本文主要是介绍Tachyon简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Tachyon是什么
Tachyon(/'tæki:ˌɒn/ 意为超光速粒子)是以内存为中心的分布式文件系统,拥有高性能和容错能力,能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。Tachyon诞生于UC Berkeley的AMPLab,由该实验室的李浩源童鞋初创。2012年12月,Tachyon发布了第一个版本0.1.0。到2014年12月,Tachyon的最新发布版版本为0.5.0,并且正在开发0.6.0版本。目前(2014年12月),已有50多家公司开始使用Tachyon,超过20家公司(如 Intel, Yahoo, Pivotal, Redhat,Baidu等)为Tachyon的开发进行了贡献,在GitHub上Tachyon的贡献者也已上升到55人。南京大学PASALab从早期就开始和Tachyon Community一起从事着该项目的建设和开发工作。
从软件栈的层次来看,Tachyon是位于现有大数据计算框架和大数据存储系统之间的独立的一层。它利用底层文件系统作为备份,对于上层应用来说,Tachyon就是一个分布式文件系统。
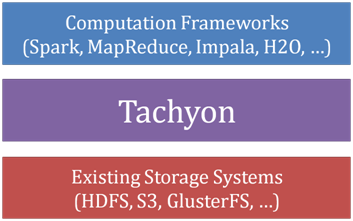
其最初出现是为了解决如下问题:
-
大数据分析流水线中数据共享通过基于磁盘文件系统(HDFS等)性能比较缓慢;
-
大数据计算引擎的处理进程(Spark的Executor,MapReduce的Child JVM等)崩溃出错后,缓存的数据也会全部丢失;
-
基于内存的系统存储数据冗余,对象太多会导致Java GC时间过长;
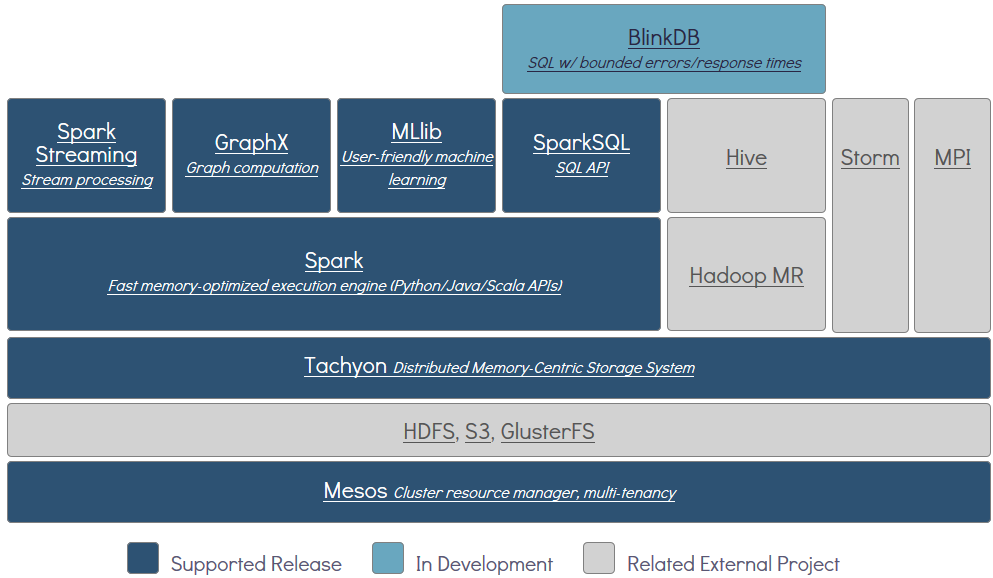
另外,如下图所示,Tachyon属于伯克利大数据分析软件栈(Berkeley Data Analytics Stack)中的存储层软件。
2. 如何使用Tachyon
受益于Tachyon良好的设计和兼用性,用户可以很方便地将现有的利用HDFS进行存储的程序移植至Tachyon,只需要简单的两步:添加配置项,修改文件路径。
2.1 对于MapReduce程序
添加配置项<”fs.tachyon.impl”, ” tachyon.Hadoop.TFS”>,可以在core-site.xml文件中添加,也可以在程序中使用Configuration.set()方法添加。将原有的”hdfs://ip:port/path”路径更改为”tachyon://ip:port/path”。
需要注意的是,由于Hadoop默认不依赖于Tachyon,还要将Tachyon的jar包添加至$HADOOP_CLASSPATH中。
2.2 对于Spark程序
同样地,添加配置项<”fs.tachyon.impl”, ” tachyon.hadoop.TFS”>。将原有的”hdfs://ip:port/path”路径更改为”tachyon://ip:port/path”。
额外地,添加配置项<”spark.tachyonStore.url”, “tachyon://ip:port/”>后,能够使用”rdd.persist(StorageLevel.OFF_HEAP)”语句将RDD缓存至Tachyon中以减少Java GC的开销。
2.3 其他使用方式
为了方便用户使用,Tachyon还提供了命令行工具,能够对Tachyon进行简单的交互
tachyon tfs cat|ls|mkdir|rm|copyFromLocal|…
此外,Tachyon也有自己的一套API,使用该API能够很灵活地访问Tachyon文件系统,并充分利用Tachyon的各个特性以获得最佳性能。
TachyonFS.createFile|delete|mkdir|rename|…
TachyonFile.getInStream|getOutStream|getPath|…
3. Tachyon基本工作原理
这里对Tachyon的基本工作原理进行概述性的介绍,包括Tachyon的整体架构、文件组织、读写类型、Tachyon的容错机制和心跳机制等。更新详细的介绍以及Tachyon的其他功能,我会在之后的博客中结合源码分析给出。
3.1 整体架构
Tachyon整体架构如下左图所示,采用了Master-Worker模式,运行中的Tachyon系统由一个Master和多个Worker构成。Tachyon Master支持ZooKeeper进行容错,用于管理全部文件的元数据信息,同时也负责监控各个Tachyon Worker的状态。每个Tachyon Worker启动一个守护进程,管理本地的Ramdisk,Ramdisk中存储了具体的文件数据。这里也可以看出,Ramdisk就是Tachyon“以内存为中心”的内存部分。
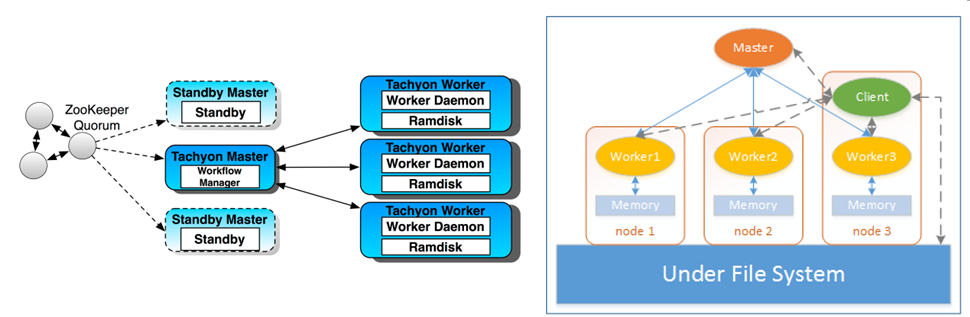
在右图中,添加了Tachyon Client和Under File System(UFS,底层文件系统)部分来说明具体的工作方式。UFS对于Tachyon来说是一个备份,内存中的文件丢失后能够从UFS中恢复。所有上层应用都通过Tachyon Client对Tachyon进行操作,Client对Master进行文件的元数据操作,通过Worker访问内存中的文件数据,若文件不在内存中,Client还能够访问UFS。
3.2 文件组织和读写类型
为了高效地对文件进行管理,Tachyon文件在内存中按块(Block)组织。文件和块信息保存在Master端,每个Worker以块为单位进行存储和管理,一个块可以同时被缓存在不同Worker的内存中。在UFS中,以文件形式对Tachyon文件进行备份。
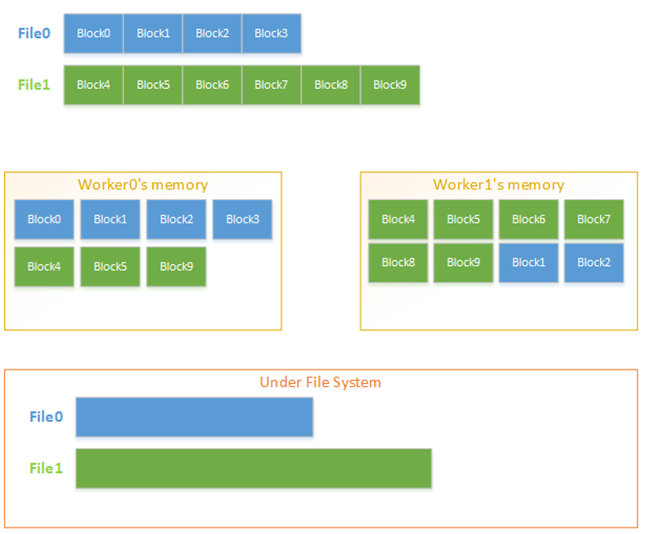
由于Tachyon文件存储位置的多样性(内存,UFS),Tachyon API提供了多种文件读写类型以处理不同情况。
读类型: CACHE – 读取数据并缓存在本地内存
NO_CACHE – 读取数据但不缓存在本地内存
写类型: MUST_CACHE – 只写本地内存,空间不足时报ERROR
TRY_CACHE – 只写本地内存,空间不足时报WARNING
THROUGH – 只写UFS
CACHE_THROUGH – 同时写本地内存和UFS(TRY_CACHE + THROUGH)
ASYNC_THROUGH– 先写本地内存,异步备份到UFS
3.3 容错机制
作为分布式文件系统,Tachyon具有良好的容错机制,Master和Worker都有自己的容错方式。
从之前的系统架构图中也可看出,Master支持使用ZooKeeper进行容错。同时,Master中保存的元数据使用Journal进行容错,具体包括Editlog——记录所有对元数据的操作,以及Image——持久化元数据信息。此外,Master还对各个Worker的状态进行监控,发现Worker失效时会自动重启对应的Worker。
对于具体的文件数据,使用血统关系(Lineage)进行容错。文件元数据中记录了文件之间的依赖关系,当文件丢失时,能够根据依赖关系进行重计算来恢复文件数据。
3.4 心跳机制
在Tachyon中,心跳(HeartBeat)用于两个方面:Master, Worker, Client之间的定期通信;Master, Worker自身的定期状态自检。具体地:
- Client向Master发送心跳信号:表示Client仍处于连接中,Client释放连接后重新连接会获得新的UserId
- Client向Worker发送心跳信号:表示Client仍处于连接中,释放连接后Worker会回收该Client的用户空间
- Worker自检,同时向Master发送心跳信号:Worker将自己的存储空间信息更新给Master(容量,移除的块信息),同时清理超时的用户,回收用户空间
- Master自检:检查所有Worker的状态,若有Worker失效,会统计丢失的文件并尝试重启该Worker
这篇关于Tachyon简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








