separation专题
![[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction](https://i-blog.csdnimg.cn/blog_migrate/a81ef8f36f1400d5367d93036bc14ef7.png)
[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction
论文地址:https://www.aclweb.org/anthology/D18-1125.pdf发表会议:EMNLP2019 本论文的主要任务是跨领域的关系抽取,具体来说,利用某个领域的数据训练好的关系抽取模型,很难去直接抽取另一个领域中的关系,比如我们拿某个领域训练好的模型,把另一个领域的数据直接输入整个模型,很难抽取出来正确的实体关系。这主要是因为源领域和目标领域特征表达的不同,在源
![代码解读 | Hybrid Transformers for Music Source Separation[07]](https://img-blog.csdnimg.cn/direct/bd7f2cf5977e487a9c05fa8cb6704cd8.png)
代码解读 | Hybrid Transformers for Music Source Separation[07]
一、背景 0、Hybrid Transformer 论文解读 1、代码复现|Demucs Music Source Separation_demucs架构原理-CSDN博客 2、Hybrid Transformer 各个模块对应的代码具体在工程的哪个地方 3、Hybrid Transformer 各个模块的底层到底是个啥(
![代码解读 | Hybrid Transformers for Music Source Separation[04]](https://img-blog.csdnimg.cn/direct/91c35eac4bbd4ba38875c2b992e5fd77.png)
代码解读 | Hybrid Transformers for Music Source Separation[04]
一、背景 0、Hybrid Transformer 论文解读 1、代码复现|Demucs Music Source Separation_demucs架构原理-CSDN博客 2、Hybrid Transformer 各个模块对应的代码具体在工程的哪个地方 3、Hybrid Transformer 各个模块的底层到底是个啥(

机器学习之低密度分离(Low-density Separation)
概念 低密度分离(Low-density Separation)是一种机器学习中的算法技术,主要用于处理高维数据空间中的分类问题。它的核心思想是通过在数据空间中寻找“低密度”区域的边界来实现分类。 这里的“低密度”指的是数据分布中相对稀疏的区域,即与其他类别的数据点相比较为孤立的区域。低密度分离算法试图找到这些低密度区域的边界,将不同类别的数据点有效地分隔开来。 低密度分离的一种常见方法是局

p0001--汪德亮2018--Supervised Speech Separation Based on DeepLearning: An Overview
今天开始看汪德亮的Supervised Speech Separation Based on DeepLearning: An Overview做一个翻译为主的个人笔记 abstract:语音分离是指将目标语音从背景干扰中分离出来,传统的方式是从信号处理的角度解决的。最近,多种监督学习的算法用于语音分离,尤其是基于深度学习的监督算法,大大提升了分离的性能。本文主要介绍近几
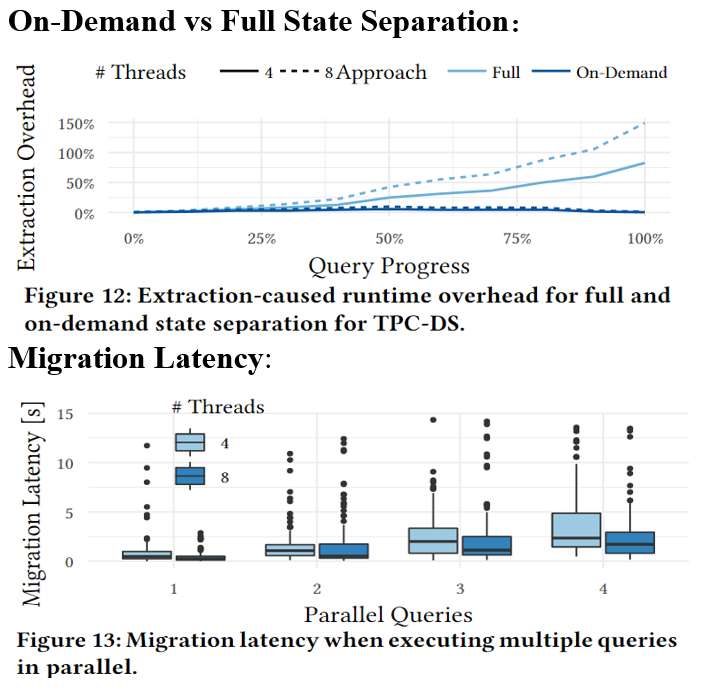
【论文阅读 VLDB22】On-Demand State Separation for Cloud Data Warehousing
On-Demand State Separation for Cloud Data Warehousing 问题背景 首先是问题背景,目前除了大规模PB级别的AP会使用云数据库,越来越多的百G大小的中小规模的负载也开始进行上云分析和处理,而这些ap任务不需要消耗整个集群的资源,往往只需要单个节点运行。 那么这个过程中,如何选择合适的工作机就是一个问题,考虑到负载变化以及降低成本或者需要提高算力
开源框架springboot-mybatis-wr-separation实现springboot+mybatis读写分离
最近做springboot+mybatis的项目想要用到读写分离,查了一圈发现大家都是自己写的,没用通用现成的读写分离架构,因此就写了一个比较简单好用的小插件,来帮助大家简单的实现读写分离的功能,项目已开源并已经上传到maven中央仓库,欢迎提出宝贵意见,共同改进。 springboot-mybatis-wr-separation 介绍 springboot-mybatis-wr-separa

【SELF-SUPERVISED LEARNING-BASED SOURCE SEPARATION FOR MEETING DATA】论文翻译
论文来源:ICASSP2023 标题:SELF-SUPERVISED LEARNING-BASED SOURCE SEPARATION FOR MEETING DATA 作者:Yuang Li, Xianrui Zheng, Philip C. Woodland 机构:Cambridge University Engineering Dept., Trumpington St., Cambridg

论文研究11:Audio-visual Speech Separation with Adversarially Disentangled Visual Representation
论文研究11:Audio-visual Speech Separation with Adversarially Disentangled Visual Representation abstract 语音分离旨在从多个同时讲话者的音频混合中分离出单个语音。尽管仅音频方法具有令人满意的性能,但它们基于处理预定义条件的策略,从而限制了它们在复杂听觉场景中的应用。针对鸡尾酒会问题,我们提出了一种新

Domain Separation Networks-论文笔记
目的:what to transfer,以及如何有效避免negative transfer上。 假设:所有的域之间有着公有的特征(Shared)和私有的特征(Private),如果将各个域的私有特征也进行迁移的话就会造成负迁移(negative transfer)。 基于此,提出了Domain Separation Networks(DSNs)。 Domain Separation Netw

Safe and Efficient Implementation of a Security System on ARM using Intra-level Privilege Separation
版权声明:本文为CSDN博主「ashimida@」翻译的文章,转载请附上出处链接和本声明。 本文链接:https://blog.csdn.net/lidan113lidan/article/details/119395558 更多内容可关注微信公众号 内容摘要: 此文中作者介绍了ARM64中一种同特权级下(EL1/2/3)下系统自隔离的方法——Hilps, 此方法和之前学术界的S

语音分离speech separation数据准备,开源
Speech separation 现在大热的一个方向,西雅图的腾讯一直在作者方面的研究,chime6上俞老师讲了一个多小时的他们的工作就能证明该方向有多火, 当前有很多深度学习的方法如deep-clustering, PIT, utterance-PIT, conv-tasnet, dual-rnn, 效果都不错,时频单元到时域单元。 但会发现很多论文或者网上有的开源的代码都需要WSJ0