tensorrt专题

tensorrt 下载地址
tensorrt 下载地址 https://developer.nvidia.com/tensorrt refer: https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html

yolov8-obb旋转目标检测onnxruntime和tensorrt推理
onnxruntime推理 导出onnx模型: from ultralytics import YOLOmodel = YOLO("yolov8n-obb.pt") model.export(format="onnx") onnx模型结构如下: python推理代码: import cv2import mathimport numpy as npimport onnxr

CUDA与TensorRT学习三:TensorRT基础入门
文章目录 一、TensorRT概述二、TensorRT应用场景三、TensorRT模块四、导出并分析ONNX五、剖析ONNX架构并理解Protobuf六、ONNX注册算子的方法七、快速分析开源代码并导出ONNX八、使用trtexec九、trtexec log分析 一、TensorRT概述 二、TensorRT应用场景 三、TensorRT模块 四、导出并分析ONNX 五、

tensorrt plugin
自定义plugin 流程 首先明确要开发的算子,最好是 CUDA 实现;继承 IPluginV2DynamicExt / IPluginV2IOExt类实现一个Plugin 类,在这里调用前面实现的算子;继承 IPluginCreator 类实现一个 PluginCreator 类,用于创建插件实例,然后注册该 Creator 类;编译插件项目,生成动态链接库;在构造 engine 之前,

TensorRT模型量化实践
文章目录 量化基本概念量化的方法方式1:trtexec(PTQ的一种)方式2:PTQ2.1 python onnx转trt2.2 polygraphy工具:应该是对2.1量化过程的封装 方式3:QAT(追求精度时推荐) 使用TensorRT量化实践(C++版)使用TensorRT量化(python版)参考文献 量化基本概念 后训练量化Post Training Quan

Pytorch添加自定义算子之(12)-开闭原则设计tensorrt和onnxruntime推理语义分割模型
一、开闭原则 开闭原则是SOLID原则中的一个,指的是尽量使用开放扩展,关闭修改的设计原则。 在C++中如何使用开闭原则导出动态库,可以按照以下步骤进行: 定义抽象基类:定义动态库中的抽象基类,该基类应该封装可扩展的接口。 实现派生类:实现基类的派生类,这些派生类将封装对应的扩展接口。 将派生类编译为动态库:将所有派生类编译为动态库(DLL)。 使用动态库:在使用动态库的代码中,只需包

tensorRT C++使用pt转engine模型进行推理
目录 1. 前言2. 模型转换3. 修改Binding4. 修改后处理 1. 前言 本文不讲tensorRT的推理流程,因为这种文章很多,这里着重讲从标准yolov5的tensort推理代码(模型转pt->wts->engine)改造成TPH-yolov5(pt->onnx->engine)的过程。 2. 模型转换 请查看上一篇文章https://blog.csdn.net/
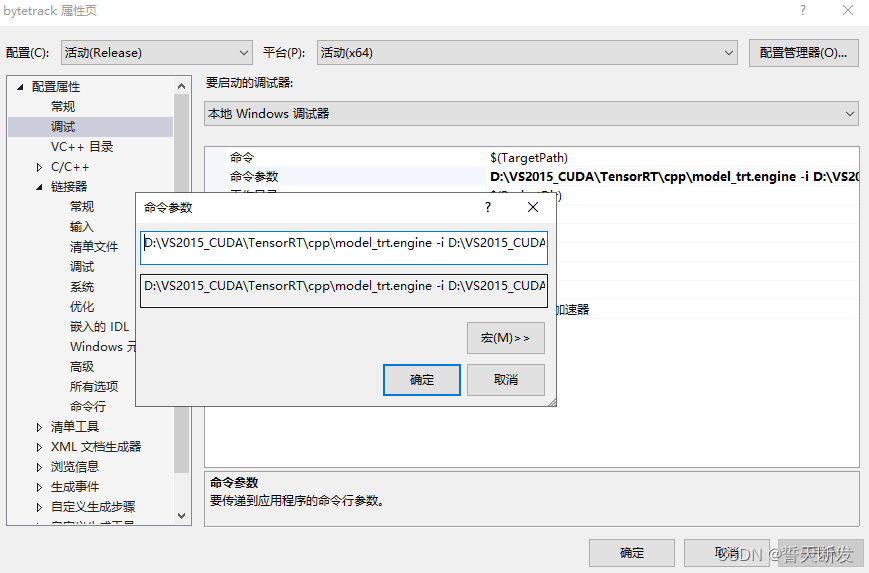
目标跟踪算法(bytetrack)-tensorrt部署教程
一、本机安装python环境 conda create -n bytetrace_env python=3.8activate bytetrace_envconda install pytorch torchvision cudatoolkit=10.1 -c 检测GPU是否可用,不可用不行 import torchprint(torch.cuda.is_available())

【深度学习】TensorRT模型转换环境
Ubuntu 22.04 LTS、Cuda 12.3、Tensorrt 8.6.1、Python 3.10、A10G GPU 要在 Ubuntu 22.04 LTS 上使用 TensorRT 将模型转换为 TensorRT 格式,您需要安装一些必要的环境和依赖项。以下是详细的步骤: 更新系统: sudo apt updatesudo apt upgrade 安装 CUDA 12.3:
用TensorRT-LLM进行LLama的推理和部署
Deploy an AI Coding Assistant with NVIDIA TensorRT-LLM and NVIDIA Triton | NVIDIA Technical BlogQuick Start Guide — tensorrt_llm documentation (nvidia.github.io) 使用TensorRT-LLM的源码,来下载docker并在docker里编
[C#]使用C#部署yolov10的目标检测tensorrt模型
【测试通过环境】 win10 x64vs2019 cuda11.7+cudnn8.8.0 TensorRT-8.6.1.6 opencvsharp==4.9.0 .NET Framework4.7.2 NVIDIA GeForce RTX 2070 Super cuda和tensorrt版本和上述环境版本不一样的需要重新编译TensorRtExtern.dll,TensorRtExtern源

【tensorrt】——双线性上采样插件(提供源码)
简介: 如果用nvidia的gpu,在推理的时候,采用tensorrt进行加速是一个很好的选择,虽然tensorrt没有开源。 我一般选择的模型训练到部署的流程是: pytorch训练模型onnx模型导出onnx模型转ncnn,mnn,tensorrt等模型嵌入式推理框架,推理脚本书写。 这里用tensorrt做语义分割网络pspnet的推理加速。技术路线采用:pytorch——onn
【onnx-tensorrt】——源码阅读记录
个人记录 tensorrt自定义插件层 getOutputDimensions的调用接口 新定义的层需要定义getOutputDimensions方法,那这个是在供哪里调用的呢?接口的参数又是? nvinfer1::Dims ResizeBilinearPlugin::getOutputDimensions(int index,const nvinfer1::Dims *inputDims,
【tensorrt】——batch推理对比
关键词:tensorrt, int8, float16,batch推理 该测试结果有问题,正确的测试请移步:【tensorrt】——trtexec动态batch支持与batch推理耗时评测 int8量化,这篇文章中nvidia tensorrt的int8推理在batch大的时候有推理速度的提升,这里实测一下。 采用float16精度的ddrnet23模型,tensorrt的python

【tensorrt】——int8量化
转载自:https://arleyzhang.github.io/articles/923e2c40/ tensorrt int8量化的流程可参考:【tensorrt】——int8量化过程浅析/对比 1 Low Precision Inference 现有的深度学习框架 比如:TensorFlow,Caffe, MixNet等,在训练一个深度神经网络时,往往都会使用 float 32(
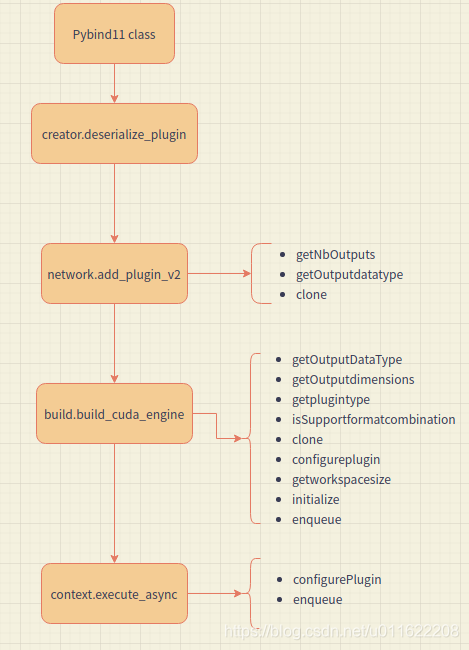
【tensorrt】——插件写法及python plugin大体流程
tensorrt 1. python plugin 大体流程 这是参考torch2trt写的一个python插件的大体流程,因为tensorrt是没有开源的,所以具有不确定性。 2. code 项目,是做tensorrt测试的,包括c++/python api。因为tensorrt模型的构建不是api就是转换模型之后直接推理。如果想单独测试某个layer就需要这样的小项目。 te

【tensorrt】——could not find any supported formats consistent with input/output data types
tensorrt 在supportsFormatCombination函数中需要返回true bool supportsFormatCombination(int pos,const nvinfer1::PluginTensorDesc *inOut,int nbInputs, int nbOutputs) override{cout << "in support format co
【tensorrt】——error: invalid new-expression of abstract class type ‘torch2trt::InterpolatePlugin’
tensorrt 给tensorrt写插件的时候,报错: interpolate.cpp:63:93: error: invalid new-expression of abstract class type ‘torch2trt::InterpolatePlugin’ 因为还有父类的虚函数没有实现。 可以通过一个简单的类实现进行测试,所有的函数不需要实现,这样看有哪些虚函数。比如
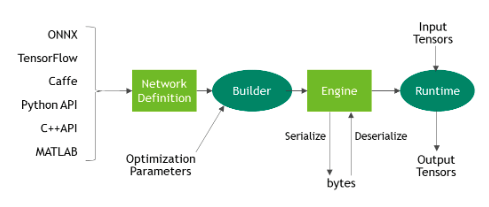
【tensorrt】——最全官方文档
tensorrt 链接:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#layers tensorrt apitensorrt python api
【tensorrt】——tensorrt7.2.2.3插件书写问题
tensorrt 1. 问题1 /home/darknet/CM/profile/TensorRT-7.2.2.3/include/NvInferRuntime.h:665:12: error: overriding final function ‘virtual size_t nvinfer1::IPluginV2DynamicExt::getWorkspaceSize(int32_t
【tensorrt】——PluginV2Layer must be V2Ext or V2IOExt or V2DynamicExt when there is no implicit batch d
tensorrt 1. tensorrt插件 用c++为tensorrt写了插件,继承自IPluginV2用pybind11进行python注册 namespace torch2trt {PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {py::class_<InterpolatePlugin>(m, "InterpolatePlugin")
[深度学习]使用python转换pt并部署yolov10的tensorrt模型封装成类几句完成目标检测加速任务
【简单介绍】 使用Python将YOLOv10模型从PyTorch格式(.pt)转换为TensorRT格式,并通过封装成类来实现目标检测加速任务,是一个高效且实用的流程。以下是该过程的简要介绍: 模型转换: 利用官方提供导出命令,将训练好的YOLOv10模型(.pt格式)转换为tensorrt模型。利用NVIDIA的TensorRT框架,将ONNX模型转换为TensorRT引擎,以优化在NVI

MMdeploy在cuda+tensorrt下的配置和编译
MMdeploy在cuda+tensorrt下的配置和编译 Python安装配置MMdeploy配置openmmlab系列从工程安装mmdeploy MMdeploy_runtime以及demo编译安装量化编译runtime和demo Python安装配置MMdeploy 配置openmmlab系列 pip install -U openmim 如果mim命令遭遇故障,
tensorRT 自定义算子plugin的实现
文章目录 1. 自定义算子导出onnx1.1 自定义算子的实现类1.2 自定义算子类1.3 onnx导出 2. 自定义算子plugin的实现2.1 Plugin类的实现2.1.1 构造函数的实现2.1.2 析构函数实现2.1.3 serialize函数的实现2.1.4 destory函数的实现2.1.5 enqueue函数的实现(关键)2.1.5.1 customScalarImpl核函数的
TensorRT教程(1)初探TensorRT
1. TensorRT简要介绍 TensorRT(NVIDIA TensorRT)是 NVIDIA 开发的一个用于深度学习推理的高性能推理引擎。它可以针对 NVIDIA GPU 进行高效的深度学习推理加速,提供了许多优化技术,使得推理速度更快,并且可以在生产环境中部署。 下面是 TensorRT 的一些主要特点和功能: 高性能推理:Tensor

tensorrt输出结果为nan的解决方案
系统环境: ubuntu20.04 python3.9 cuda11.8 cudnn8.9.7.29 1.针对cuda版本查了一下trt支持版本,发现V10和V8版本都支持 本着用新不用旧标准,果断下载了8.6,torch-->onnx-->engine转换过程均没问题,但测试发现engine输出的结果全为nan! 解决: 1.查看了tensorrt的issues,在这一个下