本文主要是介绍NLP学习笔记(二):创建特征及训练(关键词:词袋,TFIDF),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 前言
接上文NLP学习笔记(一) : 数据预处理(词袋),我们已经将数据预处理完成,接下来我们创建一些特征进行训练。
需要提及的是,本次只是单纯的从原始数据中创建特征,未涉及到word embedding(词向量)等操作,也未涉及到n-gram等牵涉到语序的模型。
好的,现在我们已经有了清洗过后的数据,也就是上文预处理完成后的 clean_reviews 这个东西。
接下来我们准备使用sklearn的CountVectorizer类进行处理。这是怎么样一个东西呢?
引用官网document:
Convert a collection of text documents to a matrix of token counts
This implementation produces a sparse representation of the counts using scipy.sparse.csr_matrix.
If you do not provide an a-priori dictionary and you do not use an analyzer that does some kind of feature selection then the number of features will be equal to the vocabulary size found by analyzing the data.
简单来说,这个东西就是创建一个矩阵(稀疏),其中的数值是字典中的这个词出现的次数。
那字典又是什么呢?在这里的字典,是由训练数据本身,去掉停用词之后的所有不同词组成的字典。
说起来有点抽象,怎么理解呢?
比如有两句话
- “the fox jump over the box”
- "the fox jump over the lazy dog"
好,现在我们的字典就变成了{the fox jump over box lazy dog}
我们对这两句话分别构造特征向量,特征向量的长度为字典的长度,向量里面每个值为字典里面对应位置的词在该句出现的次数,于是就变成了
- {2, 1, 1, 1, 1, 0, 0}
- {2, 1, 1, 1, 0, 1, 1}
而字典维度的选择,也就是我们特征的维度(max_features),我们常常是选择最常出现的前5000个或更多(去掉停用词后)。
1. 构造特征
接下来我们使用CountVectorizer来创建特征矩阵。
from sklearn.featrue_extraction.text import CountVectorizermax_featrues = 5000vectorizer = CountVectorizer(analyzer = "word",tokenizer = None,preprocessor = None,stop_words = 'english',max_features = max_features)train_df_features = vectorizer.fit_transform(clean_reviews).toarray()train_df_features.shape(25000, 5000)
25000是我们句子的个数,每个句子特征的个数为5000,没问题,我们接着往下走。注意到CountVectorizer也可做一定程度的预处理,如去除停用词,tokenizer(分词)等。
我们现在看下词典的大小以及前20个词
vocab = vectorizer.get_feature_names()len(vocab)5000
没问题,和我们的设置一样,我们设置的词典就是取最常出现的前5000个词(去掉停用词后)。
vocab[:20]['abandoned','abc','abilities','ability','able','abraham','absence','absent','absolute','absolutely','absurd','abuse','abusive','abysmal','academy','accent','accents','accept','acceptable','accepted']
我们可以把最常出现的词打印出来看看
word_counts = np.sum(train_df_features, axis = 0) # 把每行加起来word_count_dict = {}for word, count in zip(vocab, word_counts):word_count_dict.update({word : count}) # 往字典里添加词与次数对sort_list = sorted(word_count_dict.items(), key = lambda item : item[1], reverse = True) # 根据字典的值进行排序,并逆序,返回一个listsort_list[:20] # train_data中最常出现的前20个单词及出现次数[('movie', 44031),('film', 40147),('one', 26788),('like', 20274),('good', 15140),('time', 12724),('even', 12646),('would', 12436),('story', 11983),('really', 11736),('see', 11475),('well', 10662),('much', 9765),('get', 9310),('bad', 9301),('people', 9285),('also', 9156),('first', 9061),('great', 9058),('made', 8362)]
OK,虽然没有进行可视化,不过我们大致了解了最常出现的是些什么样的词。
好,接着我们将测试数据读入
test_df = pd.read_csv("data/testData.tsv", header=0, delimiter="\t",quoting=3 )test_df.shape()test_df.head()(25000, 2)
id review 0 "12311_10" "Naturally in a film who's main themes are of ... 1 "8348_2" "This movie is a disaster within a disaster fi... 2 "5828_4" "All in all, this is a movie for kids. We saw ... 3 "7186_2" "Afraid of the Dark left me with the impressio... 4 "12128_7" "A very accurate depiction of small time mob l...
同样,对用我们开始的函数对数据进行清理
clean_test_reviews = []for i in tqdm(range(0, len(test_df['review']))):clean_test_reviews.append(review2words(test_df['review'][i]))clean_test_reviews[:20]100%|██████████████████████████████████████████████████████████████████████████| 25000/25000 [00:18<00:00, 1360.52it/s]['naturally film main themes mortality nostalgia loss innocence perhaps surprising rated highly older viewers younger ones however craftsmanship completeness film anyone enjoy pace steady constant characters full engaging relationships interactions natural showing need floods tears show emotion screams show fear shouting show dispute violence show anger naturally joyce short story lends film ready made structure perfect polished diamond small changes huston makes inclusion poem fit neatly truly masterpiece tact subtlety overwhelming beauty','movie disaster within disaster film full great action scenes meaningful throw away sense reality let see word wise lava burns steam burns stand next lava diverting minor lava flow difficult let alone significant one scares think might actually believe saw movie even worse significant amount talent went making film mean acting actually good effects average hard believe somebody read scripts allowed talent wasted guess suggestion would movie start tv look away like train wreck awful know coming watch look away spend time meaningful content',...'completely forgot seen within couple days pretty revealing umpteenth version gaston phantom opera leroux locked door country house mystery heard engaging witty update appeared likable title sequence neat touches opening scene film quickly ground halt became vaguely tedious wholly unsatisfying mystery major problem fundamentally unsolvable audience like worst agatha christies depends character appearing final act wealth background information privy film comedy thriller crucial problem characterisation almost non existent exception killer everyone face value version typical suspects typical country house murder story reporter endangered heiress suspicious fianc scatterbrained scientist father surprisingly poor michel lonsdale etc depth little interest frequently ripe misjudged performances help frankly care anyone jeopardy suspense claude rich last reel pierre arditi get anything work last reel film get close sense resonance fleeting really effective rest get endless exposition couple ineffective would comic set pieces promising one photographer trapped inside grandfather clock poorly thought pay dennis podalydes reduced irving explainer last third picture fond country house movies agatha christie style whodunits might cit lot slack found poor show rich says mystery revealed rather something disappointment']
对测试数据构建特征矩阵
test_df_features = vectorizer.transform(clean_test_reviews).toarray()诶,仔细的朋友可能会观察到,你前面的train_df_features,刚刚都是fit_transform(),现在明明是同样的操作,为啥在这儿就是transform()了?
这个问题虽然不是什么大问题,但是建议朋友们读读我的这篇博客,为了搞清楚这个问题,当时我也查了不少资料
关于sklearn里面的fit transform fit_transform的区别(为什么训练集用fit_transform()而测试集用transform()?)
到这里,我们的特征就构建完毕了。当然,还有很多可视化的方法可以对我们的数据进行进一步探索,这里就不再深入了。
2. 训练模型
我们使用随机森林作为模型进行训练,采用网格搜索来寻找最佳参数
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV# 初始化参数
RF = RandomForestClassifier(min_samples_split = 100,min_samples_leaf = 20, max_depth = 8, max_features = 'sqrt', random_state = 10)# 想要搜索的最佳参数 这里设置的范围为(60, 100)每隔10测试一次
grid_values = {'n_estimators' : np.arange(60, 101, 10)}# 网格设置
model_RF = GridSearchCV(estimator = RF, param_grid = grid_values, scoring = 'roc_auc', cv = 5, fit_params={}, iid=True, n_jobs=1, refit=True, verbose=0)# 模型训练
model_RF.fit(train_df_features, train["sentiment"])训练完毕,我们看一下验证集上的得分,这里我的sklearn是0.19,在GridSearchCV上查看得分的属性是grid_scores_,最新版本的请使用cv_results_
model_RF.grid_scores_[mean: 0.90156, std: 0.00582, params: {'n_estimators': 60},mean: 0.90267, std: 0.00553, params: {'n_estimators': 70},mean: 0.90328, std: 0.00512, params: {'n_estimators': 80},mean: 0.90349, std: 0.00507, params: {'n_estimators': 90},mean: 0.90485, std: 0.00486, params: {'n_estimators': 100}]
我设置的是5折交叉验证(前面参数cv = 5),这里的mean就是模型在验证集上f1_score的五个数的平均值,std同理,可以看到当参数'n_estimators': 100时我们的模型在验证集上得分最高,f1_score达到了0.9,看上去还不错,不知道测试集的表现会怎么样。
接下来我们就可以对测试集进行预测了,同时输出为csv标准的提交格式
result = model_df.predict(test_df_features)output = pd.DataFrame( data={"id":test_df["id"], "sentiment":result} )# Use pandas to write the comma-separated output file
output.to_csv( "data/Bag_of_Words_model_RF.csv", index=False, quoting=3 )提交后发现得分只有0.84,不算高的分数。不过咱们的模型应该是最简单的模型,还有很多可以提升的地方,所以这个分数也可以理解啦。我将构建文本特征从CountVectorizer换成了TfidfVectorizer之后得到了一定提升,关于tfidf的构建的话,通俗来说,就是一个词的重要性随着它在数据中出现的频率成正比,同时与它在语料中出现的频率成反比(可以大致理解成我们平时生活中使用的频率)。
从公式的角度来理解TF-IDF:
词频(Term Frequency, TF)表示关键词w在文档Di中出现的频率:
其中count(w)为关键词w的出现次数,|Di|为文档中所有词的数量。
逆文档频率(Inverse Document Frequency, IDF)反映关键词的普遍程度——当一个词越普通(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。IDF定义如下:
N为所有哦文档总数,I(ω,Di)表示文档Di是否包含关键词,若包含则为1,不包含则为0。若词w在文档中均未出现,则IDF公式的分母为0,因此要对IDF做平滑:
则关键词w在文档Di的TF-IDF值为:
但是这样也会带来一个问题,就是生僻词也许对任务没有正面影响,但是由于tf-idf的缘故,会导致其被分配较大的权重,这可能会导致其成为噪点,模型被严重干扰。
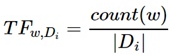
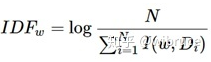
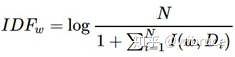
同时,使用不同的算法模型似乎效果会差别很大,我试了朴素贝叶斯接近0.86,逻辑回归能够达到0.89,之前看网上的大神用逻辑回归达到了0.96。。。总的来说,还有很多可以提升的地方,希望大家多多尝试,学以致用才能融会贯通。
这篇关于NLP学习笔记(二):创建特征及训练(关键词:词袋,TFIDF)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






