task4专题

【Datawhale X 魔搭 】AI夏令营第四期大模型方向,Task4:源大模型微调实战(持续更新)
1.1 大模型微调技术简介 模型微调也被称为指令微调(Instruction Tuning)或者有监督微调(Supervised Fine-tuning, SFT),该方法利用成对的任务输入与预期输出数据,训练模型学会以问答的形式解答问题,从而解锁其任务解决潜能。经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。

Datawhale-爬虫-Task4(学习xpath)
学习内容 XPath简介lxml简介实例:使用xpath提取丁香园论坛的回复内容。 XPath简介 XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。 什么是XPath? XPath 使用路径表达式在 XML 文档中进行导航 XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规

【无标题】天池机器学习task4
集合运算-表的加减法和join等 1、表的加减法 集合在数学领域表示“各种各样的事物的总和”, 在数据库领域表示记录的集合。具体来说,表、视图和查询的执行结果都是记录的集合, 其中的元素为表或者查询结果中的每一行。 在标准 SQL 中, 分别对检索结果使用 UNION, INTERSECT, EXCEPT 来将检索结果进行并,交和差运算, 像UNION,INTERSECT, EXCEPT这种用来
【RL】(task4)DDPG算法、TD3算法
note 文章目录 note一、DDPG算法二、TD3算法时间安排Reference 一、DDPG算法 DDPG(Deep Deterministic Policy Gradient)算法 DDPG算法是一种结合了深度学习和确定性策略梯度的算法。它主要解决的是在连续动作空间中,智能体(agent)如何通过不断尝试来学习到一个最优策略,使得在与环境交互的过程中获得最大的回报。

【天池——街景字符识别】Task4 模型训练与验证
文章目录 构造验证集模型训练与验证模型保存与加载模型调参流程 一个成熟合格的深度学习训练流程至少具备以下功能: 在训练集上进行训练,并在验证集上进行验证;模型可以保存最优的权重,并读取权重;记录下训练集和验证集的精度,便于调参。 构造验证集 在机器学习模型(特别是深度学习模型)的训练过程中,模型是非常容易过拟合的。深度学习模型在不断的训练过程中训练误差会逐渐降低,但测试误

DW-matplotlib-Task4
一、Figure和Axes上的文本 Matplotlib具有广泛的文本支持,包括对数学表达式的支持、对栅格和矢量输出的TrueType支持、具有任意旋转的换行分隔文本以及Unicode支持。下面的命令是通过pyplot API和objected-oriented API分别创建文本的方式: pyplot APIOO APIdescriptiontexttext在Axes的任意位置添加textt

20210622_26期_办公自动化_Task4_Python 操作 PDF
四、Python 操作 PDF 目录 四、Python 操作 PDF来源 0 基础1 PDF拆分2 批量合并3. 提取文字内容4. 提取表格内容5. 提取图片内容参考资料 来源 Datewhle26期__Python办公自动化 : https://github.com/datawhalechina/team-learning-program/tree/master/

二手车交易价格预测_Task4_建模与调参
建模与调参_代码示例部分 # 导入工具包 import pandas as pdimport numpy as npimport warningswarnings.filterwarnings('ignore') # 代码可以正常运行但是会提示警告,很烦人,有了这行代码就能忽略警告了pd.set_option('display.max_columns', None) #
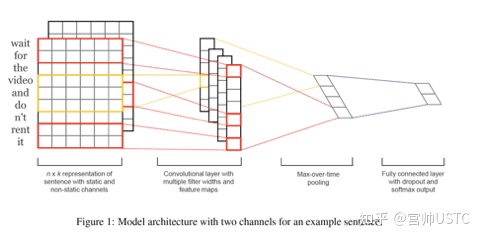
天池零基础入门NLP竞赛实战:Task4 基于深度学习的文本分类2.2-Word2Vec+TextCNN+BiLSTM+Attention分类
Task4 基于深度学习的文本分类2.2-Word2Vec+TextCNN+BiLSTM+Attention分类 完整代码见:NLP-hands-on/天池-零基础入门NLP at main · ifwind/NLP-hands-on (github.com) 模型架构 模型结构如下图所示,主要包括WordCNNEncoder、SentEncoder、SentAttention和FC模块。
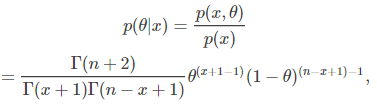
【NLP实践-Task4 传统机器学习】朴素贝叶斯 SVM LDA文本分类
目录 朴素贝叶斯原理 公式 朴素贝叶斯的优点 朴素贝叶斯的缺点 利用朴素贝叶斯进行文本分类 SVM简介 利用SVM模型进行文本分类 文本特征提取 文本特征表示 归一化处理 文本分类 pLSA、共轭先验分布、LDA简介 主题模型简介 pLSA 共轭先验分布 定义及公式 LDA LDA介绍 LDA生成过程 LDA整体流程 LDA文本分类 获取训练矩阵和单词

NLP学习__task4:传统机器学习:朴素贝叶斯、SVM、PLSA、LDA
1、朴素贝叶斯的原理 在所有机器学习分类算法中,朴素贝叶斯和其他绝大多数分类算法不同。不同于:例如决策树、KNN、逻辑回归、支持向量机等,这些都是判别方法,即直接学习出特征输出Y和特征X之间的关系,也是决策数;而朴素贝叶斯是生成方法,即直接找出特征输出Y和特征X的联合分布,然后用得出。 1)朴素贝叶斯的定理 首先,明确贝叶斯统计方式与统计学中的频率概念不同:从频