本文主要是介绍titanic乘客简单的数据分析(matplotlib和seaborn 的使用),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据来源:
kaggle的Titanic 生存模型:titanic_train.csv。
引入的库:
import numpy as np
import pandas as pd
import sys
reload(sys)
sys.setdefaultencoding('gbk')
import matplotlib.pyplot as plt
import seaborn as sns数据分析:
读取数据:
train_data=pd.read_csv("titanic_train.csv")
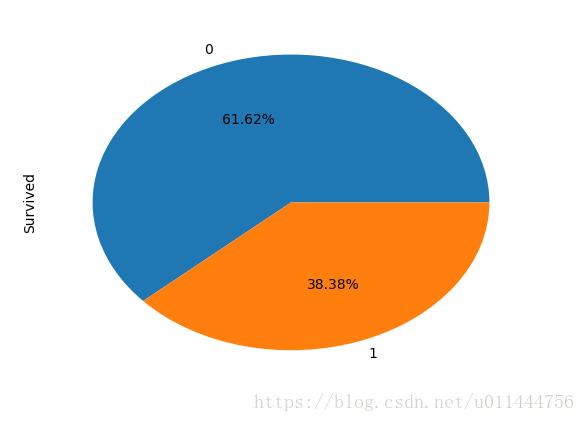
train_data['Survived'].value_counts().plot.pie(autopct = '%1.2f%%') #绘制存活的比例
plt.show()
缺失值处理:
- 用众数填补Embarked(上船的地点):
train_data.Embarked[train_data.Embarked.isnull()] = train_data.Embarked.dropna().mode().values - 使用随机森林预测Age的缺值:
from sklearn.ensemble import RandomForestRegressor#choose training data to predict age age_df = train_data[['Age','Survived','Fare', 'Parch', 'SibSp', 'Pclass']] age_df_notnull = age_df.loc[(train_data['Age'].notnull())] age_df_isnull = age_df.loc[(train_data['Age'].isnull())] X = age_df_notnull.values[:,1:] Y = age_df_notnull.values[:,0] # use RandomForestRegression to train data RFR = RandomForestRegressor(n_estimators=1000, n_jobs=-1) RFR.fit(X,Y) predictAges = RFR.predict(age_df_isnull.values[:,1:]) train_data.loc[train_data['Age'].isnull(), ['Age']]= predictAges - 也可以删除一些不重要的属性值.
分析数据:
- 性别与存活的关系:
train_data.groupby(['Sex','Survived'])['Survived'].count() train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()。
男性存活率是18.9%,女性的存活率是74.2%
- 船舱等级和生存的关系:
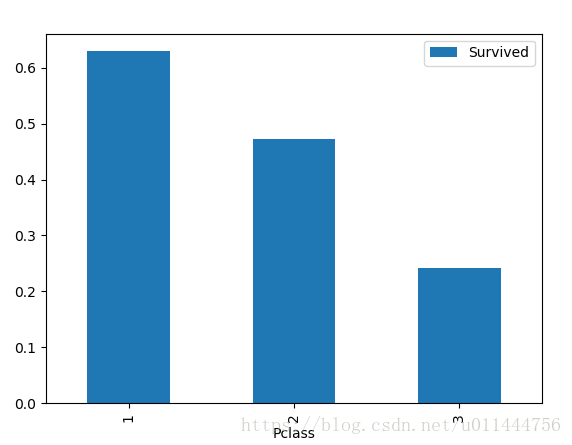
train_data.groupby(['Pclass','Survived'])['Pclass'].count() train_data[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar()
不同等级船舱的男女生存率:train_data.groupby(['Pclass','Survived'])['Pclass'].count() train_data[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar() train_data[['Sex','Pclass','Survived']].groupby(['Pclass','Sex']).mean().plot.bar() - 年龄和生存的关系:
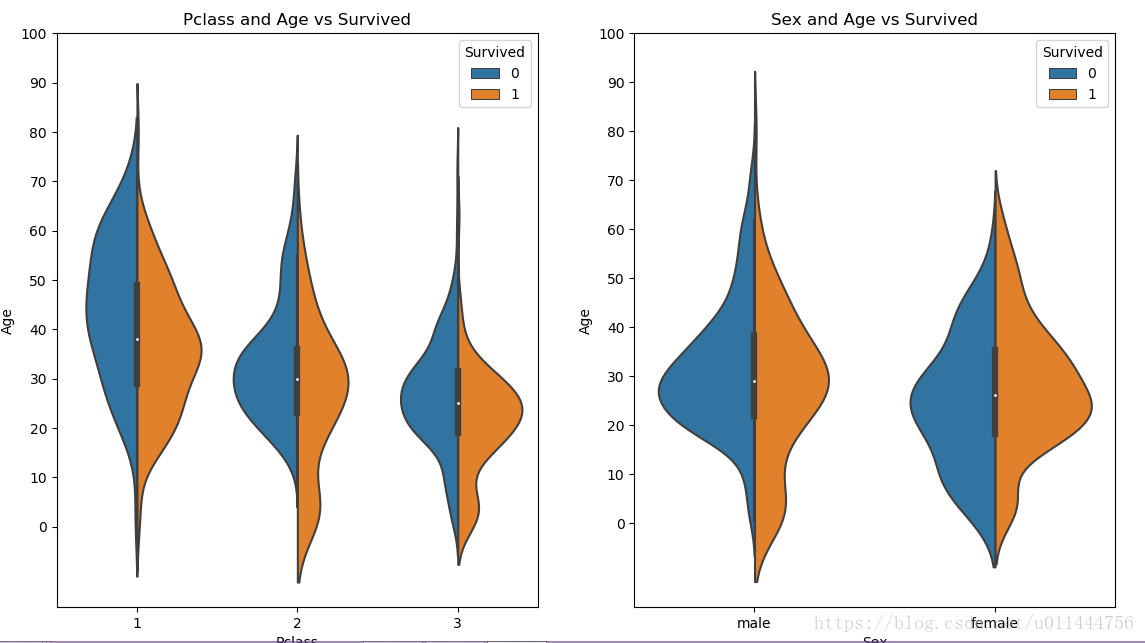
fig, ax = plt.subplots(1, 2, figsize = (18, 8)) sns.violinplot("Pclass", "Age", hue="Survived", data=train_data, split=True, ax=ax[0]) ax[0].set_title('Pclass and Age vs Survived') ax[0].set_yticks(range(0, 110, 10))sns.violinplot("Sex", "Age", hue="Survived", data=train_data, split=True, ax=ax[1]) ax[1].set_title('Sex and Age vs Survived') ax[1].set_yticks(range(0, 110, 10))
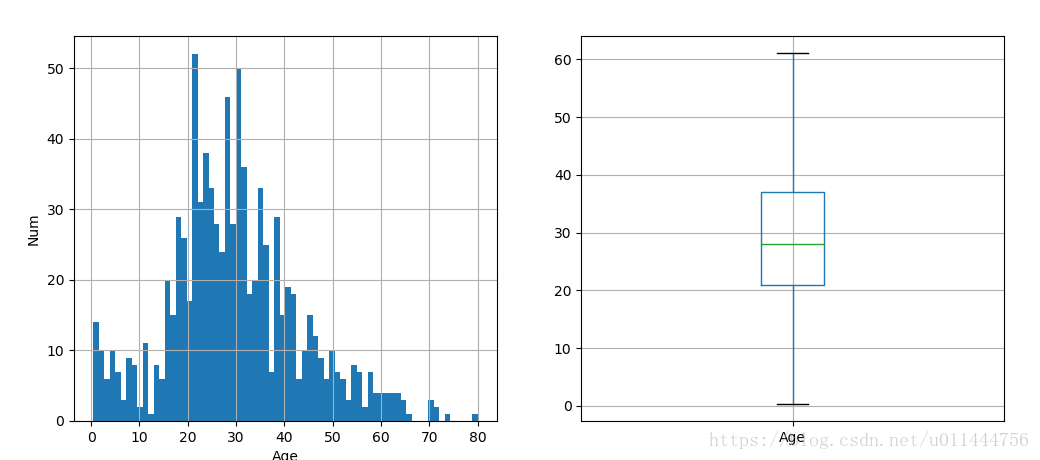
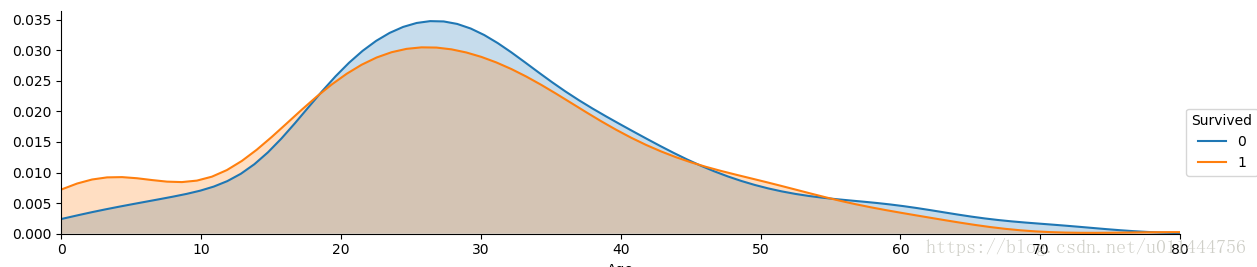
分析总体的年龄分布:plt.figure(figsize=(12,5)) plt.subplot(121) train_data['Age'].hist(bins=70) plt.xlabel('Age') plt.ylabel('Num')plt.subplot(122) train_data.boxplot(column='Age', showfliers=False)facet=sns.FacetGrid(train_data, hue="Survived",aspect=4) facet.map(sns.kdeplot,'Age',shade= True) facet.set(xlim=(0, train_data['Age'].max())) facet.add_legend()
fig, axis1 = plt.subplots(1,1,figsize=(18,4))
train_data["Age_int"] = train_data["Age"].astype(int)
average_age = train_data[["Age_int", "Survived"]].groupby(['Age_int'],as_index=False).mean()
sns.barplot(x='Age_int', y='Survived', data=average_age)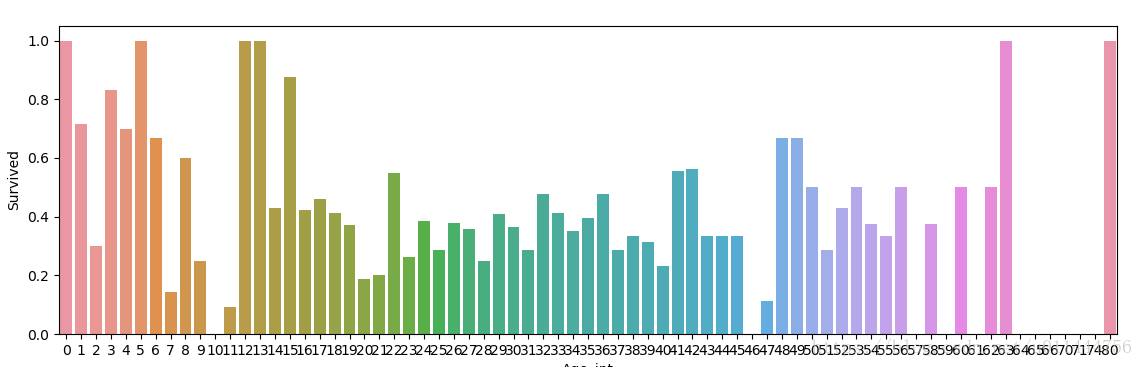
为什么妇女儿童这类“弱者”反而更能生存?
根据泰坦尼克号唯一存活副船长查尔斯·莱特勒,事后描述,面对沉船灾难时,船长爱德华·约翰·史密斯(Edward J. Smith)在最后的时刻下命令,命令先让妇女和儿童上救生艇,许多乘客显得十分平静,一些人则拒绝与家人分开。
作为男性,明明是群体中最具有强壮的体魄,又有相对更丰富的生存经验,怎么反而在这场事故中就成了生存机率最低的?
作为男人、作为孩子的父亲、作为妻子的丈夫,肩头上扛的一边感情,另一边是责任,面对灾难是作出了何种抉择,其实不用多说,看一段回忆录:
一名叫那瓦特列的法国商人把两个孩子送上了救生艇,委托几名妇女代为照顾,自己却拒绝上船。
两个儿子得救后,世界各地的报纸纷纷登载两个孩子的照片,直到他们的母亲从照片上认出了他们。不幸的是,孩子们永远失去了父亲。
新婚燕尔的丽德帕丝同丈夫去美国度蜜月,她死死抱住丈夫不愿独自逃生。
丈夫在万般无奈中一拳将她打昏。丽德帕丝醒来时,她已在一条在海上漂浮的救生艇上了。
此后,她终生未再嫁,以此怀念亡夫。
参考链接:
这篇关于titanic乘客简单的数据分析(matplotlib和seaborn 的使用)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



