本文主要是介绍Tachyon的安装、配置和使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
发布人:南京大学PASA大数据实验室董乾豪
0. 前言
在上一篇博文《Tachyon简介》中,我们简要地介绍了Tachyon,一个以内存为中心的分布式文件系统,及其一些基本工作原理。这一次,我们重点介绍如何在你自己的单机或集群环境下去安装、配置和使用Tachyon。具体地,会从怎样编译源码开始,到各项配置、命令的说明,再加上API的使用举例,让大家能够一步步地把Tachyon用起来。
版本选择
Tachyon目前的最新发布版为0.5.0,最新开发版为0.6.0-SNAPSHOT。由于两者向上层提供的API有了不小的差异,这里以最新的0.6.0-SNAPSHOT开发版为基础进行介绍。它具有更多功能,更多新特性,更方便用户使用。在介绍时,我们也会标注出那些和0.5.0版本兼容的部分,让大家能够同时Hold住不同的版本。
1. Tachyon的安装
由于目前Tachyon使用了RamFS作为内存层,因此推荐在Linux环境下安装Tachyon。
对于已经发布的版本,如Tachyon-0.5.0或更早的版本,可以直接下载已经编译好的包,并解压。下载地址为https://github.com/amplab/tachyon/releases
为了更好地契合用户的本地环境,如Java版本、Hadoop版本或其他一些软件包的版本,可以下载Tachyon源码自行编译。Tachyon开源在GitHub上,可以很方便地获得其不同版本的源码:Tachyon-0.5.0;最新开发版。Tachyon项目采用Maven进行管理,因此可以采用 mvn package 命令进行编译打包。在Tachyon-0.6.0-SNAPSHOT版本中,默认依赖的java版本为1.6,默认依赖的hadoop版本为1.0.4,如果要更改这些依赖的版本号可以在编译时加入选项,如:
- mvn clean package -Djava.version=1.7 -Dhadoop.version=2.3.0 -DskipTests
完成这一步后,我们就得到了能够运行在用户本地环境的Tachyon,下面我们分别介绍如何在单机和分布式环境下配置和启动Tachyon。
1.1 单机安装Tachyon
这里要注意一点,Tachyon在单机(local)模式下启动时会自动挂载RamFS,所以请保证使用的账户具有sudo权限。
在conf/workers文件中配置需要启动TachyonWorker的节点,默认是localhost,所以在单机模式下不用更改。(在Tachyon-0.5.0版本中,该文件为conf/slaves)
将conf/tachyon-env.sh.template复制为conf/tachyon-env.sh,并在conf/tachyon-env.sh中修改具体配置,下面列举了一些重要的配置项,稍后会详细地介绍更多的配置项。
- JAVA_HOME —— 系统中java的安装路径
- TACHYON_MASTER_ADDRESS —— 启动TachyonMaster的地址,默认为localhost,所以在单机模式下不用更改
- TACHYON_UNDERFS_ADDRESS —— Tachyon使用的底层文件系统的路径,在单机模式下可以直接使用本地文件系统,如"/tmp/tachyon",也可以使用HDFS,如"hdfs://ip:port"
- TACHYON_WORKER_MEMORY_SIZE —— 每个TachyonWorker使用的RamFS大小
完成配置后,即可以单机模式启动Tachyon,格式化、启动和停止Tachyon的命令分别为:
- bin/tachyon format
- bin/tachyon-start.sh local
- bin/tachyon-stop.sh
1.2 分布式安装Tachyon
这里我们以一个三个节点的集群为例,分别为slave201,slave202和slave203。三个节点都运行TachyonWorker,slave201运行TachyonMaster。
在conf/workers文件中配置需要启动TachyonWorker的节点,即
- slave201
- slave202
- slave203
将conf/tachyon-env.sh.template复制为conf/tachyon-env.sh,并在conf/tachyon-env.sh中修改具体配置。不同于单机模式,这里需要修改TachyonMaster地址以及底层文件系统路径
- export TACHYON_MASTER_ADDRESS=slave201
- export TACHYON_UNDERFS_ADDRESS=hdfs://slave201:9000
完成配置文件的修改后,将整个tachyon文件夹复制到每个节点的相同路径下
- scp –r tachyon-master slave202:/home/.../
- scp –r tachyon-master slave203:/home/.../
第③步——启动
在分布式模式下,格式化和停止Tachyon的命令仍然为:
- bin/tachyon format
- bin/tachyon-stop.sh
但启动Tachyon有了更多的选项:
- bin/tachyon-start.sh all Mount #在启动前自动挂载TachyonWorker所使用的RamFS,然后启动TachyonMaster和所有TachyonWorker。由于直接使用mount命令,所以需要用户为root
- bin/tachyon-start.sh all SudoMount #在启动前自动挂载TachyonWorker所使用的RamFS,然后启动TachyonMaster和所有TachyonWorker。由于使用sudo mount命令,所以需要用户有sudo权限
- bin/tachyon-start.sh all NoMount #认为RamFS已经挂载好,不执行挂载操作,只启动TachyonMaster和所有TachyonWorker
因此,如果不想每次启动Tachyon都挂载一次RamFS,可以先使用命令 bin/tachyon-mount.sh Mount workers 或 bin/tachyon-mount.sh SudoMount workers 挂载好所有RamFS,然后使用 bin/tachyon-start.sh all NoMount 命令启动Tachyon。
单机和分布式模式的区别就在于配置和启动步骤,事实上,也可以在分布式模式下只设置一个TachyonWorker(伪分布式),在这种情况下两者就基本一样了。
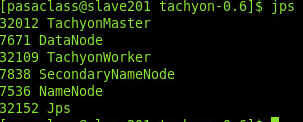
启动Tachyon后,可以用 jps 命令查看TachyonMaster和TachyonWorker进程是否存在
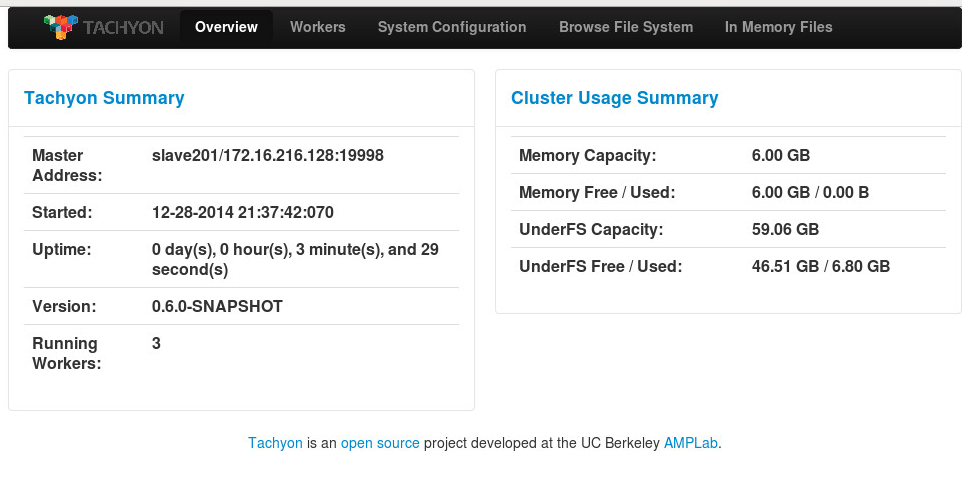
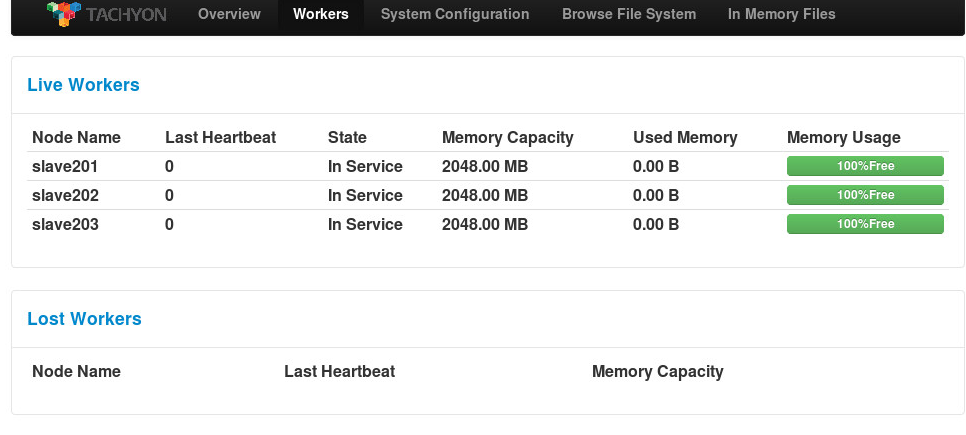
也可以在浏览器内打开Tachyon的WebUI,如 http://slave201:19999 ,查看整个Tachyon的状态,各个TachyonWorker的运行情况,各项配置信息,浏览文件系统等。
此外,还能在任一启动了TachyonWorker的节点上执行 bin/tachyon runTests 命令来测试Tachyon是否运行正常。
步骤①-④即完成了Tachyon的安装和启动,之后我们也会给出具体地如何使用Tachyon。
2. Tachyon的配置
Tachyon的可配置项远不止上面步骤②的配置文件中的那些,用户可以根据自己的需求更改Tachyon的各项配置。这里以0.6.0-SNAPSHOT版本为例,介绍Tachyon中可配置参数的具体含义。(Tachyon-0.5.0的可配置项基本上是Tachyon-0.6.0-SNAPSHOT的一个子集)
Tachyon中的可配置项分为两类,一种是系统环境变量,用于在不同脚本间共享配置信息;另一种是程序运行参数,通过-D选项传入运行Tachyon的JVM中。程序运行参数又分为通用配置(Common Configuration)、TachyonMaster配置(Master Configuration)、TachyonWorker配置(Worker Configuration)和用户配置(User Configuration)。要修改或添加这些可配置项,请修改conf/tachyon-env.sh文件。
2.1 Tachyon环境变量
- JAVA_HOME:系统中java的安装路径
- TACHYON_RAM_FOLDER:配置ramfs挂载的文件目录,默认为/mnt/ramdisk。
- TACHYON_MASTER_ADDRESS:启动TachyonMaster的地址,默认为localhost,所以在单机模式下不用更改
- TACHYON_UNDERFS_ADDRESS:Tachyon使用的底层文件系统的路径,本地文件系统(单机模式下),如"/tmp/tachyon",或HDFS,如"hdfs://ip:port"
- TACHYON_WORKER_MEMORY_SIZE:每个TachyonWorker使用的RamFS大小,默认为1GB
2.2 通用配置
- tachyon.underfs.address:Tachyon在底层文件系统的的路径,默认为$TACHYON_UNDERFS_ADDRESS
- tachyon.home:Tachyon的安装路径,启动Tachyon时为当前 tachyon 文件夹的路径
- tachyon.data.folder:Tachyon数据在底层文件系统的存放路径,默认为$TACHYON_UNDERFS_ADDRESS/tmp/tachyon/data
- tachyon.workers.folder:TachyonWorkers在底层文件系统的工作路径,默认为$TACHYON_UNDERFS_ADDRESS/tmp/tachyon/workers
- tachyon.usezookeeper:TachyonMaster是否使用ZooKeeper容错,默认为false。
- tachyon.zookeeper.adress:如果启用,ZooKeeper的地址
- tachyon.zookeeper.election.path:如果启用,Zookeeper的election文件夹路径,默认为/election
- tachyon.zookeeper.leader.path:如果启用,Zookeeper的leader文件夹路径,默认为/leader
- tachyon.underfs.hdfs.impl:实现HDFS的类,默认org.apache.hadoop.hdfs,DistributedFileSystem
- tachyon.max.columns:Tachyon中RawTable允许的最大列数,默认为1000
- tachyon.table.metadata.byte:Tachyon中RawTable元数据允许存储的最大字节数,默认为5242880,即5MB
- tachyon.underfs.glusterfs.impl:如果使用GlusterFS为底层文件系统,实现GlusterFS的类,默认为org.apache.hadoop.fs.glusterfs.GlusterFileSystem
- tachyon.underfs.glusterfs.mounts:如果使用GlusterFS为底层文件系统,GlusterFS卷的挂载目录
- tachyon.underfs.glusterfs.volumes:如果使用GlusterFS为底层文件系统,GlusterFS的卷名
- tachyon.underfs.glusterfs.mapred.system.dir:如果使用GlusterFS为底层文件系统,GlusterFS用于存放MapReduce中间数据的可选子目录,默认为glusterfs:///mapred/system
- tachyon.web.resources:Tachyon WebUI可用的资源,默认为$tachyon.home/core/src/main/webapp
- tachyon.async.enabled:是否启用异步模式,默认为false
- tachyon.underfs.hadoop.prefixes:底层使用hadoop文件系统的前缀列表,默认为"hdfs://","s3://","s3n://","glusterfs:///"
- tachyon.test.mode:是否启用测试模式,默认为false
- tachyon.master.retry:连接重试次数,默认为29
2.3 TachyonMaster配置
- tachyon.master.worker.timeout.ms:TachyonMaster和TachyonWorker心跳包失效时长,默认为60000ms
- tachyon.master.journal.folder:TachyonMaster的journal日志存放路径,默认为$TACHYON_HOME/journal/
- tachyon.master.hostname:TachyonMaster的主机名
- tachyon.master.port:TachyonMaster的远程调用通讯端口,默认为19998
- tachyon.master.web.port:TachyonMaster的WebUI端口,默认为19999
- tachyon.master.web.threads:TachyonMaster的WebUI线程数,默认为9
- tachyon.master.whitelist:可缓存的路径前缀列表,列表以逗号隔开,表示该路径下的文件能够被缓存至内存,默认为/,即根目录
- tachyon.master.temporary.folder:TachyonMaster的临时文件夹,默认为/tmp
- tachyon.master.heartbeat.interval.ms:TachyonMaster心跳包间隔时间,默认为1000ms
- tachyon.master.selector.threads:TachyonMaster的thrift监听线程数,默认为3
- tachyon.master.queue.size.per.selector:TachyonMaster的thrift消息队列长度,默认为3000
- tachyon.master.server.threads:TachyonMaster节点的thrift服务线程数,默认为CPU核数的2倍
- tachyon.master.pinlist:常驻内存的文件列表,以逗号隔开,表示该路径下的文件不会从内存中剔除,默认为null
2.4 TachyonWorker配置
- tachyon.worker.data.folder:TachyonWorker在RamFS中的工作路径,默认为$TACHYON_RAM_FOLDER/tachyonworker/
- tachyon.work.port:TachyonWorker的远程调用通讯端口,默认为29998
- tachyon.worker.data.port:TachyonWorker的数据传输服务的端口,默认为29999
- tachyon.worker.memory.size:TachyonWorker所使用的RamFS大小,默认为$TACHYON_WORKER_MEMORY_SIZE
- tachyon.worker.heartbeat.timeout.ms:TachyonWorker心跳包失效的时长,默认为10000ms
- tachyon.worker.to.master.heartbeat.interval.ms:TachyonWorker向TachyonMaster发送心跳包的时间间隔,默认为1000ms
- tachyon.worker.selector.threads:TachyonWorker的thrift监听线程数,默认为3
- tachyon.worker.queue.size.per.selector:TachyonWorker的thrift消息队列长度,默认为3000
- tachyon.worker.server.threads:TachyonWorker的thrift服务线程数,默认为CPU核数
- tachyon.worker.user.timeout.ms:TachyonWorker和用户之间心跳包失效时长,默认为10000ms
- tachyon.worker.checkpoint.threads:TachyonWorker的checkpoint线程数,默认为1
- tachyon.worker.per.thread.checkpoint.cap.mb.sec:TachyonWorker的checkpoint的速度,默认为1000MB/s
- tachyon.worker.network.type:TachyonWorker在传输文件数据时使用的传输方式,默认为NETTY,可选为NIO或NETTY
2.5 用户配置
- tachyon.user.failed.space.request.limits:用户向文件系统请求空间失败时的最大重试次数,默认为3
- tachyon.user.quota.unit.bytes:客用户一次向TachyonWorker请求的最少字节数,默认为8388608,即8MB
- tachyon.user.file.buffer.byte:用户读写文件时的缓存区大小,默认为1048576,即1MB
- tachyon.user.default.block.size.byte:用户创建文件时的默认块大小,默认为1073741824,即1GB
- tachyon.user.remote.read.buffer.size.byte:用户读远程文件时的缓冲区大小,默认为1048576,即1MB
- tachyon.user.heartbeat.interval.ms:用户心跳包时间间隔,默认为1000ms
- tachyon.user.file.writetype.default:用户在使用tachyon.hadoop.TFS时的默认写类型,默认为CACHE_THROUGH
3. Tachyon的使用
受益于Tachyon良好的设计和兼用性,用户可以很方便地将现有的利用HDFS进行存储的程序移植至Tachyon。同时,Tachyon也提供了自己的命令行工具和一套完整的文件系统API,用户可以灵活地使用Tachyon。
3.1 从HDFS到Tachyon
对于现有的运行在Hadoop MapReduce或者Spark上,使用 "hdfs://ip:port/" 为存储路径的程序,能够很方便地移植至Tachyon。
3.1.1 Hadoop MapReduce
- 将tachyon-client jar包添加至$HADOOP_CLASSPATH,jar包位于 tachyon/client/target/tachyon-client-0.6.0-SNAPSHOT-jar-with-dependencies.jar(如果是Tachyon-0.5.0,则文件名为tachyon-client-0.5.0-jar-with-dependencies.jar)
- 添加配置项<”fs.tachyon.impl”, ” tachyon.hadoop.TFS”>,可以在core-site.xml文件中添加,也可以在程序中使用Configuration.set()方法添加
- 将原有的”hdfs://ip:port/path”路径更改为”tachyon://ip:port/path”
3.1.2 Spark
同样地,添加依赖包,添加配置项,然后更改文件系统路径。
额外地,添加配置项<”spark.tachyonStore.url”, “tachyon://ip:port/”>后,能够使用”rdd.persist(StorageLevel.OFF_HEAP)”语句将Spark RDD缓存至Tachyon中以减少Java GC的开销。
3.2 命令行工具
Tachyon提供了命令行工具为用户提供了简单的交互功能,使用方式为
- bin/tachyon tfs [COMMAND]
具体的命令有:
- cat:将文件内容输出到控制台
- count:输出符合路径前缀的文件总数
- ls:输出目录中的文件信息
- lsr:递归输出目录中的文件信息
- mkdir:创建指定目录包括路径中的父目录,如果目录已经存在则创建失败
- rm:删除文件或者目录
- tail:将文件的最末1KB输出到控制台
- touch:在指定的位置创建空的文件
- mv:将文件移动到指定位置
- copyFromLocal:将文件从本地文件系统拷贝到Tachyon文件系统指定位置
- copyToLocal:将文件从Tachyon文件系统拷贝到本地文件系统指定位置
- fileinfo:打印指定文件的块信息
- pin:将指定文件常驻内存
- unpin:将常驻内存的文件撤销常驻状态
3.3 Java API
Tachyon是用Java开发实现的,因此提供的API也是Java函数。要使用这些API需要依赖tachyon-client jar包,位于 tachyon/client/target/tachyon-client-0.6.0-SNAPSHOT-jar-with-dependencies.jar (如果是Tachyon-0.5.0,则文件名为tachyon-client-0.5.0-jar-with-dependencies.jar)此外,如果是已发布的Tachyon-0.5.0并且目标项目由Maven管理,可以在 pom.xml 文件中添加如下内容以获取依赖包:
- <dependency>
- <groupId>org.tachyonproject</groupId>
- <artifactId>tachyon-client</artifactId>
- <version>0.5.0</version>
- </dependency>
(Tachyon-0.5.0和Tachyon-0.6.0-SNAPSHOT提供的Java API一大不同之处在于Tachyon-0.6.0-SNAPSHOT中新增了tachyon.TachyonURI类,用来表示Tachyon文件系统中的路径,类似于Hadoop中的org.apache.hadoop.fs.Path。Tachyon-0.5.0中的大部分API在Tachyon-0.6.0-SNAPSHOT中仍然存在,但被标记为@Deprecated)
Tachyon的Java API功能大部分集中于tachyon.client.TachyonFS和tachyon.client.TachyonFile两个类中
3.3.1 TachyonFS
- //获取TachyonFS对象
- public static TachyonFS get(String tachyonPath) throws IOException
- public static TachyonFS get(final TachyonURI tachyonURI) throws IOException
- public static TachyonFS get(String masterHost, int masterPor boolean zookeeperMode) throws IOException
- //创建Tachyon文件
- public int createFile(String path) throws IOException
- public int createFile(TachyonURI path, TachyonURI ufsPath, long blockSizeByte,boolean recursive) throws IOException
- //删除Tachyon文件
- public boolean delete(String path,boolean recursive) throws IOException
- public boolean delete(int fileId, TachyonURI path, boolean recursive) throws IOException
- //判断文件是否存在
- public boolean exist(TachyonURI path) throws IOException
- //获取TachyonFile对象
- public TachyonFile getFile(int fid) throws IOException
- public TachyonFile getFile(int fid,boolean useCachedMetadata) throws IOException
- public TachyonFile getFile(String path) throws IOException
- public TachyonFile getFile(TachyonURI path) throws IOException
- public TachyonFile getFile(String path,boolean useCachedMetadata) throws IOException
- public TachyonFile getFile(TachyonURI path, boolean useCachedMetadata) throws IOException
- //判断文件是否为目录
- boolean isDirectory(int fid)
- //获取文件状态信息
- public ClientFileInfo getFileStatus(int fileId, TachyonURI path) throws IOException
- public ClientFileInfo getFileStatus(int fileId, boolean useCachedMetadata) throws IOException
- public ClientFileInfo getFileStatus(int fileId, TachyonURI path,boolean useCachedMetadata) throws IOException
- //列出指定目录下的文件信息,如果是文件则列出该文件的文件信息
- public List<ClientFileInfo> listStatus(TachyonURI path) throws IOException
- //创建指定的目录
- public boolean mkdirs(TachyonURI path, boolean recursive) throws IOException
- //重命名文件
- public boolean rename(int fileId, TachyonURI srcPath, TachyonURI dstPath) throws IOException
- //设置文件是否常驻内存
- public void setPinned(int fid,boolean pinned) throws IOException
- //设置文件常驻内存
- public void pinFile(int fid) throws IOException
- //取消文件常驻内存状态
- public void unpinFile(int fid) throws IOException
- //判断文件是否常驻内存
- public boolean isPinned(int fid,boolean useCachedMetadata) throws IOException
3.3.2 TachyonFile
- //获取TachyonFile的输入流,ReadType的类型为CACHE或NO_CACHE
- public InStream getInStream(ReadType readType) throws IOException
- //获取TachyonFile的输出流,WriteType的类型为MUST_CACHE,TRY_CACHE,CACHE_THROUGH,THROUGH或ASYNC_THROUGH
- public OutStream getOutStream(WriteType writeType) throws IOException
- //获取文件的路径
- public String getPath()
- //获取底层文件系统的配置
- public Object getUFSConf()
- //判断文件是否完整
- public boolean isComplete() throws IOException
- //判断是否为目录
- public boolean isDirectory()
- //判断是否为文件
- public boolean isFile()
- //判断文件是否全在内存
- public boolean isInMemory() throws IOException
- //获取文件的长度
- public long length() throws IOException
- //判断文件是否常驻内存
- public boolean needPin()
- //重命名文件
- public boolean rename(TachyonURI path) throws IOException
- //设置底层文件系统的配置
- public void setUFSConf(Object conf)
- //获取文件的创建时间
- public long getCreationTimeMs()
- //获取对应块所属的文件名
- public String getLocalFilename(int blockIndex) throws IOException
- //获取文件所在的主机集合
- public List<String> getLocationHosts() throws IOException
- //获取文件的块数
- public int getNumberOfBlocks() throws IOException
3.3.3 Tachyon Java API使用Demo
这个Demo使用了上面介绍的Java API实现简单的Tachyon文件读写操作。
- <pre name="code" class="java">import java.io.IOException;
- import tachyon.TachyonURI;
- import tachyon.client.FileOutStream;
- import tachyon.client.InStream;
- import tachyon.client.OutStream;
- import tachyon.client.ReadType;
- import tachyon.client.TachyonFS;
- import tachyon.client.TachyonFile;
- import tachyon.client.WriteType;
- import tachyon.util.CommonUtils;
- /*
- *
- * 将0~9的数字写到tachyon文件/tmp/test,然后将写入的文件内容读出到控制台。
- *
- */
- public class test {
- public final TachyonURI masteruri = new TachyonURI("tachyon://slave201:19998");
- public final TachyonURI filepath = new TachyonURI("/tmp/test");
- public WriteType writeType = WriteType.CACHE_THROUGH;
- public ReadType readType = ReadType.CACHE;
- public static void writeFile() throws IOException
- {
- TachyonFS tachyonClient = TachyonFS.get(masteruri);
- if(tachyonClient.exist(filepath)) {
- tachyonClient.delete(filepath, true);
- }
- tachyonClient.createFile(filepath);
- TachyonFile file = tachyonClient.getFile(filepath);
- FileOutStream os = (FileOutStream) file.getOutStream(writeType);
- for(int i = 0; i < 10; i ++)
- {
- os.write(Integer.toString(i).getBytes());
- }
- os.close();
- tachyonClient.close();
- }
- public static void readFile() throws IOException
- {
- TachyonFS tachyonClient = TachyonFS.get(masteruri);
- TachyonFile file = tachyonClient.getFile(filepath);
- InStream in = file.getInStream(readType);
- byte[] bytes = new byte[20];
- in.read(bytes);
- System.out.println(new String(bytes));
- in.close();
- tachyonClient.close();
- }
- public static void main(String[] args) throws IOException
- {
- writeFile();
- readFile();
- }
- }
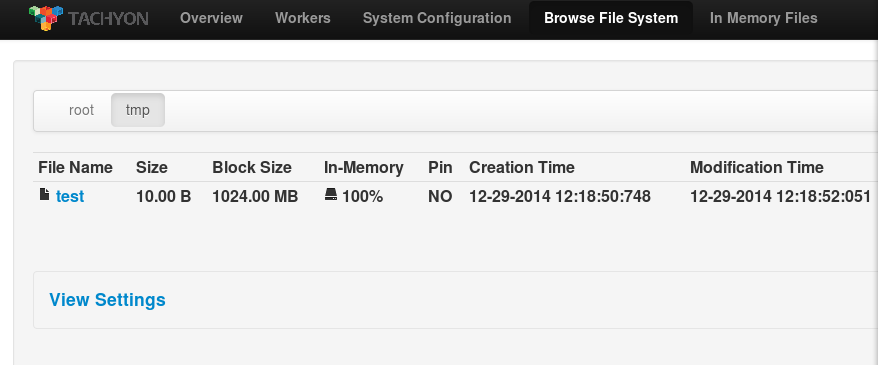
执行后在Tachyon的WebUI上可以查看测试文件的信息,文件内容为预期的字符串"0123456789"
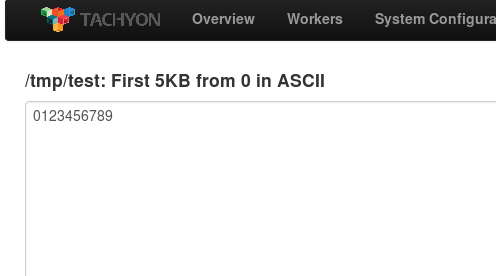
这篇关于Tachyon的安装、配置和使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







