本文主要是介绍目标跟踪算法(bytetrack)-tensorrt部署教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、本机安装python环境
conda create -n bytetrace_env python=3.8
activate bytetrace_env
conda install pytorch torchvision cudatoolkit=10.1 -c
检测GPU是否可用,不可用不行
import torch
print(torch.cuda.is_available())
安装bytetrack
git clone https://github.com/ifzhang/ByteTrack.git
cd ByteTrack
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python setup.py develop

上述即安装成功。
安装pycocotools
pip install cython
pip install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
或者(Linux)
pip install git+https://gitee.com/pursuit_zhangyu/cocoapi.git#subdirectory=PythonAPI
windows下
pip install pycocotools-windows
二、安装tensorrt环境
下载tensorrt包
TensorRT-8.4.3.1.Windows10.x86_64.cuda-10.2.cudnn8.4.zip

将所有的dll复制到
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin
并设置环境变量。
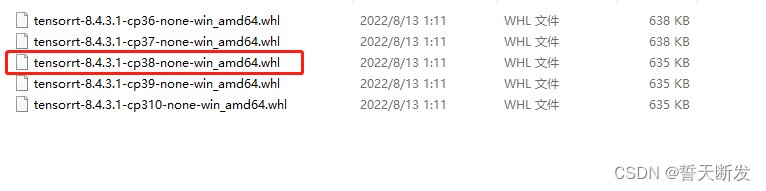
虚拟环境中python版本为python3.8
pip install tensorrt-8.4.3.1-cp38-none-win_amd64.whl
三、转换模型
https://pan.baidu.com/s/1PiP1kQfgxAIrnGUbFP6Wfg
qflm
获取bytetrack_s_mot17.pth.tar并创建pretrained进行存放
python tools/trt.py -f exps/example/mot/yolox_s_mix_det.py -c pretrained/bytetrack_s_mot17.pth.tar
最后在D:\git_clone\ByteTrack-main\YOLOX_outputs\yolox_s_mix_det目录下生成tensorrt模型与pth模型:

四、cmake生成eigen库并使用VS2015编译
https://pan.baidu.com/s/15kEfCxpy-T7tz60msxxExg
ueq4




五、下载opencv450
https://nchc.dl.sourceforge.net/project/opencvlibrary/4.5.0/opencv-4.5.0-vc14_vc15.exe?viasf=1
安装D:\opencv450
六、cmake生成bytetrack并使用VS2015编译
修改CMakeLists.txt
cmake_minimum_required(VERSION 2.6)project(bytetrack)add_definitions(-std=c++11)option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)find_package(CUDA REQUIRED)include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(D:\VS2015_CUDA\TensorRT\eigen-3.3.9\build\install\include\eigen3)
link_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
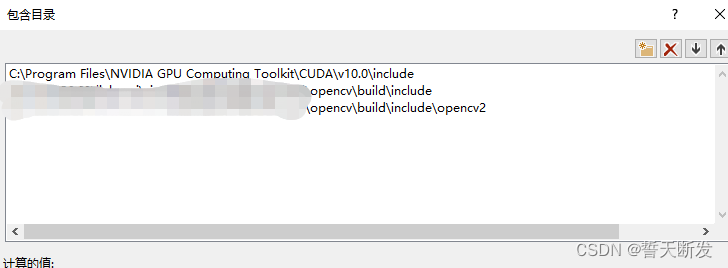
include_directories(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include)
link_directories(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64)
# cudnn
include_directories(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include)
link_directories(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64)
# tensorrt
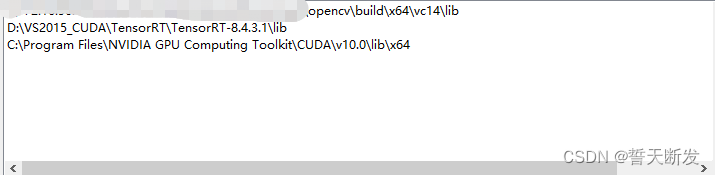
include_directories(D:\VS2015_CUDA\TensorRT\TensorRT-8.4.3.1\include)
link_directories(D:\VS2015_CUDA\TensorRT\TensorRT-8.4.3.1\lib)set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -D_MWAITXINTRIN_H_INCLUDED")set(OpenCV_INCLUDE_DIRS_DIRS D:\opencv450\build\include)
set(OpenCV_LIBS D:\opencv450\build\x64\vc14\lib)
include_directories(${OpenCV_INCLUDE_DIRS})file(GLOB My_Source_Files ${PROJECT_SOURCE_DIR}/src/*.cpp)
add_executable(bytetrack ${My_Source_Files})
target_link_libraries(bytetrack nvinfer)
target_link_libraries(bytetrack cudart)
target_link_libraries(bytetrack ${OpenCV_LIBS})add_definitions(-O2 -pthread)
使用CMake进行配置生成。
打开VS2015工程进行配置

opencv可以自己加进去编译。

修改bytetrack.cpp
int img_w = cap.get(cv::CAP_PROP_FRAME_WIDTH);
int img_h = cap.get(cv::CAP_PROP_FRAME_HEIGHT);
这里有个bug,高的参数不对,会影响后面的demo.mp4。
编译生成

七、使用Dependency Walker查看exe依赖

D:\VS2015_CUDA\TensorRT\cpp\model_trt.engine -i D:\VS2015_CUDA\TensorRT\cpp\palace.mp4
八、windows源码
bytetrack.cpp
#include <fstream>
#include <iostream>
#include <sstream>
#include <numeric>
#include <chrono>
#include <vector>
#include <opencv2/opencv.hpp>
#include "NvInfer.h"
#include "cuda_runtime_api.h"
#include "logging.h"
#include "BYTETracker.h"#define CHECK(status) \do\{\auto ret = (status);\if (ret != 0)\{\cerr << "Cuda failure: " << ret << endl;\abort();\}\} while (0)#define DEVICE 0 // GPU id
#define NMS_THRESH 0.7
#define BBOX_CONF_THRESH 0.1using namespace nvinfer1;// stuff we know about the network and the input/output blobs
static const int INPUT_W = 1088;
static const int INPUT_H = 608;
const char* INPUT_BLOB_NAME = "input_0";
const char* OUTPUT_BLOB_NAME = "output_0";
static Logger gLogger;Mat static_resize(Mat& img) {float r = min(INPUT_W / (img.cols*1.0), INPUT_H / (img.rows*1.0));// r = std::min(r, 1.0f);int unpad_w = r * img.cols;int unpad_h = r * img.rows;Mat re(unpad_h, unpad_w, CV_8UC3);resize(img, re, re.size());Mat out(INPUT_H, INPUT_W, CV_8UC3, Scalar(114, 114, 114));re.copyTo(out(Rect(0, 0, re.cols, re.rows)));return out;
}struct GridAndStride
{int grid0;int grid1;int stride;
};static void generate_grids_and_stride(const int target_w, const int target_h, vector<int>& strides, vector<GridAndStride>& grid_strides)
{for (auto stride : strides){GridAndStride GS;int num_grid_w = target_w / stride;int num_grid_h = target_h / stride;for (int g1 = 0; g1 < num_grid_h; g1++){for (int g0 = 0; g0 < num_grid_w; g0++){GS.grid0 = g0;GS.grid1 = g1;GS.stride = stride;grid_strides.push_back(GS);}}}
}static inline float intersection_area(const Object& a, const Object& b)
{Rect_<float> inter = a.rect & b.rect;return inter.area();
}static void qsort_descent_inplace(vector<Object>& faceobjects, int left, int right)
{int i = left;int j = right;float p = faceobjects[(left + right) / 2].prob;while (i <= j){while (faceobjects[i].prob > p)i++;while (faceobjects[j].prob < p)j--;if (i <= j){// swapswap(faceobjects[i], faceobjects[j]);i++;j--;}}#pragma omp parallel sections{#pragma omp section{if (left < j) qsort_descent_inplace(faceobjects, left, j);}#pragma omp section{if (i < right) qsort_descent_inplace(faceobjects, i, right);}}
}static void qsort_descent_inplace(vector<Object>& objects)
{if (objects.empty())return;qsort_descent_inplace(objects, 0, objects.size() - 1);
}static void nms_sorted_bboxes(const vector<Object>& faceobjects, vector<int>& picked, float nms_threshold)
{picked.clear();const int n = faceobjects.size();vector<float> areas(n);for (int i = 0; i < n; i++){areas[i] = faceobjects[i].rect.area();}for (int i = 0; i < n; i++){const Object& a = faceobjects[i];int keep = 1;for (int j = 0; j < (int)picked.size(); j++){const Object& b = faceobjects[picked[j]];// intersection over unionfloat inter_area = intersection_area(a, b);float union_area = areas[i] + areas[picked[j]] - inter_area;// float IoU = inter_area / union_areaif (inter_area / union_area > nms_threshold)keep = 0;}if (keep)picked.push_back(i);}
}static void generate_yolox_proposals(vector<GridAndStride> grid_strides, float* feat_blob, float prob_threshold, vector<Object>& objects)
{const int num_class = 1;const int num_anchors = grid_strides.size();for (int anchor_idx = 0; anchor_idx < num_anchors; anchor_idx++){const int grid0 = grid_strides[anchor_idx].grid0;const int grid1 = grid_strides[anchor_idx].grid1;const int stride = grid_strides[anchor_idx].stride;const int basic_pos = anchor_idx * (num_class + 5);// yolox/models/yolo_head.py decode logicfloat x_center = (feat_blob[basic_pos+0] + grid0) * stride;float y_center = (feat_blob[basic_pos+1] + grid1) * stride;float w = exp(feat_blob[basic_pos+2]) * stride;float h = exp(feat_blob[basic_pos+3]) * stride;float x0 = x_center - w * 0.5f;float y0 = y_center - h * 0.5f;float box_objectness = feat_blob[basic_pos+4];for (int class_idx = 0; class_idx < num_class; class_idx++){float box_cls_score = feat_blob[basic_pos + 5 + class_idx];float box_prob = box_objectness * box_cls_score;if (box_prob > prob_threshold){Object obj;obj.rect.x = x0;obj.rect.y = y0;obj.rect.width = w;obj.rect.height = h;obj.label = class_idx;obj.prob = box_prob;objects.push_back(obj);}} // class loop} // point anchor loop
}float* blobFromImage(Mat& img){cvtColor(img, img, COLOR_BGR2RGB);float* blob = new float[img.total()*3];int channels = 3;int img_h = img.rows;int img_w = img.cols;vector<float> mean = {0.485f, 0.456f, 0.406f};vector<float> std = {0.229f, 0.224f, 0.225f};for (size_t c = 0; c < channels; c++) {for (size_t h = 0; h < img_h; h++) {for (size_t w = 0; w < img_w; w++) {blob[c * img_w * img_h + h * img_w + w] =(((float)img.at<Vec3b>(h, w)[c]) / 255.0f - mean[c]) / std[c];}}}return blob;
}static void decode_outputs(float* prob, vector<Object>& objects, float scale, const int img_w, const int img_h) {vector<Object> proposals;vector<int> strides = {8, 16, 32};vector<GridAndStride> grid_strides;generate_grids_and_stride(INPUT_W, INPUT_H, strides, grid_strides);generate_yolox_proposals(grid_strides, prob, BBOX_CONF_THRESH, proposals);//std::cout << "num of boxes before nms: " << proposals.size() << std::endl;qsort_descent_inplace(proposals);vector<int> picked;nms_sorted_bboxes(proposals, picked, NMS_THRESH);int count = picked.size();//std::cout << "num of boxes: " << count << std::endl;objects.resize(count);for (int i = 0; i < count; i++){objects[i] = proposals[picked[i]];// adjust offset to original unpaddedfloat x0 = (objects[i].rect.x) / scale;float y0 = (objects[i].rect.y) / scale;float x1 = (objects[i].rect.x + objects[i].rect.width) / scale;float y1 = (objects[i].rect.y + objects[i].rect.height) / scale;// clip// x0 = std::max(std::min(x0, (float)(img_w - 1)), 0.f);// y0 = std::max(std::min(y0, (float)(img_h - 1)), 0.f);// x1 = std::max(std::min(x1, (float)(img_w - 1)), 0.f);// y1 = std::max(std::min(y1, (float)(img_h - 1)), 0.f);objects[i].rect.x = x0;objects[i].rect.y = y0;objects[i].rect.width = x1 - x0;objects[i].rect.height = y1 - y0;}
}const float color_list[80][3] =
{{0.000, 0.447, 0.741},{0.850, 0.325, 0.098},{0.929, 0.694, 0.125},{0.494, 0.184, 0.556},{0.466, 0.674, 0.188},{0.301, 0.745, 0.933},{0.635, 0.078, 0.184},{0.300, 0.300, 0.300},{0.600, 0.600, 0.600},{1.000, 0.000, 0.000},{1.000, 0.500, 0.000},{0.749, 0.749, 0.000},{0.000, 1.000, 0.000},{0.000, 0.000, 1.000},{0.667, 0.000, 1.000},{0.333, 0.333, 0.000},{0.333, 0.667, 0.000},{0.333, 1.000, 0.000},{0.667, 0.333, 0.000},{0.667, 0.667, 0.000},{0.667, 1.000, 0.000},{1.000, 0.333, 0.000},{1.000, 0.667, 0.000},{1.000, 1.000, 0.000},{0.000, 0.333, 0.500},{0.000, 0.667, 0.500},{0.000, 1.000, 0.500},{0.333, 0.000, 0.500},{0.333, 0.333, 0.500},{0.333, 0.667, 0.500},{0.333, 1.000, 0.500},{0.667, 0.000, 0.500},{0.667, 0.333, 0.500},{0.667, 0.667, 0.500},{0.667, 1.000, 0.500},{1.000, 0.000, 0.500},{1.000, 0.333, 0.500},{1.000, 0.667, 0.500},{1.000, 1.000, 0.500},{0.000, 0.333, 1.000},{0.000, 0.667, 1.000},{0.000, 1.000, 1.000},{0.333, 0.000, 1.000},{0.333, 0.333, 1.000},{0.333, 0.667, 1.000},{0.333, 1.000, 1.000},{0.667, 0.000, 1.000},{0.667, 0.333, 1.000},{0.667, 0.667, 1.000},{0.667, 1.000, 1.000},{1.000, 0.000, 1.000},{1.000, 0.333, 1.000},{1.000, 0.667, 1.000},{0.333, 0.000, 0.000},{0.500, 0.000, 0.000},{0.667, 0.000, 0.000},{0.833, 0.000, 0.000},{1.000, 0.000, 0.000},{0.000, 0.167, 0.000},{0.000, 0.333, 0.000},{0.000, 0.500, 0.000},{0.000, 0.667, 0.000},{0.000, 0.833, 0.000},{0.000, 1.000, 0.000},{0.000, 0.000, 0.167},{0.000, 0.000, 0.333},{0.000, 0.000, 0.500},{0.000, 0.000, 0.667},{0.000, 0.000, 0.833},{0.000, 0.000, 1.000},{0.000, 0.000, 0.000},{0.143, 0.143, 0.143},{0.286, 0.286, 0.286},{0.429, 0.429, 0.429},{0.571, 0.571, 0.571},{0.714, 0.714, 0.714},{0.857, 0.857, 0.857},{0.000, 0.447, 0.741},{0.314, 0.717, 0.741},{0.50, 0.5, 0}
};void doInference(IExecutionContext& context, float* input, float* output, const int output_size, Size input_shape) {const ICudaEngine& engine = context.getEngine();// Pointers to input and output device buffers to pass to engine.// Engine requires exactly IEngine::getNbBindings() number of buffers.assert(engine.getNbBindings() == 2);void* buffers[2];// In order to bind the buffers, we need to know the names of the input and output tensors.// Note that indices are guaranteed to be less than IEngine::getNbBindings()const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);assert(engine.getBindingDataType(inputIndex) == nvinfer1::DataType::kFLOAT);const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);assert(engine.getBindingDataType(outputIndex) == nvinfer1::DataType::kFLOAT);int mBatchSize = engine.getMaxBatchSize();// Create GPU buffers on deviceCHECK(cudaMalloc(&buffers[inputIndex], 3 * input_shape.height * input_shape.width * sizeof(float)));CHECK(cudaMalloc(&buffers[outputIndex], output_size*sizeof(float)));// Create streamcudaStream_t stream;CHECK(cudaStreamCreate(&stream));// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to hostCHECK(cudaMemcpyAsync(buffers[inputIndex], input, 3 * input_shape.height * input_shape.width * sizeof(float), cudaMemcpyHostToDevice, stream));context.enqueue(1, buffers, stream, nullptr);CHECK(cudaMemcpyAsync(output, buffers[outputIndex], output_size * sizeof(float), cudaMemcpyDeviceToHost, stream));cudaStreamSynchronize(stream);// Release stream and bufferscudaStreamDestroy(stream);CHECK(cudaFree(buffers[inputIndex]));CHECK(cudaFree(buffers[outputIndex]));
}int main(int argc, char** argv) {cudaSetDevice(DEVICE);// create a model using the API directly and serialize it to a streamchar *trtModelStream{nullptr};size_t size{0};if (argc == 4 && string(argv[2]) == "-i") {const string engine_file_path {argv[1]};ifstream file(engine_file_path, ios::binary);if (file.good()) {file.seekg(0, file.end);size = file.tellg();file.seekg(0, file.beg);trtModelStream = new char[size];assert(trtModelStream);file.read(trtModelStream, size);file.close();}} else {cerr << "arguments not right!" &这篇关于目标跟踪算法(bytetrack)-tensorrt部署教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







