词袋专题

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出

【Python机器学习】NLP分词——利用分词器构建词汇表(三)——度量词袋之间的重合度
如果能够度量两个向量词袋之间的重合度,就可以很好地估计他们所用词的相似程度,而这也是它们语义上重合度的一个很好的估计。因此,下面用点积来估计一些新句子和原始的Jefferson句子之间的词袋向量重合度: import pandas as pdsentence="""Thomas Jefferson Began buliding Monticelli as the age of 26.\n""

词袋模型两个代码例子
代码1 import numpy as npimport pandas as pdtexts = ['i have a melon','you have a banana','you and i have a melon and a banana']vocabulary = list(enumerate(set([word for sentencein texts for word in s

词袋模型:DBoW原理介绍以及使用方法
1. 词袋模型介绍 词袋模型在很多方面都有应用,其的原理也很容易理解: 有以下一些句子: 1. my name is jack!2. I like to eat apples!3. I am a student!4. I like to take pictures! 我现在交给你一个任务,从上面四句话中找到一句和下面这句话最相似的一句(这里认为同样的单词越多越相似): I am

Python 机器学习 基础 之 处理文本数据 【停用词/用tf-idf缩放数据/模型系数/多个单词的词袋/高级分词/主题建模/文档聚类】的简单说明
Python 机器学习 基础 之 处理文本数据 【停用词/用tf-idf缩放数据/模型系数/多个单词的词袋/高级分词/主题建模/文档聚类】的简单说明 目录 Python 机器学习 基础 之 处理文本数据 【停用词/用tf-idf缩放数据/模型系数/多个单词的词袋/高级分词/主题建模/文档聚类】的简单说明 一、简单介绍 二、停用词 三、用tf-idf缩放数据 四、研究模型系数 五、
Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明
Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明 目录 Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明 一、简单介绍 二、处理文本数据 三、用字符串表示的数据类型 四、示例应用:电影评论的情感分析 五、将文本数据表示为词袋 1、将词袋应用
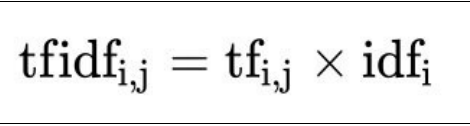
初识人工智能---------自然语言处理词袋模型
1.自然语言处理(NLP) 自然语言处理(Natural Language Processing,简称NLP)研究的是如何通过机器学习等技术,让计算机学会处理自然(人类)语言,以完成有意义的任务。 下面是一些常见的日常生活应用: 1. 邮件过滤: 系统会根据电子邮件的内容识别电子邮件是否属于三个类别(重要、社交或广告)之一,或者判断一封邮件是否是垃圾邮件。此时就是通过NLP来对这些邮件进行

词袋模型(视觉词袋模型BOVW)详解
转自 https://blog.csdn.net/tiandijun/article/details/51143765 引言 最初的Bag of words,也叫做“词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词 是否出现,或者说当这

【OpenCV】基于BoW词袋模型/HoG+SIFT特征提取的图像检索系统
功能介绍 图片检索结果 Image Retrieval精确度和召回率计算调试数据记录(处理效率、特征值、相似度等) 总体思路 输入路径预处理样本库、提取特征值(HoG/SIFT/LBP/Haar-like)读取待检索图片、提取特征值计算TF/IDF词频(Term Frequency/Inverse Document Frequency)遍历样本库、计算相似度排序、取最相似的前topN个结果重
NLP_Bag-Of-Words(词袋模型)
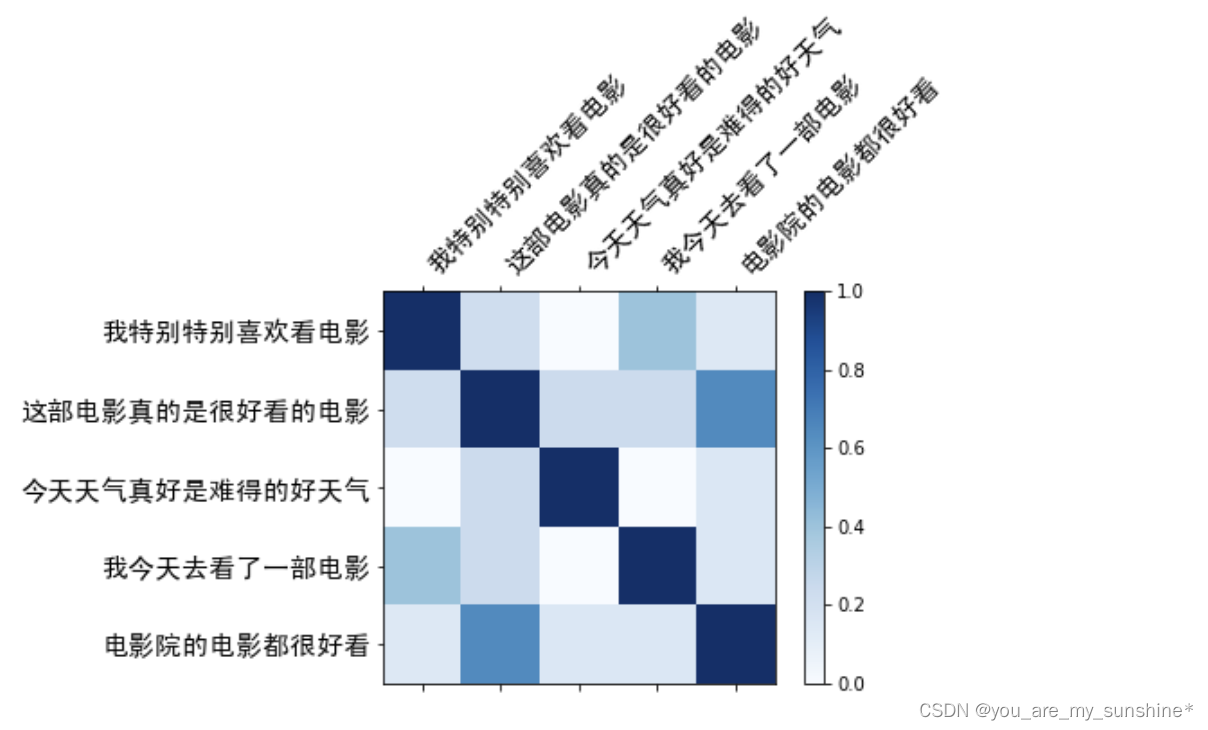
文章目录 词袋模型用词袋模型计算文本相似度1.构建实验语料库2.给句子分词3.创建词汇表4.生成词袋表示5.计算余弦相似度6.可视化余弦相似度 词袋模型小结 词袋模型 词袋模型是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次,如下图所示 用词袋模型计算文本相似度 1.构建实
Python文本向量化入门(三):查看默认词袋
在文本分析和自然语言处理中,将文本数据转换为数值型格式是至关重要的第一步。这有助于我们利用机器学习算法进行更高效的数据分析。Scikit-learn库中的CountVectorizer类是一个非常有用的工具,它可以将文本数据转换为词频矩阵。 首先,我们需要导入所需的库和模块: from sklearn.feature_extraction.text import CountVectorizer

利用Mindspore实现Word2Vec的连续词袋模型(CBOW)和跳词模型(Skip-gram)
前言: 问题:传统的词语的向量表达不能反映词和词之间的相似性和相关语义,且表示维度很长,容易造成维度灾难。(如One-Hot表达一个词,就是初始化一个长度为语料库的向量,并将该词所在位置初始化为1,其他位置均为0,维度很长,且无法反映各个词语之间的关系)因此这种局限导致只能完成一些简单的NLP任务。 措施:于是为了解决这个问题,就不得不提到Word2Vec了,这是NLP领域经
SLAM BOW词袋重定位
visual bag of words 词袋用于SLAM重定位 DBOWBinary featuresImage databaseLoop detectionA. Data base queryB. Matching groupingC. Temporal consistencyD. Efficient geometrical consistency 结果分析 ORBSLAM2 中的Relo
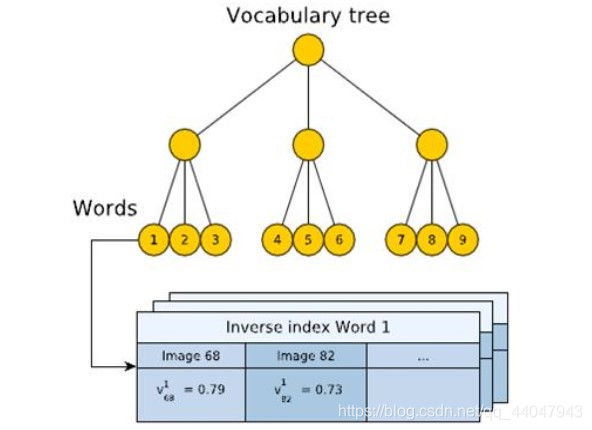
淦ORB-SLAM2源码 03--DBow词袋
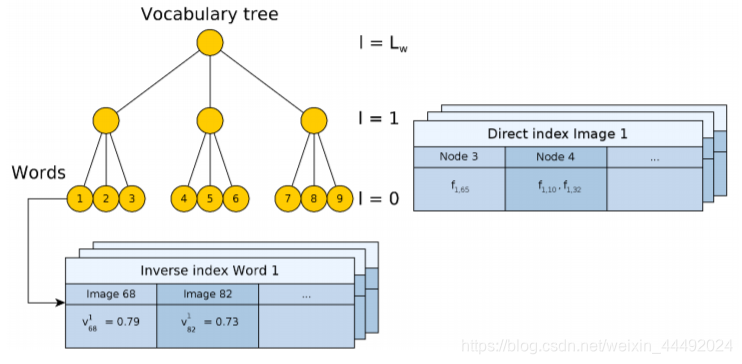
DBow词袋用于ORB-SLAM 词袋模型介绍DBoW的原理创建词汇树使用词汇树每个单词(words)都一样重要吗? ORBSLAM2 中的DBowBinary featuresImage databaseLoop detection 词袋模型介绍 Bag of words模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅

《自然语言处理学习之路》11 文本特征方法对比-词袋,TFIDF,Word2Vec,神经网络模型
书山有路勤为径,学海无涯苦作舟 一、数据预处理与观测 1.1 数据清洗 社交媒体上有些讨论是关于灾难,疾病,暴乱的,有些只是开玩笑或者是电影情节,我们该如何让机器能分辨出这两种讨论呢? import kerasimport nltkimport pandas as pdimport numpy as npimport reimport codecs 读取数据,并且给行命名
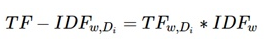
NLP学习笔记(二):创建特征及训练(关键词:词袋,TFIDF)
0. 前言 接上文NLP学习笔记(一) : 数据预处理(词袋),我们已经将数据预处理完成,接下来我们创建一些特征进行训练。 需要提及的是,本次只是单纯的从原始数据中创建特征,未涉及到word embedding(词向量)等操作,也未涉及到n-gram等牵涉到语序的模型。 好的,现在我们已经有了清洗过后的数据,也就是上文预处理完成后的 clean_reviews 这个东西。 接下来我们准备使