本文主要是介绍【NLP实践-Task4 传统机器学习】朴素贝叶斯 SVM LDA文本分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
朴素贝叶斯原理
公式
朴素贝叶斯的优点
朴素贝叶斯的缺点
利用朴素贝叶斯进行文本分类
SVM简介
利用SVM模型进行文本分类
文本特征提取
文本特征表示
归一化处理
文本分类
pLSA、共轭先验分布、LDA简介
主题模型简介
pLSA
共轭先验分布
定义及公式
LDA
LDA介绍
LDA生成过程
LDA整体流程
LDA文本分类
获取训练矩阵和单词
训练数据,指定主题,进行迭代
主题-单词(topic-word)分布
文档-主题(Document-Topic)分布
参考
朴素贝叶斯原理
公式
贝叶斯公式:

换个表达形式就会明朗很多,如下:

P(类别|特征1、特征2、特征3) = P(特征1|类别) * P(特征2|类别) * P(特征3|类别) * P(类别) / (P(特征1) * P(特征2) * P(特征3))
朴素贝叶斯的优点
- 算法逻辑简单,易于实现;
- 分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
朴素贝叶斯的缺点
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
利用朴素贝叶斯进行文本分类
https://github.com/Jack-Cherish/Machine-Learning/blob/master/Naive%20Bayes/nbc.py
# -*- coding: UTF-8 -*-
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt
import os
import random
import jieba"""
函数说明:中文文本处理
Parameters:folder_path - 文本存放的路径test_size - 测试集占比,默认占所有数据集的百分之20
Returns:all_words_list - 按词频降序排序的训练集列表train_data_list - 训练集列表test_data_list - 测试集列表train_class_list - 训练集标签列表test_class_list - 测试集标签列表
Author:Jack Cui
Blog:http://blog.csdn.net/c406495762
Modify:2017-08-22
"""
def TextProcessing(folder_path, test_size = 0.2):folder_list = os.listdir(folder_path) #查看folder_path下的文件data_list = [] #数据集数据class_list = [] #数据集类别#遍历每个子文件夹for folder in folder_list:new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表j = 1#遍历每个txt文件for file in files:if j > 100: #每类txt样本数最多100个breakwith open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件raw = f.read()word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generatorword_list = list(word_cut) #generator转换为listdata_list.append(word_list) #添加数据集数据class_list.append(folder) #添加数据集类别j += 1data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩random.shuffle(data_class_list) #将data_class_list乱序index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值train_list = data_class_list[index:] #训练集test_list = data_class_list[:index] #测试集train_data_list, train_class_list = zip(*train_list) #训练集解压缩test_data_list, test_class_list = zip(*test_list) #测试集解压缩all_words_dict = {} #统计训练集词频for word_list in train_data_list:for word in word_list:if word in all_words_dict.keys():all_words_dict[word] += 1else:all_words_dict[word] = 1#根据键的值倒序排序all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩all_words_list = list(all_words_list) #转换成列表return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list"""
函数说明:读取文件里的内容,并去重
Parameters:words_file - 文件路径
Returns:words_set - 读取的内容的set集合
Author:Jack Cui
Blog:http://blog.csdn.net/c406495762
Modify:2017-08-22
"""
def MakeWordsSet(words_file):words_set = set() #创建set集合with open(words_file, 'r', encoding = 'utf-8') as f: #打开文件for line in f.readlines(): #一行一行读取word = line.strip() #去回车if len(word) > 0: #有文本,则添加到words_set中words_set.add(word) return words_set #返回处理结果"""
函数说明:根据feature_words将文本向量化
Parameters:train_data_list - 训练集test_data_list - 测试集feature_words - 特征集
Returns:train_feature_list - 训练集向量化列表test_feature_list - 测试集向量化列表
Author:Jack Cui
Blog:http://blog.csdn.net/c406495762
Modify:2017-08-22
"""
def TextFeatures(train_data_list, test_data_list, feature_words):def text_features(text, feature_words): #出现在特征集中,则置1 text_words = set(text)features = [1 if word in text_words else 0 for word in feature_words]return featurestrain_feature_list = [text_features(text, feature_words) for text in train_data_list]test_feature_list = [text_features(text, feature_words) for text in test_data_list]return train_feature_list, test_feature_list #返回结果"""
函数说明:文本特征选取
Parameters:all_words_list - 训练集所有文本列表deleteN - 删除词频最高的deleteN个词stopwords_set - 指定的结束语
Returns:feature_words - 特征集
Author:Jack Cui
Blog:http://blog.csdn.net/c406495762
Modify:2017-08-22
"""
def words_dict(all_words_list, deleteN, stopwords_set = set()):feature_words = [] #特征列表n = 1for t in range(deleteN, len(all_words_list), 1):if n > 1000: #feature_words的维度为1000break #如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:feature_words.append(all_words_list[t])n += 1return feature_words"""
函数说明:新闻分类器
Parameters:train_feature_list - 训练集向量化的特征文本test_feature_list - 测试集向量化的特征文本train_class_list - 训练集分类标签test_class_list - 测试集分类标签
Returns:test_accuracy - 分类器精度
Author:Jack Cui
Blog:http://blog.csdn.net/c406495762
Modify:2017-08-22
"""
def TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list):classifier = MultinomialNB().fit(train_feature_list, train_class_list)test_accuracy = classifier.score(test_feature_list, test_class_list)return test_accuracyif __name__ == '__main__':#文本预处理folder_path = './SogouC/Sample' #训练集存放地址all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)# 生成stopwords_setstopwords_file = './stopwords_cn.txt'stopwords_set = MakeWordsSet(stopwords_file)test_accuracy_list = []deleteNs = range(0, 1000, 20) #0 20 40 60 ... 980for deleteN in deleteNs:feature_words = words_dict(all_words_list, deleteN, stopwords_set)train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)test_accuracy_list.append(test_accuracy)# ave = lambda c: sum(c) / len(c)# print(ave(test_accuracy_list))plt.figure()plt.plot(deleteNs, test_accuracy_list)plt.title('Relationship of deleteNs and test_accuracy')plt.xlabel('deleteNs')plt.ylabel('test_accuracy')plt.show()
上图是deleteNs和test_accuracy的关系,根据此图可以大致确定去掉前多少的高频词汇。
每次运行程序,绘制的图形可能不尽相同,可以通过多次测试,来决定这个deleteN的取值,然后确定这个参数,这样就可以顺利构建出用于新闻分类的朴素贝叶斯分类器了。
我测试感觉450还不错,最差的分类准确率也可以达到百分之50以上。将if __name__ == '__main__'下的代码修改如下:
if __name__ == '__main__':#文本预处理folder_path = './SogouC/Sample' #训练集存放地址all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)# 生成stopwords_setstopwords_file = './stopwords_cn.txt'stopwords_set = MakeWordsSet(stopwords_file)test_accuracy_list = []feature_words = words_dict(all_words_list, 450, stopwords_set)train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)test_accuracy_list.append(test_accuracy)ave = lambda c: sum(c) / len(c)
SVM简介
支持向量机(SVM)算法基于结构风险最小化原理,将数据集合压缩到支持向量集合,学习得到分类决策函数。这种技术解决了以往需要无穷大样本数量的问题,它只需要将一定数量的文本通过计算抽象成向量化的训练文本数据,提高了分类的精确率。支持向量机(SVM)算法是根据有限的样本信息,在模型的复杂性与学习能力之间寻求最佳折中,以求获得最好的推广能力支持向量机算法的主要优点有:
- 专门针对有限样本情况,其目标是得到现有信息下的最优解而不仅仅是样本数量趋于无穷大时的最优值;
- 算法最终转化为一个二次型寻优问题,理论上得到的是全局最优点,解决了在神经网络方法中无法避免的局部极值问题;
- 支持向量机算法能同时适用于稠密特征矢量与稀疏特征矢量两种情况,而其他一些文本分类算法不能同时满足两种情况;
- 支持向量机算法能够找出包含重要分类信息的支持向量,是强有力的增量学习和主动学习工具,在文本分类中具有很大的应用潜力。
利用SVM模型进行文本分类
SVM 文本分类算法主要分四个步骤:文本特征提取、文本特征表示、归一化处理和文本分类。
文本特征提取
在对文本特征进行提取时,常采用特征独立性假设来简化特征选择的过程,达到计算时间和计算质量之间的折中。一般的方法是根据文本中词汇的特征向量,通过设置特征阀值的办法选择最佳特征作为文本特征子集,建立特征模型。(分词,去停用词,然后进行特征提取)。
特征提取最常用的方法是通过词频选择特征。先通过词频计算出权重,按权重从大到小排序,然后剔除无用词,这些词通常是与主题无关的,任何类的文章中都有可能大量出现的,比如“的”“是”“在”一类的词,一般在停词表中已定义好,去除这些词以后,有一个新的序列排下来,然后可以按照实际需求选取权重最高的前8个,10个或者更多词汇来代表该文本的核心内容。
综上所述,特征提取步骤可以总结为:
- 对全部训练文档进行分词,由这些词作为向量的维数来表示文本;
- 统计每一类内文档所有出现的词语及其频率,然后过滤,剔除停用词和单字词;
- 统计每一类内出现词语的总词频,并取其中的若干个频率最高的词汇作为这一类别的特征词集;
- 去除每一类别中都出现的词,合并所有类别的特征词集,形成总特征词集。最后所得到的特征词集就是我们用到的特征集合,再用该集合去筛选测试集中的特征。
文本特征表示
TF-IDF 公式来计算词的权值,详见https://blog.csdn.net/yyy430/article/details/88249709
归一化处理
归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。

公式中a为关键词的词频,min为该词在所有文本中的最小词频,max为该词在所有文本中的最大词频。这一步就是归一化,当用词频进行比较时,容易发生较大的偏差,归一化能使文本分类更加精确。
文本分类
经过文本预处理、特征提取、特征表示、归一化处理后,已经把原来的文本信息抽象成一个向量化的样本集,然后把此样本集与训练好的模板文件进行相似度计算,若不属于该类别,则与其他类别的模板文件进行计算,直到分进相应的类别,这就是SVM 模型的文本分类方式。
基于SVM的系统实现(如图所示)
pLSA、共轭先验分布、LDA简介
主题模型简介
每篇文档用bag-of-words模型表示,也就是每篇文档只与所包含的词有关,而不考虑这些词的先后顺序。假设文档集D有N篇文档,主题模型认为在这N篇文档中一共隐含了Z个主题,每篇文档都可能属于一个或多个主题,这可以用给定文档dd时所属主题zz的概率分布p(z|d)表示。同理,一个主题下可以包含若干个词w,用概率分布p(w|z)表示。
所以,如果我们有文档集D,又求出对应这个文档集的主题模型,那这有什么意义呢?最明显的意义就是,这相当于给文档聚类了,并且聚类的结果有更合理的解释性。因为我们不但可以知道每一篇文档dd属于哪个类别z,我们还可以根据概率p(w|z)知道这个主题的关键词是哪些,从而给这个主题zz设置合理的标签。知道文档所属的类别,我们就可以判断两篇文档在语义上是否相似了。虽然可以直接根据文档向量的余弦距离来判断它们是否相似,但是这对近义词就无能为力,比如两篇同样介绍电子产品的文档,一篇大量用“苹果”这个关键词,而另一篇大量用“iPhone”,那么通过余弦距离判断的这两个维度上肯定是不相似的。而“苹果”、“iPhone”两个词都与电子产品关系很大,所以这两篇文档可以都属于同一个主题,也就可以断定他们语义上是相似的。
主题模型的用处还是很多的,在推荐系统,舆情监控等等,都有广泛的用途。
pLSA
pLSA(Probabilistic Latent Senmantic Indexing)是Hoffman在1999年提出的基于概率的隐语义分析。之所以说是probabilistic,是因为这个模型中还加入了一个隐变量:主题Z ,也正因为此,它被称之为主题模型。

共轭先验分布
定义及公式
设θ是总体分布中的参数(或参数向量),π(θ)是θ的先验密度函数,假如由抽样信息算得的后验密度函数与π(θ)有相同的函数形式,则称π(θ)是θ的(自然)共轭先验分布。
这里通过举一个例子来展示何为共轭先验分布。
设一事件A的概率p(A)=θ。为了估计θ的值,作了n次独立观察,其中事件A出现的次数为X,显然X服从二项分布X∼B(n,θ)。 因此 :

利用贝叶斯公式,我们首先需要确定先验概率p(θ)。在未得到其余信息前,我们只能认为θ在(0,1)上均匀分布,这是一种不失偏颇的先验估计。
到这里我们就已经可以计算出p(x,θ)这一联合概率分布。
![]()
然后通过联合概率分布,我们又可以得出p(x)的边缘概率分布。

综合以上可得θθ的后验分布:
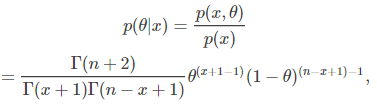
细心点就会发现这个分布就是参数为(x+1)和(n−x+1)(x+1)和(n−x+1)的贝塔分布,即p(θ|x) Be(x+1,n−x+1)p(θ|x) Be(x+1,n−x+1)。更奇妙的是先验分布p(θ)p(θ),区间(0,1)上的均匀分布也是一种特殊的贝塔分布Be(1,1)。
LDA
LDA介绍
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
LDA生成过程
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
- 对每一篇文档,从主题分布中抽取一个主题;
- 从上述被抽到的主题所对应的单词分布中抽取一个单词;
- 重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
LDA整体流程
文档集合D,主题集合T。
D中每个文档d看作一个单词序列<w1, w2, …… ,wn>,wi表示第i个单词,设d有n个单词。(LDA里面称之为wordbag,实际上每个单词的出现位置对LDA算法无影响)
文档集合D中的所有单词组成一个大集合VOCABULARY(简称VOC)。
LDA以文档集合D作为输入,希望训练出两个结果向量(设聚成k个topic,VOC中共包含m个词)。
对每个D中的文档d,对应到不同Topic的概率θd<pt1,...,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。
对每个T中的topic,生成不同单词的概率φt<pw1,...,pwm>,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。
LDA的核心公式如下:
p(w|d)=p(w|t)*p(t|d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
LDA文本分类
获取训练矩阵和单词
import numpy as np
import lda# X:n*m的矩阵,表示有n个文本,m个单词,值表示出现次数或者是否出现。
X = np.genfromtxt("data\\source_wzp_lda_1.txt", skip_header=1, dtype = np.int)# vocab是m个单词组成的list
file_vocab = open("data\\vectoritems_lda_3.txt", "r")
vocab = (file_vocab.read().decode("utf-8").split("\n"))[0:-1]
print len(vocab)训练数据,指定主题,进行迭代
#指定11个主题,500次迭代
model = lda.LDA(random_state=1, n_topics=11, n_iter=1000)
model.fit(X)主题-单词(topic-word)分布
#主题-单词(topic-word)分布
topic_word = model.topic_word_
print("type(topic_word): {}".format(type(topic_word)))
print("shape: {}".format(topic_word.shape))#获取每个topic下权重最高的10个单词
n = 10
for i, topic_dist in enumerate(topic_word):topic_words = np.array(vocab)[np.argsort(topic_dist)][:-(n+1):-1]print("topic {}\n- {}".format(i, ('-'.join(topic_words)).encode("utf-8")))文档-主题(Document-Topic)分布
#文档主题(Document-Topic)分布:
doc_topic = model.doc_topic_
print("type(doc_topic): {}".format(type(doc_topic)))
print("shape: {}".format(doc_topic.shape))#一篇文章对应一行,每行的和为1
#输入前10篇文章最可能的Topic
for n in range(20):'''for i in doc_topic[n]:print i'''topic_most_pr = doc_topic[n].argmax()print("doc: {} topic: {}".format(n, topic_most_pr))参考
python机器学习:朴素贝叶斯分类算法 https://mp.weixin.qq.com/s?src=11×tamp=1552023306&ver=1471&signature=VdN1JOPo8XxCAGbNGak0CoxnWRWZlZtWKOGdQoqpV*Z2q305Xhqk8CUdYYuI85IP5SmfdD0Z7AzxPUDdmPTXAJVZOwRUqekVz*6fSVNmX07ZI46EduKEU*1jXxfG2qSs&new=1
朴素贝叶斯实战篇之新浪新闻分类 https://blog.csdn.net/c406495762/article/details/77500679
朴素贝叶斯实战篇之新浪新闻分类 https://github.com/Jack-Cherish/Machine-Learning/tree/master/Naive%20Bayes
基于支持向量机SVM的文本分类的实现 https://blog.csdn.net/qq_30189255/article/details/54571370
文本建模系列之二:pLSA https://blog.csdn.net/u010223750/article/details/51334584
LSA,pLSA原理及其代码实现 https://www.cnblogs.com/bentuwuying/p/6219970.html
LSA,pLSA原理及其代码实现 https://blog.csdn.net/thriving_fcl/article/details/50878845
plsa(Probabilistic Latent Semantic Analysis) 概率隐语义分析 https://blog.csdn.net/thriving_fcl/article/details/50878845
主题模型(概率潜语义分析PLSA、隐含狄利克雷分布LDA) https://www.cnblogs.com/softzrp/p/6964951.html
用LDA处理文本(Python) https://blog.csdn.net/u013710265/article/details/73480332
主题模型 LDA 入门(附 Python 代码) https://blog.csdn.net/selinda001/article/details/80446766
这篇关于【NLP实践-Task4 传统机器学习】朴素贝叶斯 SVM LDA文本分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





