本文主要是介绍提取文档关键词——tfidf、textrank,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍的是提取文本关键词的方法,包括tfidf以及textrank
1 tfidf
tfidf内容原理比较简单,先简单讲一下,有空再细化
tfidf分为tf和idf,其中tf指的是词频,idf指的是逆文档频率。tf词频,顾名思义,就是某个词在文档中的出现次数。而idf逆文档频率,则是某个词在多少篇文档中出现过
公式
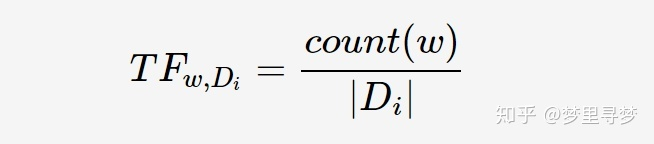
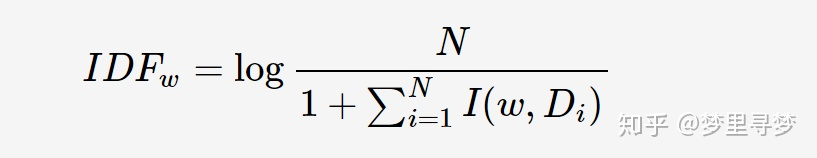
P.S. 分母的加1,起到的是平滑的作用,避免出现某个词在每篇文章里都没出现过,导致分母为0的情况
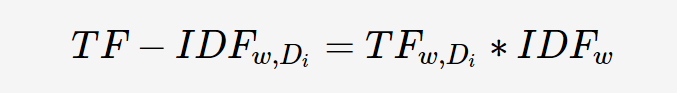
举个例子
假设有100篇文章,其中“”健康状况“仅在一篇文章中出现过,而且在这篇文章里出现了很多次,那么我们认为这个词在这篇文章里的重要性很高。
又如”的“这个字,可能在每篇文章里,都出现了很多次,但我们并不能认为这个词很重要,因为我们不仅要考虑在文章里的出现次数tf,还要考虑在多少篇文章里出现过idf。idf越大,说明这个词是非常常见的,并不是某篇文章所特有的,那么它的重要性就不高
2 textrank
2.1 pagerank
textrank来源于pagerank,所以我们先介绍下pagerank。pagerank的目的是用来计算各个网页的重要性,或者也可以理解为影响力,这与我们想要计算的文档内的关键词(重要性)有些类似之处
以下视频讲的非常清晰,很不错,关于pagerank的部分内容是来自于他的视频。https://www.bilibili.com/video/BV1m4411P76G?p=3&spm_id_from=pageDriver
2.1.1 常规情况


结合上图,我们来解释下这个公式,PR值代表的是网址的重要性,ABCD分别代表几个网址,箭头代表它们之间的链接流向关系。
计算过程:
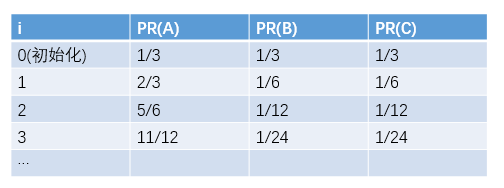
以网址A为例,你可以从网址C和D,进入网址A,同时可以从网址A进入网址B和C,其它以此类推。那么,PR(A)=PR©/2+PR(D)/1,因为C可以去到A和D两个网址,所以除以2,而D只能去到A这一个网址,所以除以1。同理,PR(B)=PR(A)/2,PR©=PR(A)/2+PR(B)/1,PR(D)=PR©/2。接下来,就是不断的循环,PR值就可以得到不断的更新,最终会逐渐稳定, 收敛。另外要注意的是,一开始要对ABCD的PR值做初始化,这里有4个网址,一般是各初始化为1/4
多次迭代的结果如下:

另外,我们可以将上述的网址流向图,用转移矩阵来表示。
下图的44矩阵即为转移矩阵,第一列表示的是A向其它网址的转移概率,以此类推。用转移矩阵初始化状态,得到第一轮结果。然后再用转移矩阵*第一轮结果,得到第二轮结果,以此类推。用转移矩阵计算出来的结果,与我们上面计算的结果,也都是一致的

2.1.2 deadends
所谓deadends,就是有网址,只进不出,最终网址的权重会变为0


以矩阵形式表示

解决方法:teleport
即对转移矩阵进行修正,公式如下

其实我们可以抛开公式,直观上进行理解。B没有出口,那么我们就强行假设B有出口,而且B的出口是其他所有网址,包括它自己。所以我们就可以把转移矩阵中B的那一列,给平均分,B->A是1/3,B->B是1/3,B->C是1/3,就有了如下更新后的转移矩阵。
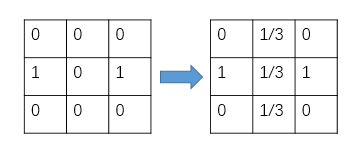
下图是经过修正后的结果

2.1.3 spidertraps
所谓spidertraps,就是有网址,不断的指向自己,同时不指向其他网址,最终这个网址的权重会无限接近于1
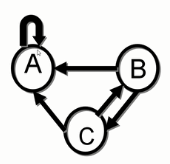
以矩阵形式表示

解决方法:random teleport
即对转移矩阵进行修正,公式如下

我们可以这样理解,只有β的可能性下,遵守上面的转移矩阵。而有1-β的可能性下,每个网址都可能跳到包括自己在内的其他网址,且是等比例的可能性(β一般是0.85)
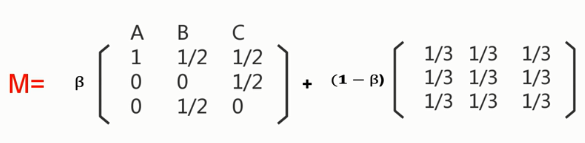
下图是经过修正后的结果

P.S 其实好像通过这种方法,A的权重也在不断上升??只是没有上升那么快??
2.1.4 最终的修正公式

2.1.5 deadends与spidertraps的区别
deadend的修正,只对没有出口的B的概率有影响
spodertraps的修正,对整个转移矩阵都有影响
2.2 textrank
2.2.1 公式介绍
textrank和pagerank其实很类似,我们对比下它们的公式
pagerank
textrank
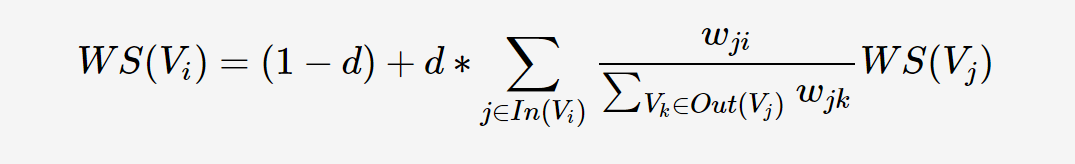
d:类似于pagerank里的β,阻尼系数
WS:类似于pagerank里的PR,指的是词语的重要性
ω那一坨:类似pagerank里的1/L,都是出链占比
2.2.2 原理介绍
1.先对句子进行分词,确定并进行词性的筛选
2.span有点类似于窗口的意思,这里的窗口大小是5。对分词后的句子,窗口从左向右移动。每个窗口,都记录下第一个词,与后面的词共同出现的次数(窗口大小还是要考虑过滤掉的词,共同出现的词则不考虑过滤掉的词)
3.将各个span的词的共同出现次数,都加和到一起(注意,这里只考虑了单向的)

4.考虑到词与词的共现是双向的, 例如“听写”和“提高”出现在同一个窗口中,那么不仅“听写”和“提高”要算一次,“提高”和“听写”也要算一次

然后把词与词间的关系,转化成指向图的形式,可以更直观的加以理解

5.根据上图,计算出各个词的权重
6.进行排序,输出权重为topK的关键词
2.2.3 实战应用
import jieba
import jieba.analyse
sentence = '听写是听写提高英文综合水平最快的方法'
keywords = jieba.analyse.textrank(sentence, topK=4, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v'))
keywords
参数:
topK # 输入几个关键词
withWeight=True # 是否要输出关键词的权重
allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’) # 关键词的词性
[('听写', 1.0),('综合', 0.7342942849328459),('水平', 0.732403185587655),('提高', 0.6964543229955287)]
2.2.4 源码解读
源码位置:…\site-packages\jieba\analyse
import jieba
import jieba.analyse
import sys
from collections import defaultdict
from operator import itemgetter
sentence = '听写是听写提高英文综合水平最快的方法'
# 基本参数
# 允许作为关键词的词性
allowPOS = ('ns', 'n', 'vn', 'v')
pos_filt = frozenset(allowPOS)
#
withFlag = False
# 是否要返回词对应的权重
withWeight = True
# 窗口大小为5
span = 5
# 选取权重最大的4个词
topK = 4
# 英文停用词(在个例子里没用上)
stop_words = set(("the", "of", "is", "and", "to", "in", "that", "we", "for", "an", "are","by", "be", "as", "on", "with", "can", "if", "from", "which", "you", "it","this", "then", "at", "have", "all", "not", "one", "has", "or", "that"))
# 定义一个无向有权图的类
class UndirectWeightedGraph:# 与pagerank一样,d一般取0.85d = 0.85def __init__(self):self.graph = defaultdict(list)def addEdge(self, start, end, weight):# use a tuple (start, end, weight) instead of a Edge objectself.graph[start].append((start, end, weight))self.graph[end].append((end, start, weight))def rank(self):ws = defaultdict(float)outSum = defaultdict(float)wsdef = 1.0 / (len(self.graph) or 1.0)for n, out in self.graph.items():ws[n] = wsdefoutSum[n] = sum((e[2] for e in out), 0.0)# this line for build stable iterationsorted_keys = sorted(self.graph.keys())for x in range(10): # 10 itersfor n in sorted_keys:s = 0for e in self.graph[n]:s += e[2] / outSum[e[1]] * ws[e[1]]ws[n] = (1 - self.d) + self.d * s(min_rank, max_rank) = (sys.float_info[0], sys.float_info[3])# for w in itervalues(ws):for w in ws.values():if w < min_rank:min_rank = wif w > max_rank:max_rank = wfor n, w in ws.items():# to unify the weights, don't *100.ws[n] = (w - min_rank / 10.0) / (max_rank - min_rank / 10.0)return ws
# 用于筛选词性、词长度、非停用词
def pairfilter(wp):return (wp.flag in pos_filt and len(wp.word.strip()) >= 2and wp.word.lower() not in stop_words)
# 2.2.2原理介绍第1点的操作
# jieba分词,以及对应的词性
words = tuple(jieba.posseg.dt.cut(sentence))
words
# (pair('听写', 'v'),
# pair('是', 'v'),
# pair('听写', 'v'),
# pair('提高', 'v'),
# pair('英文', 'nz'),
# pair('综合', 'vn'),
# pair('水平', 'n'),
# pair('最快', 'd'),
# pair('的', 'uj'),
# pair('方法', 'n'))
# 初始化cm,cm用于统计共同出现的词的次数
cm = defaultdict(int)
cm
# defaultdict(int, {})# 2.2.2原理介绍第3点的操作(第2点体现在pairfilter这个函数里)
# 统计共同出现的词的次数
for i, wp in enumerate(words):if pairfilter(wp):for j in range(i + 1, i + span):if j >= len(words):breakif not pairfilter(words[j]):continueif allowPOS and withFlag:cm[(wp, words[j])] += 1else:cm[(wp.word, words[j].word)] += 1
cm
# defaultdict(int,
# {('听写', '听写'): 1,
# ('听写', '提高'): 2,
# ('听写', '综合'): 1,
# ('听写', '水平'): 1,
# ('提高', '综合'): 1,
# ('提高', '水平'): 1,
# ('综合', '水平'): 1,
# ('综合', '方法'): 1,
# ('水平', '方法'): 1})
# 无向有权图的实例化
g = UndirectWeightedGraph()
# UndirectWeightedGraph的__init__定义了一个daultdict
g.graph
# defaultdict(list, {})
# 2.2.2原理介绍第4点的操作
# cm展示的只是单向的共现次数,这一步是把单向的转为双向的
for terms, w in cm.items():g.addEdge(terms[0], terms[1], w)
g.graph
# defaultdict(list,
# {'听写': [('听写', '听写', 1),
# ('听写', '听写', 1),
# ('听写', '提高', 2),
# ('听写', '综合', 1),
# ('听写', '水平', 1)],
# '提高': [('提高', '听写', 2), ('提高', '综合', 1), ('提高', '水平', 1)],
# '综合': [('综合', '听写', 1),
# ('综合', '提高', 1),
# ('综合', '水平', 1),
# ('综合', '方法', 1)],
# '水平': [('水平', '听写', 1),
# ('水平', '提高', 1),
# ('水平', '综合', 1),
# ('水平', '方法', 1)],
# '方法': [('方法', '综合', 1), ('方法', '水平', 1)]})
# 2.2.2原理介绍第5点的操作
# 计算词的权重
nodes_rank = g.rank()
nodes_rank
# defaultdict(float,
# {'听写': 1.0,
# '提高': 0.6964543229955287,
# '综合': 0.7342942849328459,
# '水平': 0.732403185587655,
# '方法': 0.40051227004952517})
因为上面的rank函数比较长,我们还是仔细分析下它是怎么实现的
# 对初始的权重进行初始化,都是一共有5个不同的词:听写、提高、综合、水平、方法,所以每个词都初始化为1/5
ws = defaultdict(float)
outSum = defaultdict(float)
wsdef = 1.0 / (len(g.graph) or 1.0)
wsdef
# 0.2# outSum指的是每个词的出链数,和pagerank的L很像
for n, out in g.graph.items():ws[n] = wsdefoutSum[n] = sum((e[2] for e in out), 0.0)
print('ws:',ws)
print('outSum:',outSum)
# ws: defaultdict(<class 'float'>, {'听写': 0.2, '提高': 0.2, '综合': 0.2, '水平': 0.2, '方法': 0.2})
# outSum: defaultdict(<class 'float'>, {'听写': 6.0, '提高': 4.0, '综合': 4.0, '水平': 4.0, '方法': 2.0})# 计算权重,不断迭代10次
# this line for build stable iteration
d = 0.85
sorted_keys = sorted(g.graph.keys())
for x in range(10): # 10 itersfor n in sorted_keys:s = 0for e in g.graph[n]:s += e[2] / outSum[e[1]] * ws[e[1]]ws[n] = (1 - d) + d * s
ws
# defaultdict(float,
# {'听写': 1.3149571181120283,
# '提高': 0.9328134822499848,
# '综合': 0.9804514548223787,
# '水平': 0.978070687661801,
# '方法': 0.5602422987849102})# python3里的最大浮点数,最小浮点数
(min_rank, max_rank) = (sys.float_info[0], sys.float_info[3])
print(min_rank, max_rank)
# 1.7976931348623157e+308 2.2250738585072014e-308# 寻找ws里的最大值、最小值
# for w in itervalues(ws):
for w in ws.values():if w < min_rank:min_rank = wif w > max_rank:max_rank = w
print(min_rank, max_rank)
# 0.5602422987849102 1.3149571181120283# 把ws里的值进行缩放,压到0-1之间
for n, w in ws.items():# to unify the weights, don't *100.ws[n] = (w - min_rank / 10.0) / (max_rank - min_rank / 10.0)
ws
# defaultdict(float,
# {'听写': 1.0,
# '提高': 0.6964543229955287,
# '综合': 0.7342942849328459,
# '水平': 0.732403185587655,
# '方法': 0.40051227004952517})
# 2.2.2原理介绍第6点的操作
# 对关键词的重要性进行排序
if withWeight:tags = sorted(nodes_rank.items(), key=itemgetter(1), reverse=True)
else:tags = sorted(nodes_rank, key=nodes_rank.__getitem__, reverse=True)
if topK:print(tags[:topK])
else:print(tags)
# [('听写', 1.0), ('综合', 0.7342942849328459), ('水平', 0.732403185587655), ('提高', 0.6964543229955287)]
2.2.5 pagerank和textrank的区别
pagerank:,比如A网址指向B网址,可以是单向,也可以是双向
textrank:所有词之间的关系都是双向的,只要它们处于同一个窗口中
3 tfidf与textrank的区别
1.tfidf需要多篇文章来计算文章里的关键词,而textrank只需要一个句子,就可以计算其中的关键词
2.tfidf在应用时,可以计算出tfidf的矩阵作为X,然后再结合标签y进行有监督学习。而textrank,则是一种无监督学习
4 参考
pagerank介绍:https://www.bilibili.com/video/BV1m4411P76G?p=3&spm_id_from=pageDriver
textrank介绍:https://www.bilibili.com/video/av883388038?p=36
textrank介绍:https://www.bilibili.com/video/BV1P54y1Q7kJ?p=14
textrank介绍:https://zhuanlan.zhihu.com/p/41091116
这篇关于提取文档关键词——tfidf、textrank的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






