本文主要是介绍[动手学深度学习]Task02:预备知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
04.数据操作+数据预处理
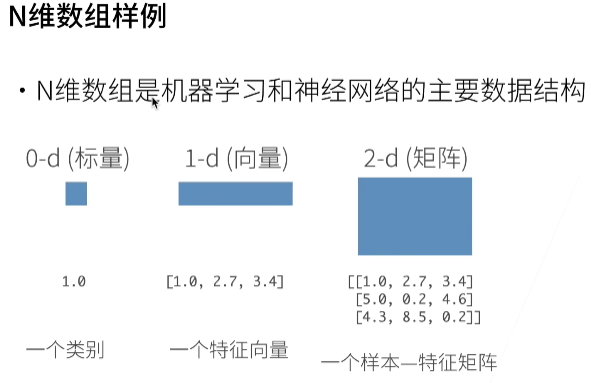
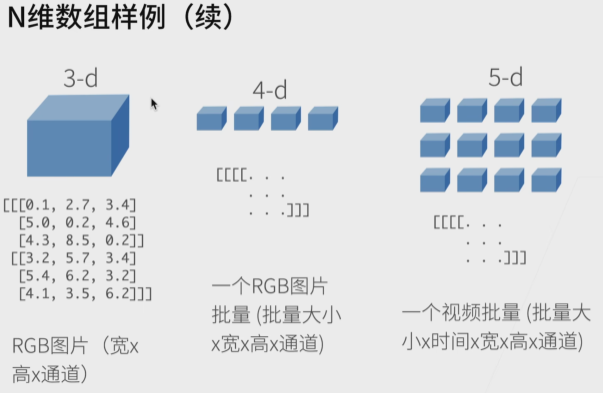
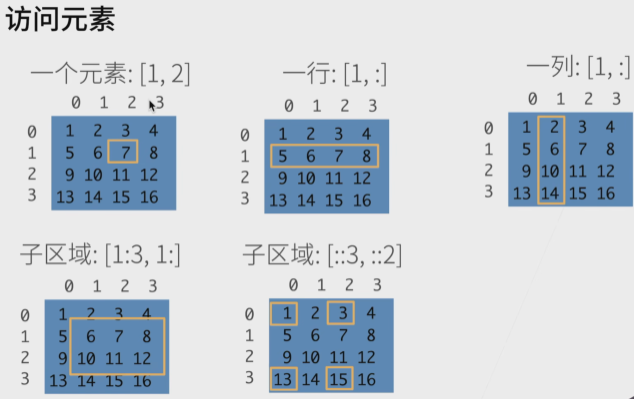
开始数据操作
都是些基础操作,只能说,别谦简单,自己都过一遍,不要眼高手低,血泪教训,基础扎实对于阅读他人代码也有好处,否则很有可能导致连代码都看不懂
本文章存粹的为了自己熟悉操作,具体的解释可看电子数:动手深度学习电子书
import torch
张量表示一个数值组成的数组,这个数组可能有多个维度
x = torch.arange(12)
print(x)
通过张量的shape属性访问张量的形状和元素总数
x.shapex.numel()//number element缩写

改变一个张量的形状而不改变元素数量和元素值,可以用reshape函数
把张量x从形状为(12)的行向量转换为形状为(3.4)的矩阵
x = x.reshape(3, 4)

使用全0、全1、其他常量或者从特定分布中随机采样的数字
torch.zeros((2, 3, 4))
torch.ones((2, 3, 4))
通过提供包含数值的Python列表(或者嵌套列表)来为所需张量的每个元素赋予确定值
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])

常见的算术运算符都可以升级为按元素运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
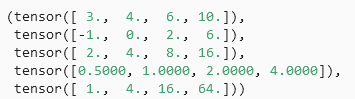
将多个张量连结在一起
例子分别演示了当我们沿行(轴-0,形状的第一个元素) 和按列(轴-1,形状的第二个元素)连结两个矩阵时,会发生什么情况。 我们可以看到,第一个输出张量的轴-0长度(6)是两个输入张量轴-0长度的总和(3+3); 第二个输出张量的轴-1长度(8)是两个输入张量轴-1长度的总和(4+4)。
X = torch.arrage(12,dytpe=torch.float32).reshape((3, 4))
Y = Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)

逻辑运算符构建二元张量
X == Y

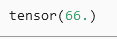
对张量中所有元素求和
X.sum()
即使形状不同,我们仍然可以通过广播机制来执行按元素操作
机制工作方式如下:
- 通过适当复制元素来扩展一个或两个数组,以便在转换之后 ,两个张量具有相同的形状
- 对生成的数组执行按元素操作
在大部分情况下,我们将沿着数组中长度为1的轴进行广播
a = torch.arrage(3).reshape((3, 1))
b = torch.arrage(2).reshape((1, 2))
 a,b形状不匹配,将两个矩阵
a,b形状不匹配,将两个矩阵广播为一个更大的3×2矩阵,如下:矩阵a将复制列,矩阵b将复制行,然后再按元素相加(内部机制)
a + b

切片这里过了,就是注意左包右不包,正负索引区别

关于内存分配的问题:大数据的情况下要注意
运行一些操作可能会导致为新结果分配内存
before = id(Y)
Y = Y + X
id(Y) == before

这样不太行,原因如下:
- 首先不要总是自己分配内存,机器学习中,我们可能有数百兆参数,并且在一秒内多次更新所有参数,通常情况下,我们希望原地执行这些更新
- 如果我们不原地更新,其他引用仍然会指向旧的内存位置,这样我们的某些代码可能无意中引用旧的参数
个人认为,不断分配新内存,但是老地址的数据不清洗就变成了脏数据,但是使用者又不清楚底层原理,就容易直接懵逼
原地操作如下:其中zeros_like分配的是一个全0的块,相当于直接覆盖?
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))


转换为NumPy张量
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
将大小为1的张量转换为Python标量
a = torch.tensor([3, 5])
a, a.item(), float(a), int(a)
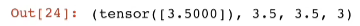
数据预处理
创建一个人工数据集,并存储在csv(逗号分隔符)文件
读取数据集
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_filr = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pddata = pd.read_csv(data_file)
print(data)
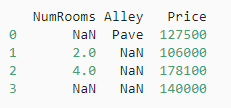
处理缺失值
呵呵,天知道我第一次打相关比赛看到数据清洗的懵逼感,那个时候还没接受过相关学习,只会简单的python的简单语法,不知者无畏了,不过一路走来也是不断在进步的,还是得踏实学习
不过这里插一句嘴,打比赛以来,发现只有大数据相关的比赛会涉及到缺失值处理,建模类比赛,更注重数据在模型中的应用
"NaN"即是音乐节,为了处理缺失的数据,典型方法包括插值法和删除法
这里使用插值法
inputs, output = data.iolc[:, 2] #删除
inputs = inpurs.fillna(inputs.mean())
print(inputs)


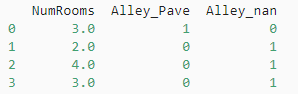
对于inputs中的类别值或离散值,我们将"NaN"视为一个类别
#把离散的类别信息转化为onehot编码形式
inputs = pd.get_dummies(inputs,dummy_na=True)print(inputs)
05.线性代数
这里更适合复习,不适合学习





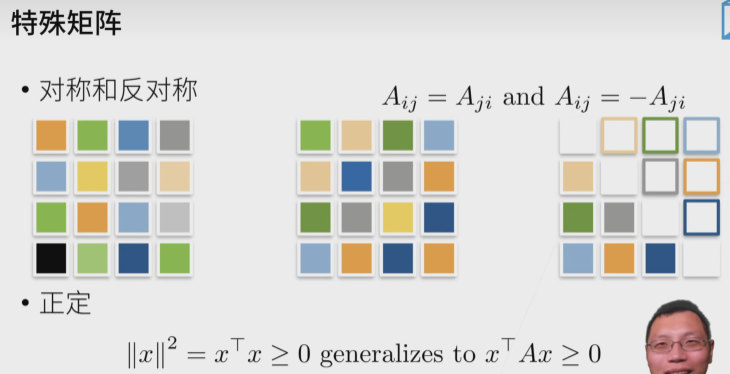

线性代数实现
标量由只有一个元素的张量表示
import torchx = torch.tensor([3.0])
y = torch.tensor([2.0])x + y, x * y, x / y, x**y

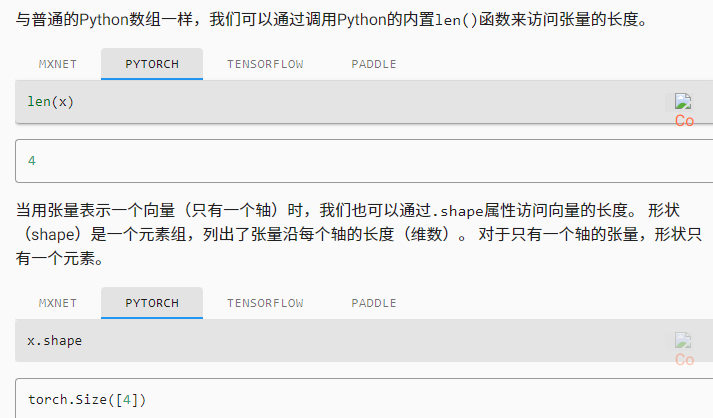
可以将向量视为标量值组成的列表
x = torch.arrnge(4)

可以通过索引访问
x[4]
当调用函数来实例张量时,我们可以通过指定两个分量m和n来创建一个形状为m×n的矩阵
A = torch.arage(20).reshape(5, 4)

矩阵的转置
A.T

就像向量是标量 的推广,矩阵是向量的推广,我们可以构建具有更多轴的数据结构
x = torch.arage(24).reshape(2, 3, 4)

给定具有相同形状的任何两个张量,任何按元素二元运算的结果都将是相同形状的张量
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() #通过分配新内存,将A的一个副本分配给B
A, A + B

降维求和
可以对任意张量进行的一个有用的操作是计算其元素的和
x = torch.arage(4, dtype=torch.float32)

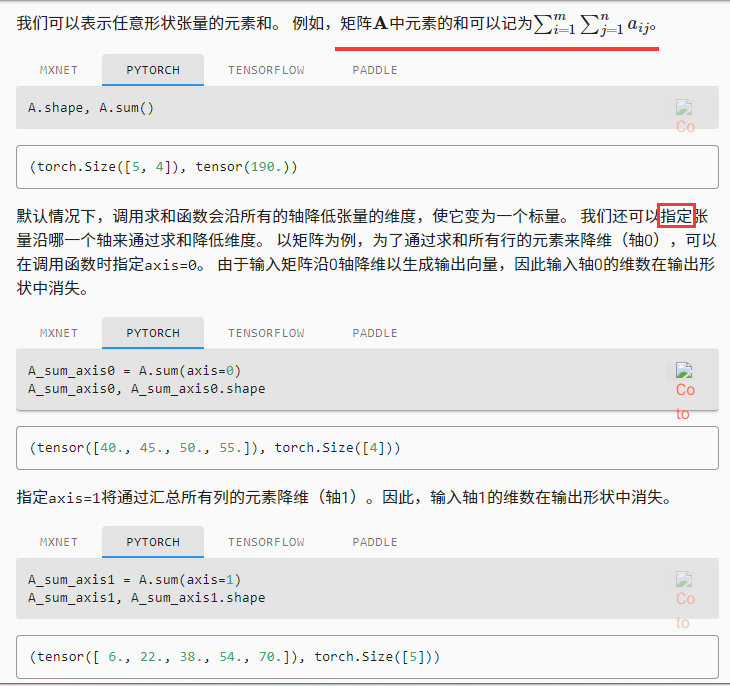
非降维求和
某些机制,如广播,要求两者维度一致
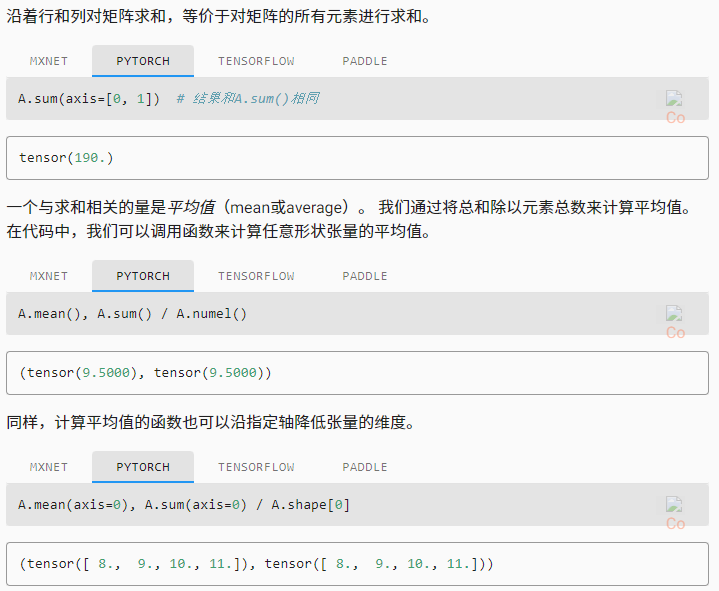
计算总和或均值时保持轴数不变
sum_A = A.sum(axis=1, keepdims=True)
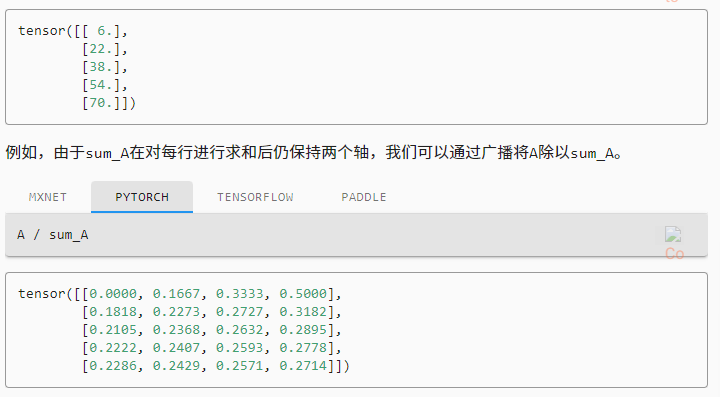
某个轴计算 A 元素的累积总和
A.cumsum(axis=0)

点积

y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)

可以通过执行按元素乘法,然后求和表示两个向量的点积
torch.sum(x * y)
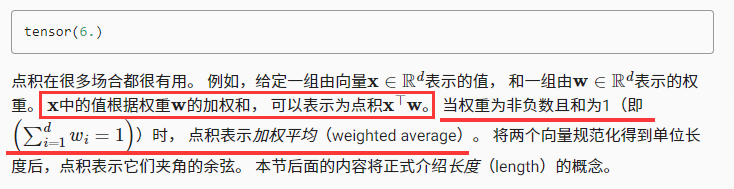
接下来开始向量积


A.shape, x.shape, torch.mv(A, x)

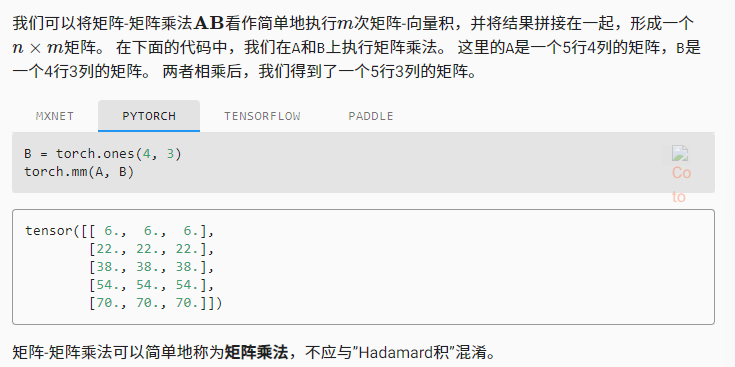
按特定轴求和
范数这里我还是不太熟悉

Q&A
问题1:这么转换有什么负面影响嘛?比如数值变得稀疏
没有
问题2:为什么瀑度学习要用张量来表示?
统计学在计算机上的表达
问题3:求copy与clone的区别(是关于内存吗? )
copy可能不复制内存,clone一定赋值内存
问题4∶对哪—维求和就是消除哪一维可以这么理解吗?
可以
问题5:torch不区分行向量和列向量吗?
想区分必须使用矩阵
问题6: sum(axis=[0,1])怎么求?
对相应维度的矩阵求和
问题7:请问,torch 中L1,L2正则项要怎么加入?
后面说
问题8∶稀疏的时候可以把它当成单词做词向量解决吗?
后面说
问题9:张量的概念机器学习里和数学有那些主要的区别吗?
两个不是一个东西
问题10︰这门课是不是只讲基于pytorch的神经网络算法?学习其它算法可以先听这门课吗?
工具也在不断进步,工具与学习应该分开,明白实现的概念本身
问题11:请问老师病理图片的SVS格式和医生勾画的区域XML格式的文件怎么进行预处理啊?
像素级解决,NOP方式解决
问题12:稀疏化之后有什么好的解决办法嘛?刚才老师好像提到用"稀疏矩阵"的方法?减小内存?
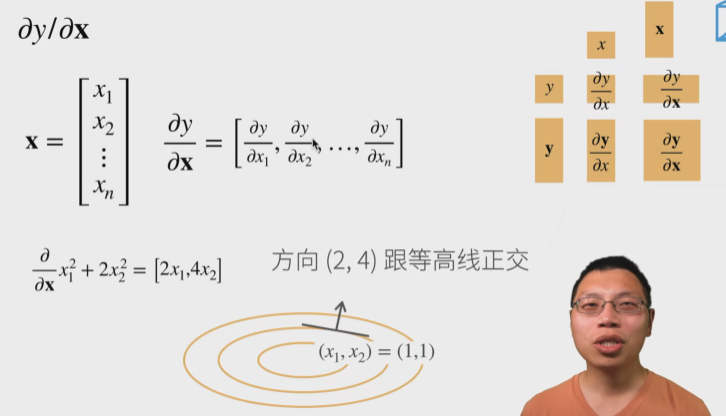
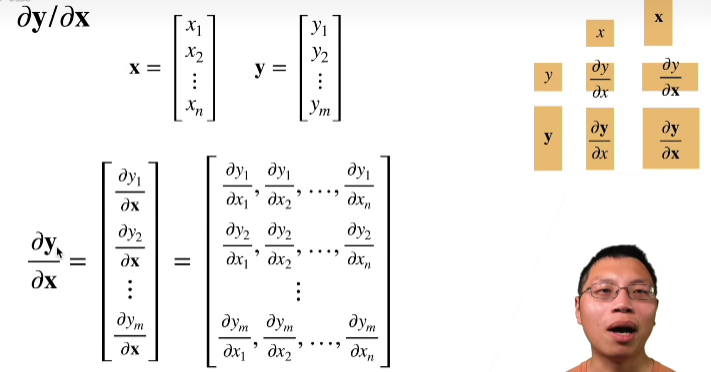
06.矩阵计算
即矩阵求导数,截了各种奇怪表情图哈哈哈
这一节还好,高数里面学过了

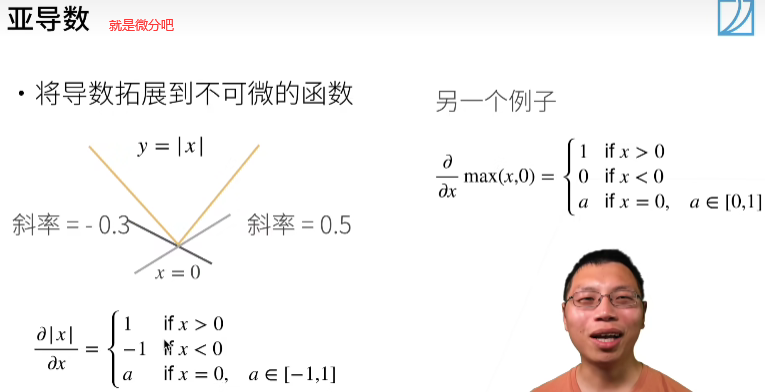



07.直接求导


这个东东实现感觉不简单






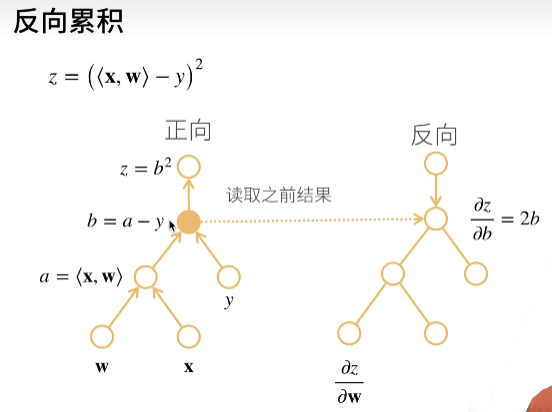

自动求导实现

import torchx = torch.arange(4.0)
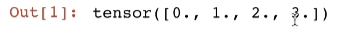
在计算 y 关于 x 的梯度之前,需要一个地方来存储梯度
x.requires_grad_(True) #等价于 x = torch.arange(4.0, requires_grad=True)
x.grad #默认值是None
现在让我们计算y
y = 2 * torch.dot(x, x)
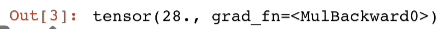
通过调用反向传播函数来自动计算 y 关于 x 每个分量的梯度
y.backward() #求导
x.grad
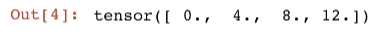
x.grad == 4 * x

现在计算 x 的另一个函数
#在默认情况下,Pytorch会累积梯度,我们需要清楚之前的值
x.grad,zero_() #清零
y = s.sum()
y.backward()
x.grad
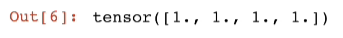
深度学习中,我们的目的不是计算微分矩阵,而是批量中每个样本单独计算的偏导数之和
# 对非标量调用 backeard 需要传入一个 gradient 参数,该参数指定微分函数
x.grad,zero_() #清零
y = x * x #向量
# 等价于 y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
将某些计算移动到记录的计算图之外
x.grad.zero_()
y = x * x
u = y.detach()
z = u * xz.sum().backward()
x.grad == u
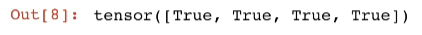
现在已经开始懵逼了,还是不能一直搞,应该分开

这个没有实操真的在啃书
总结:
1.基础部分像在听python基础课程(当然,pytorch 和 numpy 有些东西还是不一样)
2.数学部分真的听的割裂,咋说呢,会的部分就当复习,不会的部分还是云里雾里,比较好的就是具体了解了数学在深度学习里的应用吧
这篇关于[动手学深度学习]Task02:预备知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





