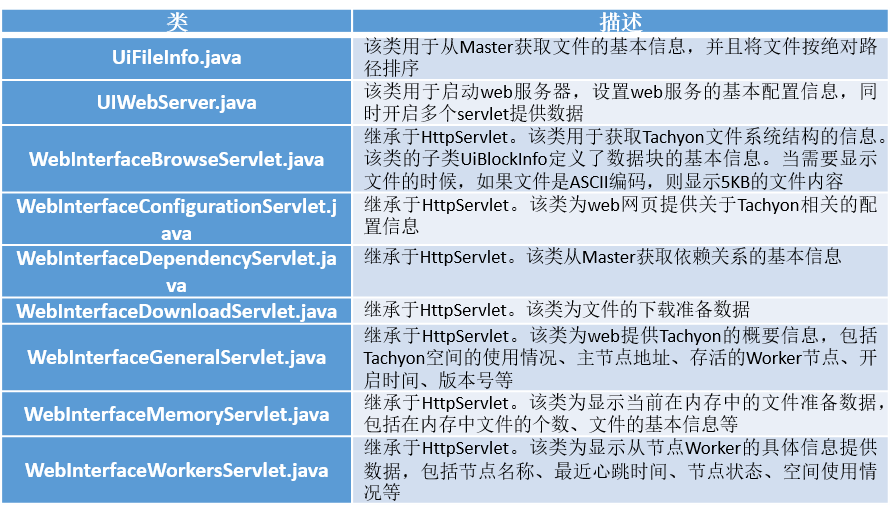
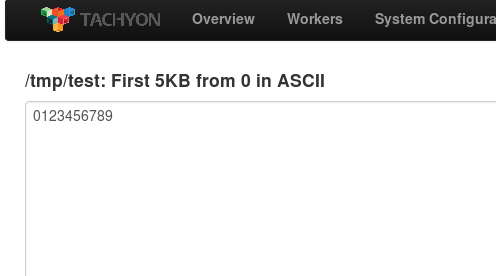
tachyon专题
Tachyon源码结构分析(三)
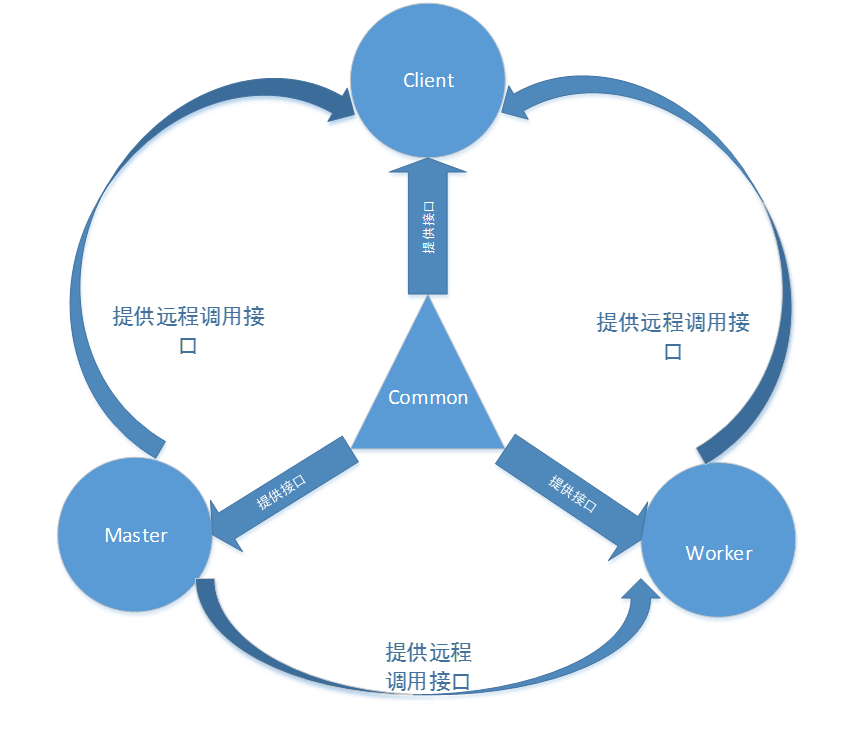
发布人:南京大学PASA大数据实验室 前言 在上一篇《Tachyon源码结构分析(二)》中,我们具体分析了Common模块和Client模块的源码结构,本篇接着上一篇内容介绍Master模块的源码结构分析。 版本选择 Tachyon目前刚刚发布了新版本0.6.1,最新的开发版仍为0.7.0-SNAPSHOT。本篇我们仍然选择Tachyon-0.6.0版本保持与前两篇同步。
Tachyon源码结构分析(一)
发布人:南京大学PASA大数据实验室舒鹏 前言 在上一篇博客中,我们介绍了Tachyon的安装、配置和使用,用户已经对Tachyon有了初步的了解。从本篇开始,我们将对Tachyon的源码结构进行分析,让用户进一步更深入的了解Tachyon的工作机制。由于源码分析的内容比较多,我们将分成多篇来详细阐述。 版本选择 Tachyon目前的最新发布版为0.6.0,最新
Tachyon的安装、配置和使用
发布人:南京大学PASA大数据实验室董乾豪 0. 前言 在上一篇博文《Tachyon简介》中,我们简要地介绍了Tachyon,一个以内存为中心的分布式文件系统,及其一些基本工作原理。这一次,我们重点介绍如何在你自己的单机或集群环境下去安装、配置和使用Tachyon。具体地,会从怎样编译源码开始,到各项配置、命令的说明,再加上API的使用举例,让大家能够一步步地把Tachyon用起来。

tachyon搭建记录
tachyon编译 目前官网下载的tachyon tar包只支持hadoop-2.2,如果自己的hadoop集群不是这个版本,会出现如下错误 2015-11-01 21:29:09,446 INFO (ClientBase.java:connect) - Tachyon client (version ${project.version}) is trying to conn

Tachyon(现名:Alluxio):Spark生态系统中的分布式内存文件系统
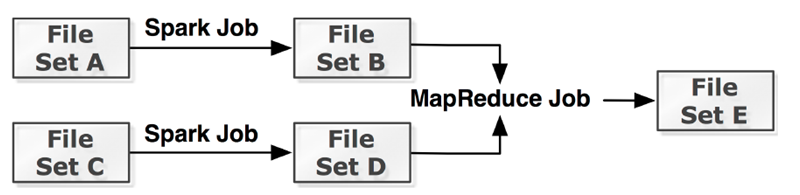
原文: http://www.csdn.net/article/2015-06-25/2825056 Tachyon是Spark生态系统内快速崛起的一个新项目。 本质上, Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 以求通过更
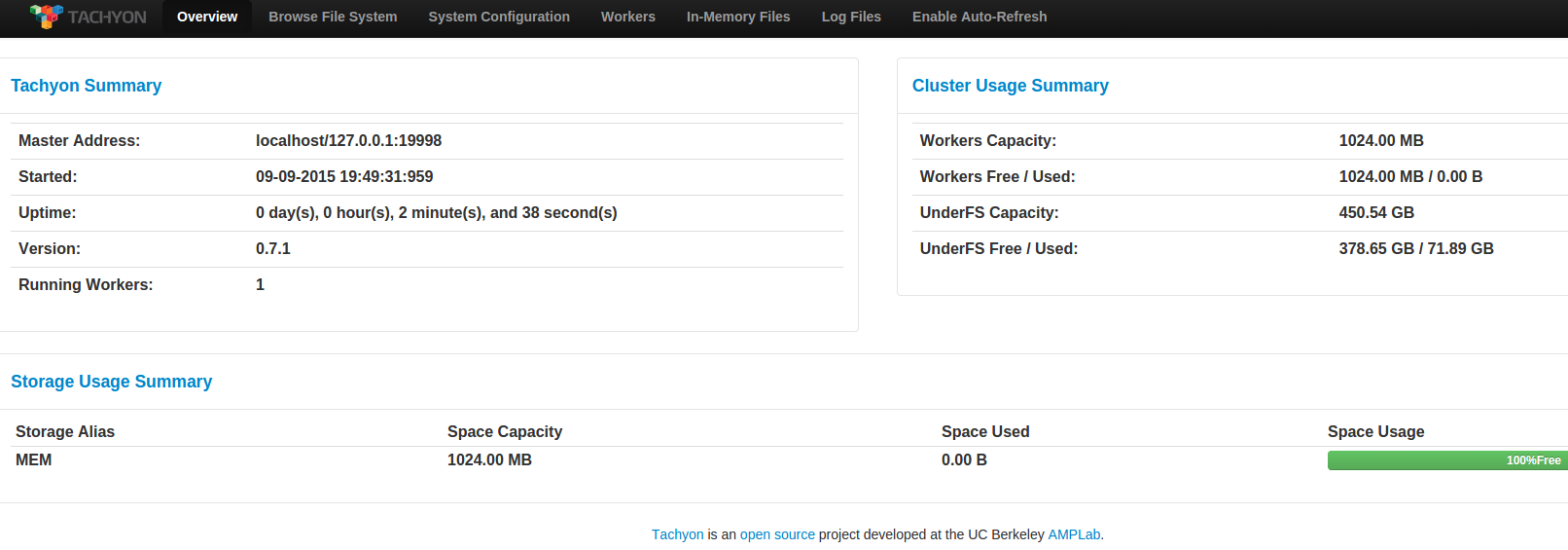
Tachyon 0.7.1伪分布式集群安装与测试
Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和 MapReduce那样。通过利用信息继承,内存侵入,Tachyon获得了高性能。Tachyon工作集文件缓存在内存中,并且让不同的 Jobs/Queries以及框架都能内存的速度来访问缓存文件。因此,Tachyon可以减少那些需要经常使用的数据集通过访问磁盘来获得的次数。 源码下载 源

Tachyon brief intro
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ Tachyon是AmpLab的Li Haoyuan所开发的一个基于内存的分布式文件系统,出发点是作为AMPLAB的BDAS的一个组成部分 总体设计思想 从Tachyon的设计目标
tachyon相关信息
最近在看Tachyon的源代码,但迟迟没空闲时间将源码分析的一些东西分享出来,一方面是以前没有分布式内存文件系统或类似的经历,知识欠缺,不能很好的全面理解源码,另一方面是自己有更重要的事儿去做,就以后再总结吧,或是就不总结了。 如下是CSDN关于Tachyon作者李浩源的采访的一篇文章:http://www.csdn.net/article/2013-11-28/2817652-BDTC2

Tachyon源码结构分析(四)
发布人: 南京大学PASA大数据实验室 前言 在上一篇《Tachyon源码结构分析(三)》中,我们分析了Master模块的源码结构,本篇接着介绍Worker模块的源码结构分析。 版本选择 Tachyon目前最新发布的版本为0.6.1,最新的开发版本为0.7.0-SNAPSHOT。本篇我们仍然延续前几篇使用的0.6.0版本。 官方链接:Tachyon-0.6.0 Worker模

Tachyon 的 安装部署
1. 下载源码 tachyon源码 2. 编译 mvn package -Djava.version=1.7 -Dhadoop.version=2.2.0 -DskipTests 3.安装 cp tachyon-env.sh.template tachyon-env.sh 在 tachyon-env.sh 中 export JAVA_HOME=/usr/local/java/jdk1

1.Tachyon简介
Tachyon是以内存为中心的分布式文件系统,能够为集群计算框架(如:Spark,MapReduce等)提供内存级速度的跨集群文件共享服务。 1.1 Tachyon特征 1) Tachyon‘s的原生API类似JAVA的文件API 2) 兼容性:Tachyon实现了HDFS接口。故MapReduce和Spark无需任何修改可以运行在Tachyon上。 3)
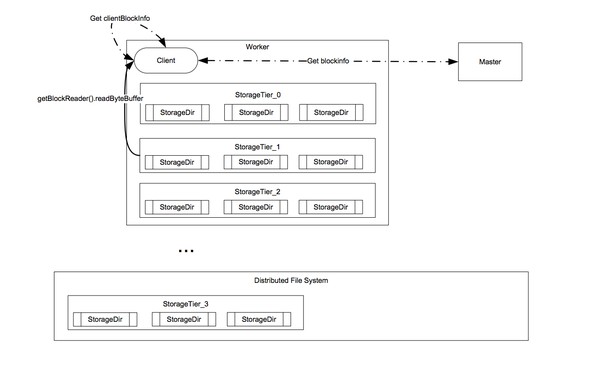
Tachyon:Spark生态系统中的分布式内存文件系统
(转自:http://www.csdn.net/article/2015-06-25/2825056) Tachyon是Spark生态系统内快速崛起的一个新项目。 本质上, Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 以求通