titanic专题

Scala实现逻辑回归分类,Titanic
https://yixuan.cos.name/cn/2015/04/spark-beginner-1/ 1.读取文件 import scala.io.Sourceobject myfirst {//titanic,LR def main(args: Array[String]) {val data= Source.fromFile("D:\\IDEA\\_01\\train.csv

机器学习学习--Kaggle Titanic--LR,GBDT,bagging
参考,机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 http://www.cnblogs.com/zhizhan/p/5238908.html 机器学习(二) 如何做到Kaggle排名前2% http://www.jasongj.com/ml/classification/ 一、认识数据 1.把csv文件读入成dataframe格式 import pandas as
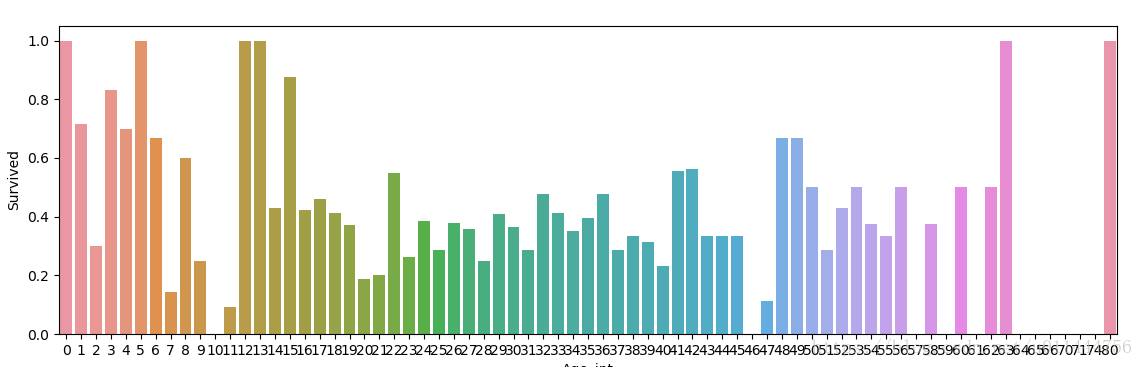
titanic乘客简单的数据分析(matplotlib和seaborn 的使用)
数据来源: kaggle的Titanic 生存模型:titanic_train.csv。 引入的库: import numpy as npimport pandas as pdimport sysreload(sys)sys.setdefaultencoding('gbk')import matplotlib.pyplot as pltimport seaborn as sns

对titanic.csv数据进行预测生死
数据集:http://download.csdn.net/detail/u010343650/9844427 survived:乘客最后的生存情况,这个是我们预测的目标变量 (0代表否,1代表是) pclass:社会经济地位 (1代表上层阶级,2代表中层阶级,3代表底层阶级) name:姓名 sex:性别 age:年纪 sibsp:船上兄弟姐妹或者配偶的数 parch:船
kaggle中Titanic学到的知识
DataFrame.info() 输出dataframe的信息。 notebook作图时,如何显示张中文plt.rc('font',family='SimHei',size=6) dataframe中如果已经知道某些行的索引值,例如想替换age列中,为空的那些值 df.loc[(df.Age.isnull(),'age')] dataframe选择某些列拼接成一个
利用pytorch两层线性网络对titanic数据集进行分类(kaggle)
利用pytorch两层线性网络对titanic数据集进行分类 最近在看pytorch的入门课程,做了一下在kaggle网站上的作业,用的是titanic数据集,因为想搭一下神经网络,所以数据加载部分简单的把训练集和测试集中有缺失值的列还有含有字符串的列去除了,加入了DataLoader模块,其实这个数据集很小,用不到,本人还没入门,小白一枚。 import torch from torch.
数据挖掘分类模型案例 _titanic 幸存者预测
原文出处:http://c.raqsoft.com.cn/article/1572941582533?r=CGQ 数据挖掘分类模型案例 _titanic 幸存者预测

用sklearn(scikit-learn)的LogisticRegression预测titanic生还情况(kaggle)
titanic, prediction using sklearn after EDA, we can now preprocess the training data and learn a model to predict using scikit-learn (sklearn) ml library 做完上面的分析,可以选定几个特征进行使用,然后选择模型。 我们使用scikit-lea
Titanic沉船数据集之获救乘客预测
项目目标: Titanic数据集是我们进入到机器学习领域中的第一个数据集,同我们学习编程的第一句程序语言(‘hello,world’)是一样的。通过对该数据集进行机器学习建模,掌握Numpy,Pandas,Matplotlib,Sklearn等常用数据分析库的使用,并掌握机器学习的完成流程数据预处理 - 建立基础模型 - 模型评估 - 调参 - 固定模型参数。 背景介绍: 泰坦尼克沉船是震惊

Kaggle:Getting Started of Titanic
一、概要 泰坦尼克号幸存预测是Kaggle上参与人数最多的的比赛之一,要求参赛人员预测乘客是否能够幸存,是一个典型的二分类问题。 二、数据简介 官网提供训练数据集train.csv和测试数据集test.csv和一个提交样例数据集,数据中的各个字段如下: PassengerId: 乘客的IDSurvived:1代表幸存,0代表遇难Pclass:票类别-社会地位, 1代表Upper,2代表

kaggle竞赛——Titanic:Machine Learning from Disaster
题目地址:https://www.kaggle.com/c/titanic 根据所提供的乘客信息,判断该乘客Survived or not? Introduction 机器学习这块停了整整三个月,主要原因是一方面课题需要推进尤其是修改论文,进度特别慢,终于知道为啥修改论文要至少三个月了!另一方面,学习了数据结构与算法方面的内容,目的是提高自己编程能力,之前从未想过手编梯度下降、逻辑回归、

【机器学习】Tensorflow神经网络分析Kaggle的Titanic数据集
Titanic这也算是一个很经典的案例了,详情见【官网详情】(博主提交了一次,很菜七千多名,正确率:0.76555,排名有点渣,日后再优化,优化后,到两千多哈哈,0.79....左右,,还有很大的上升空间) 分析一个案例我主要是一下几步: 【1】导入依赖,加载数据 【2】分析数据,了解数据 【3】格式化数据,预处理数据 【4】建立模型,训练模型 【5】使用模型,测试模型 基本就这

四个模型建模及数据分析整理(基于Titanic数据集)
目录 介绍: 二、数据 2.1引用数据 2.2检查缺失数据 2.2.1手动检查缺失数据 2.2.2查看某一个特征值为空数据 2.3补充缺失数据 2.3.1盒图 2.3.2手动用均值填补缺失数据 2.3.3手动用类别填补缺失数据 三、数据分析 3.1男女生存比例 3.2男女生存数 3.3船舱级别生存比例 3.4船舱生存与死亡比例 3.5票价与生存关系 3.
Kaggle--泰坦尼克号失踪者生死情况预测源码(附Titanic数据集)
数据可视化分析 import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as nptitanic=pd.read_csv('train.csv')#print(titanic.head())#设置某一列为索引#print(titanic.set_index('Passe

Titanic-乘客生存预测2
代码所需数据集:https://github.com/jsusu/Titanic_Passenger_Survival_Prediction_2/tree/master/titanic_data import reimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sn

Titanic : Machine Learning from Disaster
Titanic: Machine Learning from Disaster RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。 1912年4月15日,泰坦尼亚号在首次航行中,与冰山相撞后沉没,在2224名乘客和船员中造成1502人死亡。 这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。 造成这样的生命损失的原因之一是乘客和船员没有足够的救生艇。 虽然在沉船事件幸存有一些运

使用LightGBM和GridSearchCV预测Titanic数据集
对于Titanic数据集预测的初次尝试,主要使用的是LightGBM和GridSearchCV。这两个参数都很多,对应的文档在https://lightgbm.readthedocs.io/en/latest/Experiments.html 和 https://lightgbm.cn/docs/6/#io以及https://scikit-learn.org/stable/modules/gene

将kaggle的competition中的Titanic数据集直接下载到Colab
!pip install -U -q kaggle !mkdir -p ~/.kaggle !echo '{"username":"bruce374","key":"43313de75c23e8c5a1b9713cc04183c0"}' > ~/.kaggle/kaggle.json #usename和key在kaggle--->my account----->create new api to
sklearn教程:titanic泰坦尼克号数据集
文章目录 数据集介绍导入数据集info()显示数据类型和是否缺失describe()数据描述性统计 数据可视化-探索性分析EDA填充缺失值之后的可视化类别变量的相关关系 数据集介绍 这个数据集是基于泰坦尼克号中乘客逃生的,泰坦尼克号出事故,船上的乘客的一些信息被记录在这张表中。现在要根据这个数据预测这个人能否获救。共有891个样本。 数据集属性 属性含义Passen

Titanic_Data Analysis
本项目提供了两份数据:train.csv文件作为训练构建与生存相关的模型;另一份test.csv文件则用于测试集,用我们构建出来的模型预测生存情况; PassengerId --Id,具有唯一标识的作用,即每个人对应一个Id survived --是否幸存 1表示是 0表示否 pclass --船舱等级 1:一等舱 2:二等舱 3:三等舱 Name --姓名,通常西方人的姓名 Sex --性别,

Kaggle入门Titanic生存预测 v1.0.0
目录标题 前言问题定义数据查看分析数据处理数据替换将数据导入模型中进行训练数据预处理模型训练测试集预测总结源码地址 前言 一直在学机器学习的理论知识,但是没有实践,还是感觉心里不踏实,Kaggle的入门比赛Titanic号生存预测是一个getting started competition,很适合入门,掌握机器学习的各种常见套路.这里刚开始也是参考其他代码做的,得分是0.789
Datawhale打卡活动 Kaggle Spaceship Titanic Day2
文章目录 Datawhale打卡活动 Kaggle Spaceship TitanicDay 2 比赛数据分析步骤1:使用pandas完成如下数据分析训练集和测试集的行数分别是多少?训练集中每列的类型是什么?训练集中标签是如何分布,与哪一个特征最相关?训练集中列缺失值如何分布的? 步骤2:使用seaborn或matplotlib完成如下可视化HomePlanet 与 Transported
Kaggle竞赛-Titanic泰坦尼克
#####------------------------------------------------------------------------------------------------------- 在博主的原有基础上修改了部分错误,Jupyter Notebook实现。 代码链接:http://download.csdn.net/download/linxid/10230873
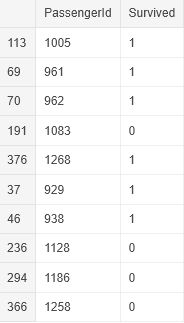
Titanic: Machine Learning from Disaster
A Data Science Framework: To Achieve 99% Accuracy 学习data scientist的思考方式,而不是如何编码。 目录 A Data Science Framework: To Achieve 99% Accuracy 1 怎样处理问题 2 数据科学基本框架 2.1 问题定义 2.2 数据收集 2.3 可用数据准备与

Kaggle - Titanic 生存预测
第一次参加Kaggle,以Titanic来入个门。本次竞赛的目的是根据Titanic的人员信息来预测最终的生存情况。采用Python3来完成本次竞赛。 一、数据总览 从Kaggle平台我们了解到,Training set一共有891条记录,Test set一共有418条记录。提供的相关变量有: VariableDefinitionKeysurvivalSurvival0 = No, 1 =