本文主要是介绍Tachyon:Spark生态系统中的分布式内存文件系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(转自:http://www.csdn.net/article/2015-06-25/2825056)
Tachyon是Spark生态系统内快速崛起的一个新项目。 本质上, Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 以求通过更细的分工达到更高的执行效率。 本文将先向读者介绍Tachyon在Spark生态系统中的使用, 也将分享百度在大数据平台上利用Tachyon取得的性能改善的用例,以及在实际使用Tachyon过程中遇到的一些问题和解决方案。最后我们将介绍一下Tachyon的一些新功能。
Tachyon简介
Spark平台以分布式内存计算的模式达到更高的计算性能,在最近引起了业界的广泛关注,其开源社区也十分活跃。以百度为例,在百度内部计算平台已经搭建并运行了千台规模的Spark计算集群,百度也通过其BMR的开放云平台对外提供Spark计算平台服务。然而,分布式内存计算的模式也是一柄双刃剑,在提高性能的同时不得不面对分布式数据存储所产生的问题,具体问题主要有以下几个:
当两个Spark作业需要共享数据时,必须通过写磁盘操作。比如:作业1要先把生成的数据写入HDFS,然后作业2再从HDFS把数据读出来。在此,磁盘的读写可能造成性能瓶颈。
由于Spark会利用自身的JVM对数据进行缓存,当Spark程序崩溃时,JVM进程退出,所缓存数据也随之丢失,因此在工作重启时又需要从HDFS把数据再次读出。
当两个Spark作业需操作相同的数据时,每个作业的JVM都需要缓存一份数据,不但造成资源浪费,也极易引发频繁的垃圾收集,造成性能的降低。
仔细分析这些问题后,可以确认问题的根源来自于数据存储,由于计算平台尝试自行进行存储管理,以至于Spark不能专注于计算本身,造成整体执行效率的降低。Tachyon的提出就是为了解决这些问题:本质上,Tachyon是个分布式的内存文件系统,它在减轻Spark内存压力的同时赋予了Spark内存快速大量数据读写的能力。Tachyon把存储与数据读写的功能从Spark中分离,使得Spark更专注在计算的本身,以求通过更细的分工达到更高的执行效率。
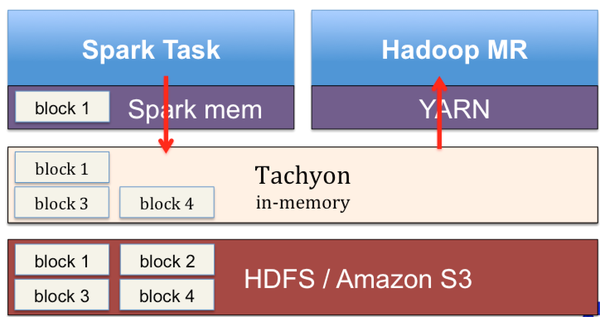
图1显示了Tachyon的部署结构。Tachyon被部署在计算平台(Spark,MR)之下以及存储平台(HDFS, S3)之上,通过全局地隔离计算平台与存储平台, Tachyon可以有效地解决上文列举的几个问题,:
当两个Spark作业需要共享数据时,无需再通过写磁盘,而是借助Tachyon进行内存读写,从而提高计算效率。
在使用Tachyon对数据进行缓存后,即便在Spark程序崩溃JVM进程退出后,所缓存数据也不会丢失。这样,Spark工作重启时可以直接从Tachyon内存读取数据了。
当两个Spark作业需要操作相同的数据时,它们可以直接从Tachyon获取,并不需要各自缓存一份数据,从而降低JVM内存压力,减少垃圾收集发生的频率。
Tachyon系统架构
在上一章我们介绍了Tachyon的设计,本章我们来简单看看Tachyon的系统架构以及实现。 图2显示了Tachyon在Spark平台的部署:总的来说,Tachyon有三个主要的部件:Master, Client,与Worker。在每个Spark Worker节点上,都部署了一个Tachyon Worker,Spark Worker通过Tachyon Client访问Tachyon进行数据读写。所有的Tachyon Worker都被Tachyon Master所管理,Tachyon Master通过Tachyon Worker定时发出的心跳来判断Worker是否已经崩溃以及每个Worker剩余的内存空间量。
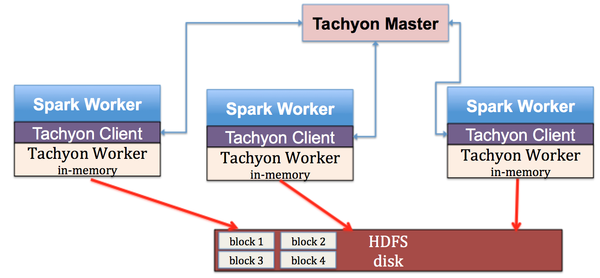
图3显示了Tachyon Master的结构,其主要功能如下:首先,Tachyon Master是个主管理器,处理从各个Client发出的请求,这一系列的工作由Service Handler来完成。这些请求包括:获取Worker的信息,读取File的Block信息, 创建File等等;其次,Tachyon Master是个Name Node,存放着所有文件的信息,每个文件的信息都被封装成一个Inode,每个Inode都记录着属于这个文件的所有Block信息。在Tachyon中,Block是文件系统存储的最小单位,假设每个Block是256MB,如果有一个文件的大小是1GB,那么这个文件会被切为4个Block。每个Block可能存在多个副本,被存储在多个Tachyon Worker中,因此Master里面也必须记录每个Block被存储的Worker地址;第三,Tachyon Master同时管理着所有的Worker,Worker会定时向Master发送心跳通知本次活跃状态以及剩余存储空间。Master是通过Master Worker Info去记录每个Worker的上次心跳时间,已使用的内存空间,以及总存储空间等信息。
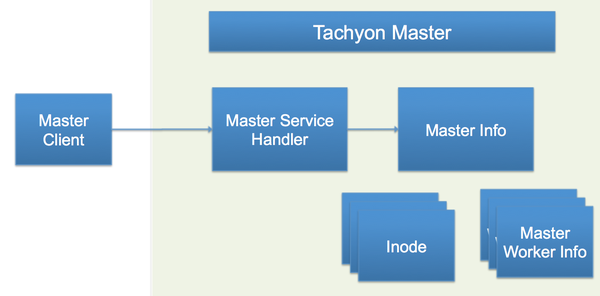
图4显示了Tachyon Worker的结构,它主要负责存储管理:首先,Tachyon Worker的Service Handler处理来自Client发来的请求,这些请求包括:读取某个Block的信息,缓存某个Block,锁住某个Block,向本地内存存储要求空间等等。第二,Tachyon Worker的主要部件是Worker Storage,其作用是管理Local Data(本地的内存文件系统)以及Under File System(Tachyon以下的磁盘文件系统,比如HDFS)。第三,Tachyon Worker还有个Data Server以便处理其他的Client对其发起的数据读写请求。当由请求达到时,Tachyon会先在本地的内存存储找数据,如果没有找到则会尝试去其他的Tachyon Worker的内存存储中进行查找。如果数据完全不在Tachyon里,则需要通过Under File System的接口去磁盘文件系统(HDFS)中读取。
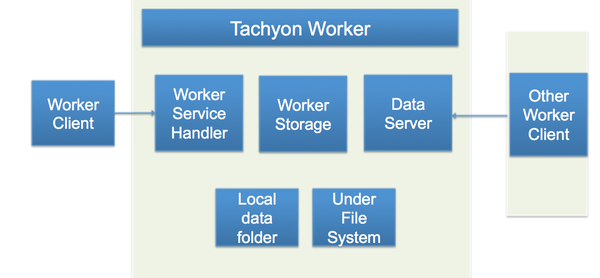
图5显示了Tachyon Client的结构,它主要功能是向用户抽象一个文件系统接口以屏蔽掉底层实现细节。首先,Tachyon Client会通过Master Client部件跟Tachyon Master交互,比如可以向Tachyon Master查询某个文件的某个Block在哪里。Tachyon Client也会通过Worker Client部件跟Tachyon Worker交互, 比如向某个Tachyon Worker请求存储空间。在Tachyon Client实现中最主要的是Tachyon File这个部件。在Tachyon File下实现了Block Out Stream,其主要用于写本地内存文件;实现了Block In Stream主要负责读内存文件。在Block In Stream内包含了两个不同的实现:Local Block In Stream主要是用来读本地的内存文件,而Remote Block In Stream主要是读非本地的内存文件。请注意,非本地可以是在其它的Tachyon Worker的内存文件里,也可以是在Under File System的文件里。
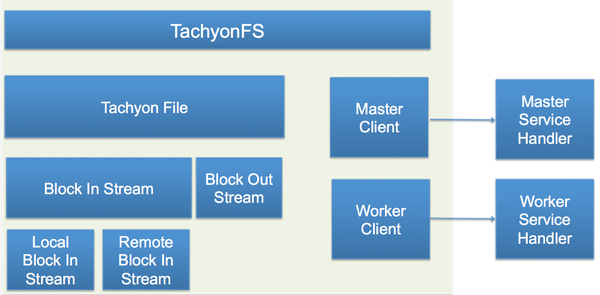
现在我们通过一个简单的场景把各个部件都串起来:假设一个Spark作业发起了一个读请求,它首先会通过Tachyon Client去Tachyon Master查询所需要的Block所在的位置。如果所在的Block不在本地的Tachyon Worker里,此Client则会通过Remote Block In Stream向别的Tachyon Worker发出读请求,同时在Block读入的过程中,Client也会通过Block Out Stream把Block写入到本地的内存存储里,这样就可以保证下次同样的请求可以由本机完成。
Tachyon在百度内部的使用
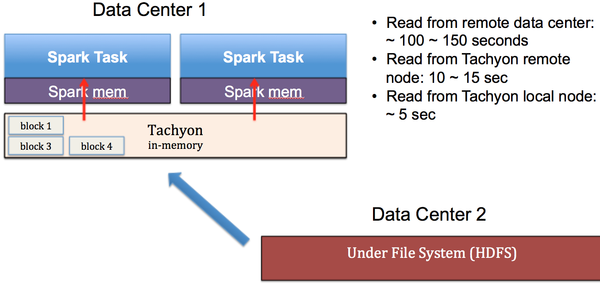
在百度内部,我们使用Spark SQL进行大数据分析工作, 由于Spark是个基于内存的计算平台,我们预计绝大部分的数据查询应该在几秒或者十几秒完成以达到互动查询的目的。可是在Spark计算平台的运行中,我们却发现查询都需要上百秒才能完成,其原因如图6所示:我们的计算资源(Data Center 1)与数据仓库(Data Center 2)可能并不在同一个数据中心里面,在这种情况下,我们每一次数据查询都可能需要从远端的数据中心读取数据,由于数据中心间的网络带宽以及延时的问题,导致每次查询都需要较长的时间(>100秒)才能完成。更糟糕的是,很多查询的重复性很高,同样的数据很可能会被查询多次,如果每次都从远端的数据中心读取,必然造成资源浪费。
为了解决这个问题,我们借助Tachyon把数据缓存在本地,尽量避免跨数据中心调数据。当Tachyon被部署到Spark所在的数据中心后,每次数据冷查询时,我们还是从远端数据仓库拉数据,但是当数据再次被查询时,Spark将从同一数据中心的Tachyon中读取数据,从而提高查询性能。实验表明:如果从非本机的Tachyon读取数据,耗时降到10到15秒,比原来的性能提高了10倍;最好的情况下,如果从本机的Tachyon读数据,查询仅需5秒,比原来的性能提高了30倍,效果相当明显。
在使用了这个优化后,热查询性能达到了互动查询的要求,可是冷查询的用户体验还是很差。分析了用户行为后,我们发现用户查询的模式比较固定:比如很多用户每天都会跑同一个查询,只是所使用过滤数据的日期会发生改变。借助这次特性,我们可以根据用户的需求进行线下预查询,提前把所需要的数据导入Tachyon,从而避免用户冷查询。
在使用Tachyon过程中,我们也遇到了一些问题:在刚开始部署Tachyon的时候, 我们发现数据完全不能被缓存,第一次与后续的查询耗时是一样的。如图7的源代码所示:只有整个数据Block被读取后,这个Block才会被缓存住;否则缓存的操作会被取消。比如一个Block是256MB,如果你读了其中的255MB,这个Block还是不会被缓存,因为它只需读取整个block中的部分数据。在百度内部,我们很多数据是用行列式存储的,比如ORC与Parquet文件,每次查询只会读其中的某几列, 因此不会读取完整的Block, 以致block缓存失败。为了解决这个问题,我们对Tachyon进行了修改,如果数据Block不是太大的话,冷查询时即使用户请求的只是其中几列,我们也会把整个Block都读进来,保证整个Block能被缓存住,然后再次查询的话就可以直接从Tachyon读取了。在使用了修改的版本后,Tachyon达到了我们期待的效果,大部分查询可以在10秒内完成。

Tachyon的一些新功能
我们把Tachyon当作缓存来使用,但是每台机器的内存有限,内存很快会被用完。 如果我们有50台机器,每台分配20GB的内存给Tachyon,那么总共也只有1TB的缓存空间,远远不能满足我们的需要。在Tachyon最新版本有一个新的功能: Hierarchical Storage,即使用不同的存储媒介对数据分层次缓存。如图8所示,它类于CPU的缓存设计:内存的读写速度最快所以可以用于第0级缓存,然后SSD可以用于第1级缓存,最后本地磁盘可以作为底层缓存。这样的设计可以为我们提供更大的缓存空间,同样50台机器,现在我们每台可贡献出20TB的缓存空间,使总缓存空间达到1PB,基本可以满足我们的储存需求。与CPU缓存类似,如果Tachyon的block Replacement Policy设计得当,99%的请求可以被第0级缓存(内存)所满足,从而在绝大部分时间可以做到秒级响应。
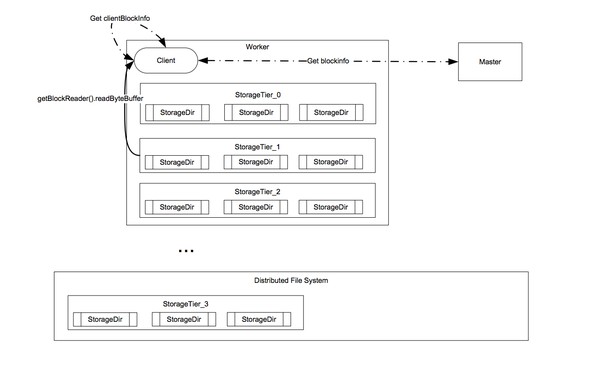
当Tachyon收到读请求时,它首先检查数据是否在第0层,如果命中,直接返回数据,否则它会查询下一层缓存,直到找到被请求的数据为止。数据找到后会直接返回给用户,同时也会被Promote到第0层缓存,然后第0层被替换的数据Block会被LRU算法置换到下一层缓存。如此一来,如果用户再次请求相同的数据就会直接从第0层快速得到,从而充分发挥缓存的Locality特性。
当Tachyon收到写请求时,它首先检查第0层是否有足够空间,如果有,则直接写入数据后返回。否则它会查询下一层缓存,直到找到一层缓存有足够空间,然后把上一层的一个Block用LRU算法推到下一层,如此类推,直到把第0层有足够空间以写入新的数据,然后再返回。这么做的目的是保证数据被写入第0层,如果读请求马上发生在写请求后,数据可以快速被读取。可是,这样做的话写的性能有可能变的很差:比如头两层缓存都满的话,它需要把一个Block从第1层丢到第2层,再把一个Block从第0层丢到第1层,然后才能写数据到第0层,再返回给用户。
对此我们做了个优化, 与其层层类推腾出空间,我们的算法直接把数据写入有足够空间的缓存层,然后快速返回给用户。如果缓存全满,则把底层的一个Block置换掉,然后把数据写入底层缓存后返回。经过实验,我们发现优化后的做法会把写延时降低约50%,大大的提高了写的效率。但是读的效率又如何呢,由于在TACHYON里,写是通过Memory-Mapped File进行的,所以是先写入内存,再Flush到磁盘,如果读是马上发生在写之后的话,其实会从操作系统的Buffer,也就是内存里读数据,因此读的性能也不会下降。
Hierarchical Storage很好地解决了我们缓存不够用的问题,下一步我们将继续对其进行优化。比如,现在它只有LRU一种置换算法,并不能满足所有的应用场景, 我们将针对不同的场景设计更高效的置换算法,尽量提高缓存命中率。
结语
我个人相信更细的分工会达到更高的效率,Spark作为一个内存计算平台,如果使用过多的资源去缓存数据,会引发频繁的垃圾收集,造成系统的不稳定,或者影响性能。在我们使用Spark的初期,系统不稳定是我们面临的最大挑战,而频繁的垃圾收集正是引起系统不稳定最大的原因。比如当一次垃圾收集耗时过长时,Spark Worker变的响应非常不及时,很容易被误认为已经崩溃,导致任务重新执行。Tachyon通过把内存存储的功能从Spark中分离出来,让Spark更专注在计算本身,从而很好的解决了这个问题。随着内存变的越来越便宜,我们可以预期未来一段时间里,我们的服务器里可使用的内存会不断增长,Tachyon会在大数据平台中发挥越来越重要的作用。现在还是Tachyon发展的初期,在本文完成时Tachyon才准备发布0.6版,还有很多功能亟需完善,这也是一个好机遇,有兴趣的同学们可以多关注Tachyon,到社区里进行技术讨论以及功能开发。
这篇关于Tachyon:Spark生态系统中的分布式内存文件系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







