本文主要是介绍[yzhpdh多读paper]TextRank: Bringing Order into Texts,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
在这篇文章中,介绍了一个基于图的文本处理排序模型-TextRank,并且这个模型是如何成功的运用到自然语言应用中的,而且我们提出了两种无监督的关键词与句子抽取算法,并表明与benchmarks上已有结果相比结果更好。
1.introduction略
2.The TextRank Model
基于图的排序算法本质上是一种基于递归地从整个图中提取的全局信息来决定图中某个顶点的重要性的方法。
当一个点连接另外一个点,那么被连接的点的分数不仅取决于连接其的节点数量,还取决于去连接的点的重要性。
简单说就是:如果很多单词给单词a投票,说明这个单词a比较重要;一个重要性很高的单词投的票权重也更高
(d是损失因子,
(0,1))它的作用是将图中某个给定顶点跳到另一个随机顶点的概率集成到模型中,d经常取0.85,且这个值也用到这篇论文中)
从分配给图中每个节点的任意值开始,计算迭代,直到达到低于给定阈值的收敛。运行算法后,每个顶点都有一个分数,它代表了图中tex的“重要性”。注意,TextRank运行完成后获得的最终值不受初始值选择的影响,只是收敛的迭代次数可能导致不同结果。
2.1 描述了为什么使用无向图,因为收敛曲线基本相同的
2.2 描述了为什么使用带权图,给出了计算边权的公式,因为同样的结果,在这个任务场景下带权图迭代的次数更少
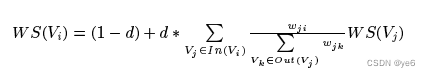
2.3 将文本变成一张图,主要遵循以下几步
1. 确定最能定义手头任务的文本单元,然后把它们作为顶点加到图中。
2. 标识连接这些文本单元的关系使用这些关系来绘制顶点之间的边图中。边可以是有向的也可以是无向的,加权或无关紧要的。
3.迭代基于图的排序算法,直到收敛。
4. 根据顶点的最终分数排序。使用values附加到每个顶点,用于的排名/选择
3 Keyword Extraction
之前有什么关键词提取算法,它们有什么不足,以及介绍了与TextRank算法对比的算法
3.1 抽取关键词
该应用程序的预期最终结果是一组代表给定自然语言文本的单词或短语。因此,要排序的单元是从文本中提取的一个或多个词汇单元的序列,它们表示添加到文本图中的顶点。
使用的是一种共现关系来表示单词之间是否有边,这由单词出现之间的距离控制:如果两个顶点对应的词汇单位在最大单词的窗口内同时出现,则两个顶点是连接的,该窗口可以设置为2到10个单词。它们代表了一个词的衔接和语义之间的联系,代表了语义之间的联系
添加到图中的顶点可以通过语法过滤器进行限制,语法过滤器只选择特定词类的词汇单位。例如,人们可以只考虑名词和动词来添加到图表中,从而仅基于名词和动词之间可以建立的关系来绘制潜在的边。我们试验了各种句法要素,包括:所有开放类词汇、仅名词和动词等,仅名词和形容词的效果最好,详见第3.2节
TextRank关键字提取算法是完全无监督的,具体算法如下:
- 文本被标记后,预处理步骤启用语法过滤器应用程序,为了通过添加由多个词汇单元组成的序列的所有可能组合来避免图大小的过度增长,我们只考虑单个单词作为添加到图的候选单词,并最终在后处理阶段重建多单词的关键字。
- 接下来,所有通过语法过滤器的词汇单元都被添加到图形中,并在单词窗口中同时出现的词汇单元之间添加一条边。构建图(无向无权图)后,与每个顶点相关的分数设置为初始值1,第2节中描述的排序算法在图上运行几次迭代,直到收敛——通常为20-30次迭代,阈值为0.0001。
- 一旦获得图中每个顶点的最终分数,顶点将按分数的相反顺序排序,并重新获得排名靠前的顶点,以便进行后处理。虽然可以设置为任何固定值,通常从5到20个关键字,但我们使用了更灵活的方法,根据文本大小决定关键字的数量。因为我们实验中使用的数据由相对较短的摘要组成,被设置为图中顶点数的三分之一
- 在后处理过程中,TextRank算法选择为潜在关键字的所有词汇单元都会在文本中进行标记,相邻关键字的序列会折叠成一个多单词关键字。
例如有 matlab code两个都是关键词,那么就会把这两个词合为一个
evaluation
TextRank在precision与F measure方面取得了最好的表现,但在回归方面没有比有监督方法好,且窗口越大多结果的帮助也不是很大。且考虑词性信息有助于关键词提取过程
conclusion
TextRank的一个重要方面是,它不需要深入的语言知识,也不需要特定领域或特定语言的注释语料库,这使得它可以高度移植到其他领域、体裁或语言。
新概念
F-Measure(摘自百度
F-Measure是Precision和Recall加权调和平均,是IR(信息检索)领域的常用的一个评价标准,常用于评价分类模型的好坏。在f-measure函数中,当参数α=1时,F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
这篇关于[yzhpdh多读paper]TextRank: Bringing Order into Texts的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


