textrank专题

TextRank:Gensim使用的文本摘要算法
Gensim是Python的一个无监督主题模型与自然语言处理的开源库,它有许多高效易用的自然语言处理函数。其中有一个文本摘要函数summarize,可以从大量的文本中提取重要的信息。下面简要介绍一下Gensim中的summarize函数的算法。 文章目录 文本摘要与TextRankPageRankTextRankGensim中的TextRank具体摘要算法 文本摘要与TextR

优化TextRank文本摘要,自定义关键词增加句子的权重
关于textRank的原理,我这边就不多介绍了,搜一下很多,我也不确定自己是否讲的有那些大佬清楚,我们主要关注在优化点 痛点: 最近在做文章的摘要项目,一天的摘要量估计在300万篇左右,所以直接放弃了seq2seq的生成时摘要方法,主要还是使用深度学习,速度和精度都达不到要求了。采用textrank是一种解决办法 1. 目前使用FastTextRank, 速度上基本达到了要求, githu

HAC-TextRank算法进行关键语句提取
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群 AI应用开发流程概述Visual Studio Code及Remote Development插件远程开发git开源项目的一些问题及镜像解决办法

提取文档关键词——tfidf、textrank
本文介绍的是提取文本关键词的方法,包括tfidf以及textrank 1 tfidf tfidf内容原理比较简单,先简单讲一下,有空再细化 tfidf分为tf和idf,其中tf指的是词频,idf指的是逆文档频率。tf词频,顾名思义,就是某个词在文档中的出现次数。而idf逆文档频率,则是某个词在多少篇文档中出现过 公式 P.S. 分母的加1,起到的是平滑的作用,避免出现某个词在每篇文章里都

AIOPS最全讲解TextRank算法博文汇总
CSDN博客 自然语言处理入门(8)——TextRank jieba结巴分词–关键词抽取(核心词抽取) textrank算法原理与提取关键词、自动提取摘要PYTHON TextRank算法的基本原理及textrank4zh使用实例 基于TextRank的关键词提取算法 TextRank 处理短文本获得指定关键字 textRank杂谈 textrank提取文档关键词 textrank关键词提取 使

跟我一起学Python3.X之——TextRank算法为文本生成关键字和摘要
TextRank算法基于PageRank,用于为文本生成关键字和摘要。其论文是: Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004. 先从PageRank讲起。 PageRank PageRank最开始用来计算网页的重要性。

从PageRank到TextRank的简要介绍
PageRank PageRank部分主要参考bilibili网站的视频,视频讲解的比较清晰易懂,视频目录内容如下: 接下来做简单的几点总结: PageRank的定义和由来 PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由 [1] 根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命

NLP 进行文本摘要的三种策略代码实现和对比:TextRank vs Seq2Seq vs BART
来源:Deephub Imba本文约8400字,建议阅读15分钟本文将使用Python实现和对比解释NLP中的3种不同文本摘要策略。 本文将使用 Python 实现和对比解释 NLP中的3种不同文本摘要策略:老式的 TextRank(使用 gensim)、著名的 Seq2Seq(使基于 tensorflow)和最前沿的 BART(使用Transformers )。 NLP(自然语言处理)

无监督关键词提取算法:TF-IDF、TextRank、RAKE、YAKE、 keyBERT
TF-IDF TF-IDF是一种经典的基于统计的方法,TF(Term frequency)是指一个单词在一个文档中出现的次数,通常一个单词在一个文档中出现的次数越多说明该词越重要。IDF(Inverse document frequency)是所有文档数比上出现某单词的个数,通常一个单词在整个文本集合中出现的文本数越少,这个单词就越能表示其所在文本的特点,重要性就越高;IDF计算一般会再取对数,

Textrank学习
TextRank TextRank 公式在 PageRank 公式的基础上,为图中的边引入了权值的概念: wijwij 就是是为图中节点 ViVi 到 VjVj 的边的权值 。dd 依然为阻尼系数,代表从图中某一节点指向其他任意节点的概率,一般取值为0.85。In(Vi)In(Vi) 和 Out(Vi)Out(Vi) 也和 PageRank 类似,分别为指向节点 ViVi 的节点集合和
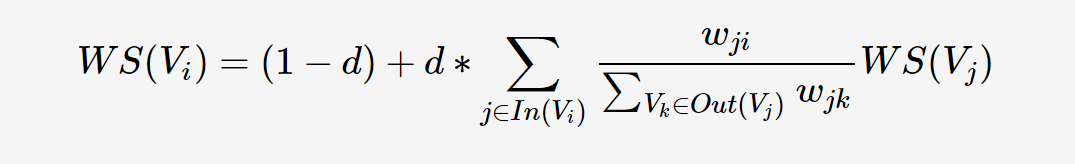
TF-IDF与TextRank
这两个可以说自然语言处理当中比较经典的关键词提取算法,虽然简单,但是应用还是相当广泛,面试中被问起这两个,不能说清楚也是一件很尴尬的事情。废话不多说,直接开始。 1. TF-IDF简介 TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量;用以衡量一个关键词w对于查询(Query,可看作文档)所能提供的信息。

jieba textrank关键词提取 python_教你如何使用python快速提取文章关键词(附源码)
写在前面 如何给文章取一个标题,要贴近文章主题那种?如何给文章提取关键词?即使你能一目十行,过目不忘,也比不上机器“一幕十篇”。接下来介绍一个python项目,经过笔者的改造后,可以方便学习和使用,它能很好、很快地提取文章关键词。 先喝杯咖啡,让我们开始python之旅 环境配置 python版本: 3.6.0 编辑器: pycharm 项目所需要的环境安装包 pip install ji

csdn博客推荐系统实战-6关键词提取-TF-IDF,TEXTRANK
前面几篇写了相似度计算和话题模型,都是怎么找到相似的文章。2篇文章用各种方法向量化,然后余弦计算相似度,或者同在一个话题的2篇文章,把一整篇文章切成很多很多的词,有的模型或算法还要尽量在词多的情况下计算才准确。 人类有归纳总结的能力,看了一篇英超曼城对曼联比赛的报道,会总结几个出几个关键词,英超 曼联 曼城 得比,看了关键词就能知道这篇文章大概的内容,如果机器也能做到,那该多好啊!!!能,当然能
![[yzhpdh多读paper]TextRank: Bringing Order into Texts](https://img-blog.csdnimg.cn/eb239ad4468b40be8e854df90872bf81.png)
[yzhpdh多读paper]TextRank: Bringing Order into Texts
Abstract 在这篇文章中,介绍了一个基于图的文本处理排序模型-TextRank,并且这个模型是如何成功的运用到自然语言应用中的,而且我们提出了两种无监督的关键词与句子抽取算法,并表明与benchmarks上已有结果相比结果更好。 1.introduction略 2.The TextRank Model 基于图的排序算法本质上是一种基于递归地从整个图中提取的全局信息来决定图中某
利用TextRank算法提取摘要关键词以及Java实现
谈起自动摘要算法,常见的并且最易实现的当属TF-IDF,但是感觉TF-IDF效果一般,不如TextRank好。 一. TF-IDF与TextRank 1. TF-IDF简介 TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量;用以衡量一个关键词w对于查询(Query,可看作文档)所能提供的信息。词频(
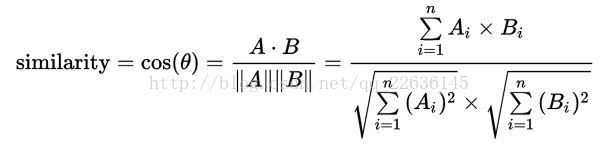
Word2vec+textrank---抽取式摘要生成
原项目地址: https://github.com/ztz818/Automatic-generation-of-text-summaries 相关知识介绍: Word2Vec理论知识:https://blog.csdn.net/Pit3369/article/details/96482304 中文文本关键词抽取的三种方法(TF-IDF、TextRank、word2vec): https://b