机制(self-attention)
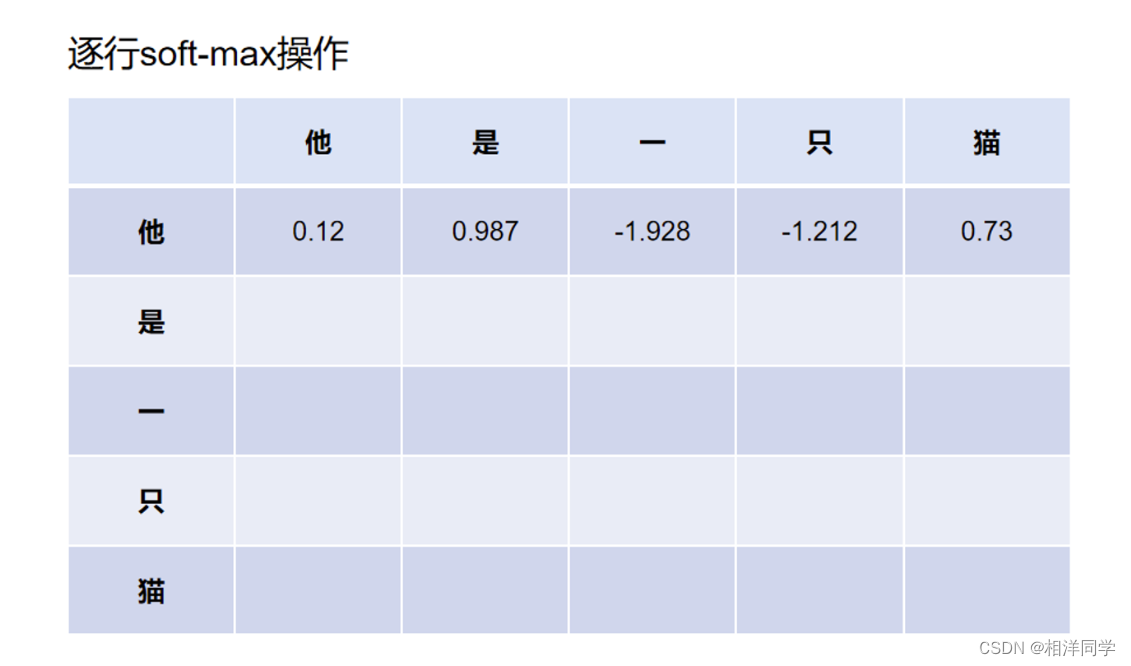
假设通过向量化我们就能够得到一个6*768的矩阵X,分别通过三个不同的可训练的参数矩阵W,得到三个矩阵:Q,K,V.

带入公式:Q乘以K的转置可以得到一个文本长度*文本长度的矩阵,以我们的输入为例就是得到一个6*6的矩阵.除以根号dk再过一个激活函数softmax,最后再乘以一个V.最后我们还会得到一个文本长度乘以向量维度的矩阵.这样操作的原因是为了减小值,让模型更有可能为每一个字分配上概率.
4.3 多头机制 multi-head
所谓多头机制,类似机器学习中的模型集成,将文本长度词向量维度的矩阵切分成头数为n,得到若干个,文本长度(词向量维度/头数)的矩阵.
比如6*768的矩阵,划分为12个6*64的矩阵.分别做自注意力机制.
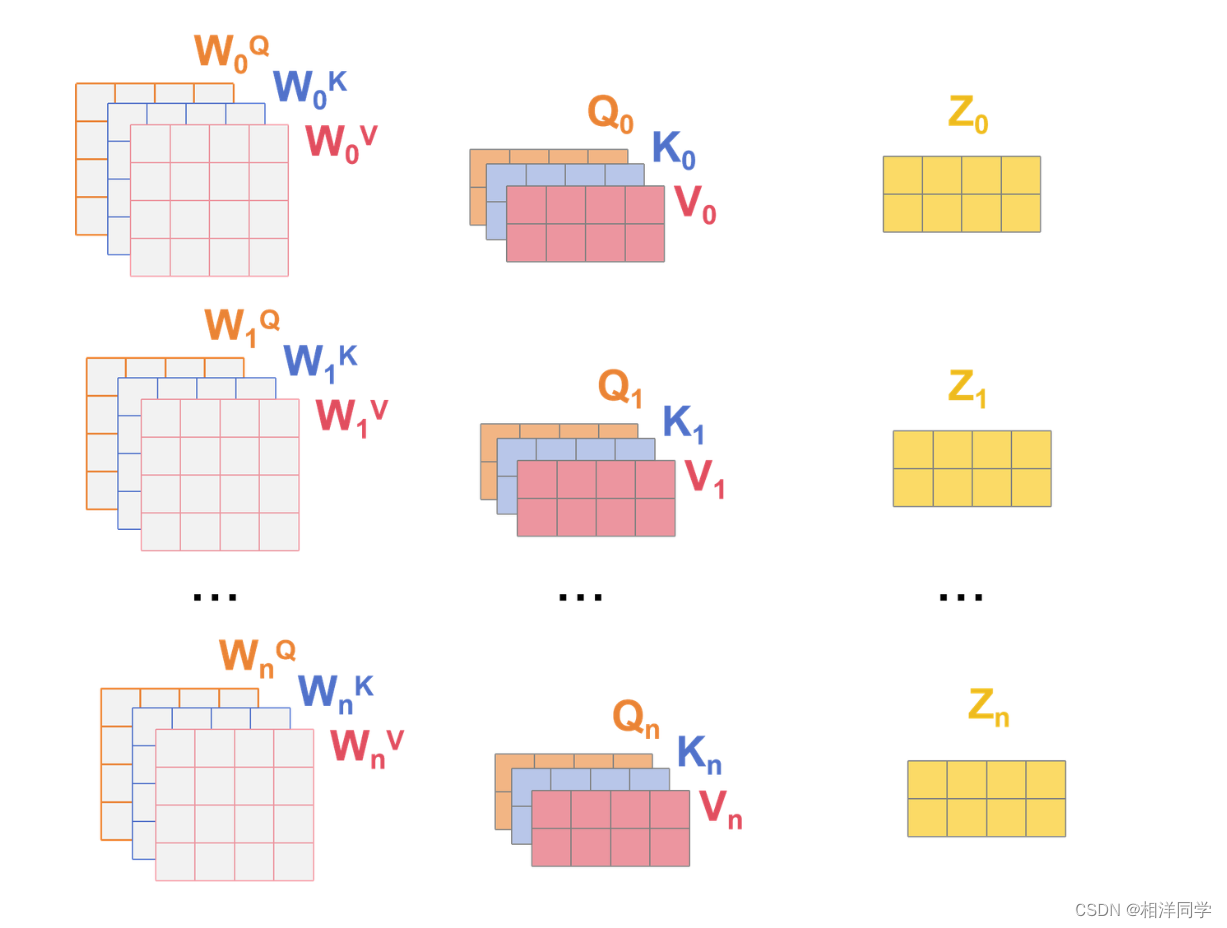
最后将得到的结果拼起来

4.4 残差机制
将过self-atention的矩阵和输入矩阵进行相加,有助于保留过模型前的信息,然后做归一化处理
4.5 Feed Forward
就是两个线性层,过一层之后加一个激活函数,第一个线性层会将原先的维度映射为原来的四倍,后一个线性层再将矩阵映射回原来的维度.就是为了增加可训练的参数.
后面可以堆很多层Transforme。bert中就堆叠了12层.就是为了大力出奇迹
后序还会更新关于解码器部分的内容欢迎关注
以上
君子坐而论道,少年起而行之,共勉

这篇关于【NLP】从变形金刚到Transfomer 01的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





