tfidf专题

BOW模;型CountVectorizer模型;tfidf模型;
自然语言入门 一、BOW模型:使用一组无序的单词来表达一段文字或者一个文档,并且每个单词的出现都是独立的。在表示文档时是二值(出现1,不出现0); eg: Doc1:practice makes perfect perfect. Doc2:nobody is perfect. Doc1和Doc2作为语料库:词有(practice makes perfect nobody is) Doc
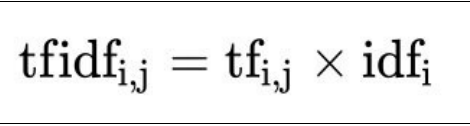

提取文档关键词——tfidf、textrank
本文介绍的是提取文本关键词的方法,包括tfidf以及textrank 1 tfidf tfidf内容原理比较简单,先简单讲一下,有空再细化 tfidf分为tf和idf,其中tf指的是词频,idf指的是逆文档频率。tf词频,顾名思义,就是某个词在文档中的出现次数。而idf逆文档频率,则是某个词在多少篇文档中出现过 公式 P.S. 分母的加1,起到的是平滑的作用,避免出现某个词在每篇文章里都

文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介TFIDF朴素贝叶斯分类器 贝叶斯公式贝叶斯决策论的理解极大似然估计朴素贝叶斯分类器TextRNNTextCNNTextRCNNFastTextHANHighway Networks 简介 通常,进行文本分类的主要方法有三种: 基于规则特征匹配的方法(如根据喜欢,讨厌等特殊词来评判情感,但准确率低,通常作为一种辅助判断的方法)基于传统机器学习的方法(特征工程 + 分类算法
![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 前人栽树后人乘凉,本专栏提供资料: 推荐系统算法库,包含推荐系统经典及最新算法讲解,以及涉及后续业务落地

《自然语言处理学习之路》11 文本特征方法对比-词袋,TFIDF,Word2Vec,神经网络模型
书山有路勤为径,学海无涯苦作舟 一、数据预处理与观测 1.1 数据清洗 社交媒体上有些讨论是关于灾难,疾病,暴乱的,有些只是开玩笑或者是电影情节,我们该如何让机器能分辨出这两种讨论呢? import kerasimport nltkimport pandas as pdimport numpy as npimport reimport codecs 读取数据,并且给行命名
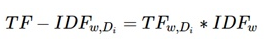
NLP学习笔记(二):创建特征及训练(关键词:词袋,TFIDF)
0. 前言 接上文NLP学习笔记(一) : 数据预处理(词袋),我们已经将数据预处理完成,接下来我们创建一些特征进行训练。 需要提及的是,本次只是单纯的从原始数据中创建特征,未涉及到word embedding(词向量)等操作,也未涉及到n-gram等牵涉到语序的模型。 好的,现在我们已经有了清洗过后的数据,也就是上文预处理完成后的 clean_reviews 这个东西。 接下来我们准备使