task02专题

《动手学深度学习(Pytorch版)》Task02:预备知识——4.25打卡
《动手学深度学习(Pytorch版)》Task02:预备知识——4.25打卡 数据操作N维数组——张量创建数组访问元素入门初始化矩阵 运算符广播机制索引和切片节省内存转换为其他Python对象转换为NumPy张量`ndarray`张量转换为Python标量 数据预处理安装pandas读取数据集处理缺失值转换为张量格式删除缺失值最多的列 线性代数标量向量长度、维度和形状矩阵范数特殊矩阵特征向
![[动手学深度学习]Task02:预备知识](https://img-blog.csdnimg.cn/9ce29ea8bcdc4008a0aa625e65ca7583.png)
[动手学深度学习]Task02:预备知识
04.数据操作+数据预处理 开始数据操作 都是些基础操作,只能说,别谦简单,自己都过一遍,不要眼高手低,血泪教训,基础扎实对于阅读他人代码也有好处,否则很有可能导致连代码都看不懂 本文章存粹的为了自己熟悉操作,具体的解释可看电子数:动手深度学习电子书 import torch 张量表示一个数值组成的数组,这个数组可能有多个维度 x = torch.arange(12)pri

Datawhale 零基础入门CV-Task02.数据读取与数据扩增
主要内容 数据读取数据扩增方法Pytorch读取赛题数据 学习目标 学会Python和Pytorch中图像读取学会扩增方法和Pytorch读取赛题数据 图像读取 由于赛题数据是图像数据,赛题的任务是识别图像中的字符。因此需要完成对数据的读取操作,在Python中有很多库可以完成数据读取的操作,比较常见的有Pillow和OpenCV Pillow Pillow是Python图像处理函数

DataWhale-202110 树模型与集成学习(组队学习)-Task02
DataWhale-202110 树模型与集成学习-Task02 CART代码实现回归树训练代码代码运行结果 分类树 CART代码实现 回归树 import pandas as pdimport numpy as npdef MSE(y):return ((y - y.mean())**2).sum() / y.shape[0]class Node:def __init_

二手车价格预测task02:数据探索性分析
task02学习了数据的分析画图 学习了sns.pairplot()用法 学习了sns.distplot()方法的使用 敲了一遍task数据分析,加了些注释说明 删除了两个类别特征异常的列和是三个和price相关性非常的列后进行预测,结果如图,效果并没有提高.应该做进一步的处理和特征工程(task03) 以下是按照教程进行数据分析的过程 # 导包import warnings

天池AI Earth task02
文章目录 Baseline学习库导入数据读取1.CMIP(SODA)_label处理2.SODA_train处理3.CMIP_train处理 数据建模1. 工具包导入2.标签数据读取3.原始特征数据读取4.构建神经网络框架5.划分训练集验证集6.模型训练7.模型预测8.计算分数 模型预测1.模型导入2.模型预测3.预测结果打包 Baseline学习 库导入 import p
DataWhale-西瓜书+南瓜书第3章线性模型学习总结-Task02-202110
3.1 基本形式 样本,其中是在第i个属性上的取值。线性模型试图学得一个通过属性得线性组合来进行预测得函数,即 3.2 线性回归 3.2.1 一元线性回归 均方误差最小化,对w和b求导:
DataWhale-树模型与集成学习-Task02-Cart分类树代码实现-202110
助教老师实现了Cart回归树,在老师代码的基础上,实现了Cart分类树,代码如下: import numpy as npdef Gini(y):gn=1.0n=y.shape[0]for i in np.unique(y):gn=gn-(np.sum(y==i)/n)**2return gndef argmax(y):l=sorted([(np.sum(y==i),i) for i in

DataWhale-(动手学数据分析)-Task02(第2-3节数据重构)-202201
动手学数据分析 2 第二章 数据重构 # 导入基本库import numpy as npimport pandas as pd 2.4 数据的合并 2.4.1 任务一:将data文件夹里面的所有数据都载入,与之前的原始数据相比,观察他们的之间的关系 text_left_up = pd.read_csv("data/train-left-up.csv")text_left_down
DataWhale-(动手学数据分析)-Task02(第2-3节数据重构)-202201
动手学数据分析 2 第二章 数据重构 # 导入基本库import numpy as npimport pandas as pd 2.4 数据的合并 2.4.1 任务一:将data文件夹里面的所有数据都载入,与之前的原始数据相比,观察他们的之间的关系 text_left_up = pd.read_csv("data/train-left-up.csv")text_left_down
DataWhale-(动手学数据分析)-Task02(数据清洗及特征处理第1节)-202201
动手学数据分析 第二章:数据清洗及特征处理 import numpy as npimport pandas as pd#加载数据train.csvdf = pd.read.csv('train.csv')df.head(10) 数据清洗简述 我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的
DataWhale-(动手学数据分析)-Task02(数据清洗及特征处理第1节)-202201
动手学数据分析 第二章:数据清洗及特征处理 import numpy as npimport pandas as pd#加载数据train.csvdf = pd.read.csv('train.csv')df.head(10) 数据清洗简述 我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的

Datawhale第十二期组队学习--Python爬虫编程实践 Task02:bs4、xpath和正则表达式re
一. Beautiful Soup 缺点: 基于HTML DOM 的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。匹配效率还是远远不如正则以及xpath的,一般不推荐使用,推荐正则的使用。 代码: # 2.1.4 实战:中国大学排名定向爬取import requestsfrom bs4 import BeautifulSoupimport
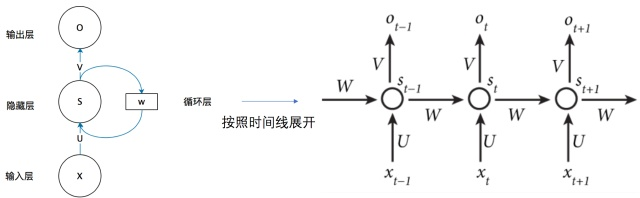
Task02:文本预处理/语言模型/循环神经网络基础
1.文本预处理 文本是一类序列数据,一篇文章可以看作是字符或单词的序列,本节将介绍文本数据的常见预处理步骤,预处理通常包括四个步骤: 1.读入文本 2.分词 3.建立字典,将每个词映射到一个唯一的索引(index) 4.将文本从词的序列转换为索引的序列,方便输入模型 细节搬运自: https://blog.csdn.net/lt326030434/article/details/852405

Matplotlib数据可视化学习打卡-Task02
学习目标: Task02 - 艺术画笔见乾坤 学习目录: 一、概述 1. matplotlib的三层api 2. Artist的分类 3. matplotlib标准用法 二、自定义你的Artist对象 1. Artist属性 2. 属性调用方式 三、基本元素 - primitives 1. 2DLines 2. patches 3. collections 4. images
计算机系统漫游task02
信息的表示和处理 虚拟地址空间字数据大小寻址和字节顺序寻址和字节顺序布尔运算数值信息的表示相互转化截断加法溢出两种乘法两种除法二进制小数规格化的值非规格化的值特殊值 虚拟地址空间 ·内存的地址的集合称为虚拟地址空间 1 byte = 8bit 字数据大小 对于一个字长为位的机器,虚拟地址的范围是0到2^w - 1 寻址和字节顺序 寻址和字节顺序 我们需要知道