本文主要是介绍Safe and Efficient Implementation of a Security System on ARM using Intra-level Privilege Separation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
版权声明:本文为CSDN博主「ashimida@」翻译的文章,转载请附上出处链接和本声明。
本文链接:https://blog.csdn.net/lidan113lidan/article/details/119395558更多内容可关注微信公众号

内容摘要:
此文中作者介绍了ARM64中一种同特权级下(EL1/2/3)下系统自隔离的方法——Hilps, 此方法和之前学术界的SKEE[5]效果类似,但实现方法不同.
Hilps是针对AARCH64平台的,可以实现同特权级(EL1/2/3)系统自保护的安全特性, 其将同特权级(如kernel在EL1)分为Inner/Outer mode两个模式, 其中:
- Outer mode是正常系统(内核)运行的环境
- Inner mode则相对具有更高的特权, Inner mode会保护系统中所有的页表, 使得outer mode这个内核富环境无法修改自身的页表; 此外基于这种隔离在Inner mode中还可以完成类似VMI虚拟机内省的各种监控操作(如syscall/pagefault等)
Hilps和基于Hypervisor/TEE的系统保护相比,其优势在于不需要跨特权级的支持;
Hilps和SKEE的优缺点对比:
- Hilps的优点:
- Hilps的实现完全不需要依赖高特权级,在EL1/2/3都可以部署; 但SKEE在AARCH64下需要Hypervisor对0地址做一个映射,并不是完全不需要高特权级支持,故通常只能对EL1的kernel部署;
- Hilps在实现上性能要优于SKEE, 原因应该归结于其对页表的内存分配进行了整合,导致页表写操作的MAC策略会简单很多;
- Hilps的缺点:
- Hilps只能部署在AARCH64平台, 而SKEE可部署在AARCH32/64平台
原文翻译(简):
一、简介
系统监控的已有方案包括[5,17,22,25,37,51,58],这几个都是通过一个安全状态监控软件执行的方案,在发生错误时需要有策略来补救或处理. 对于一个理想的监控,其应该满足两个条件:
1. 监控工具(或者说监控模式)需要能看到被监控系统完整内存
2. 监控工具自身的需要收到保护,其完整性不能受到破坏
上述论文中[22, 25, 37, 51, 58]是基于Hypervisor的保护, 作者认为此类保护的缺陷在于内核需要依赖Hypervisor,但Hypervisor没法保护自身;
论文[5, 17] 解决了同特权级自保护的问题, 自保护要满足两点要求:
- 在同特权级的Inner domain必须与outer domain 隔离开, 即使outer domain被破坏了也不能导致Inner domain被破坏
- 两个domain的上下文切换必须是轻量的,且不可被攻击者篡改的
注:
1) 这里的Inner domain是监控工具的运行模式(类似SKEE中的SKEE mode), outer domain是被监控系统运行的模式(类似SKEE中正常的kernel mode)
2) [5] 中是ARM/ARM64下的SKEE(分别利用了硬件特性TTBCR.N/TTBR1切换),[17]是针对x86-64的保护(利用了硬件特性write-protection, WP);
x86-64的WP特性是专门设计用来同特权级隔离的, 而ARM上没有类似的硬件特性; 作者认为ARM64上SKEE的缺陷是必须依赖Hypervisor的0地址映射, 而Hilps利用的是ARM64的TxSZ特性,故不需要Hypervisor依赖,所以在同特权级保护上更有优势(但实际上SKEE ARM64不是必须要Hypervisor支持, ARM32无需支持;Hilps的TxSZ特性在ARM32不支持,此特性只用于ARM64).
Hilps的思路是利用TxSZ修改后Inner/Outer两个Domian地址空间范围不同(Inner > Outer, Inner是安全域, Outer是非安全域),导致Outer域无法访问Inner域的代码,从而保证Inner 域的安全, 此特性无需Hypervisor支持,任何同特权级下均可部署;
Hilps在Inner域中也再度做了隔离,保证其可以有两个独立的运行环境 此隔离不是通过切换页表实现的(这样不安全),而是通过SFI(software-based fault isolation)软件方法实现的,确保Inner域不会访问到outer域的地址范围(除去预留的访问接口);
Hilps在裸系统测试性能损失为1%, 缺点是不能部署到ARM32系统;
二、安全模型和相关工作
2.1 安全模型:
2.1.1 系统软件和安全威胁:
作者的观点是ARM64加入了HYP和TEE的支持的同时也增大了系统的攻击面, 主要原因就是引入了新的代码(关于代码和漏洞出现的关系可参考[11, 35, 36]);
而Secure OS也是存在安全问题的[39,40,45,50], 其中45是华为TEE OS的一个非常简单的任意地址写漏洞,如下图(get_sys_time为TEEOS中函数):

2.1.2 攻击者能力设定:
假设攻击者可以执行任意基于软件的攻击,但侧信道攻击不包括在内(如cold boot/总线监听/JTAG攻击等);
2.1.3 Hilps的安全保证:
- Hilps 创建了一个安全的Inner domain, 其拥有更小的攻击面;
- Hilps 保证TxSZ隔离和domain切换的完整性
- Hilps 中每个安全工具都运行在独立环境中
2.1.4 TCB(Trusted Computing Base):
Hilps部署环境是拥有可信启动的(其使能前系统可信), 且系统不面临rowhammer等针对内存(硬件的攻击);
2.2 相关工作:
2.2.1 基于微内核的设计(Micro-kernel Design):
微内核的设计[31]可以阻止内核中一部分代码的问题扩散到整个内核中,一些微内核还可以通过形式化验证来验证其实现[20,30],其他系统软件中也有类似的实现[47,53,54,59];
微内核的主要问题是通常要重构软件架构, 实现上有较多的困难(此外还有性能和生态问题);
2.2.2 基于不同特权级的设计(Inter-level design):
如基于Hypervisor[43,44,46,56], Intel SMM[9,10,26,62], Intel TXT DRTM[34]或ARM TrustZone的设计. 其优点是对系统不用大改,但和Intra-level比较有两方面劣势(作者的观点):
1) 最高安全等级(如 Trustzone/Hyp自身代码)的代码无法保护自身;
2) 性能较Intra-level较差;
2.2.3 基于同特权级的设计(Intra-level design):
已有的软件实现如SFI(Software Fault Isolation),其主要缺点是性能极差,借助硬件的实现相对较好,如:
- 借助Intel x86 WP实现的Nested Kernel[17]和HypserSafe[57];
- ARM/ARM64的SKEE
2.2.4 总结
作者将已有的安全实现总结为一张表,如下:
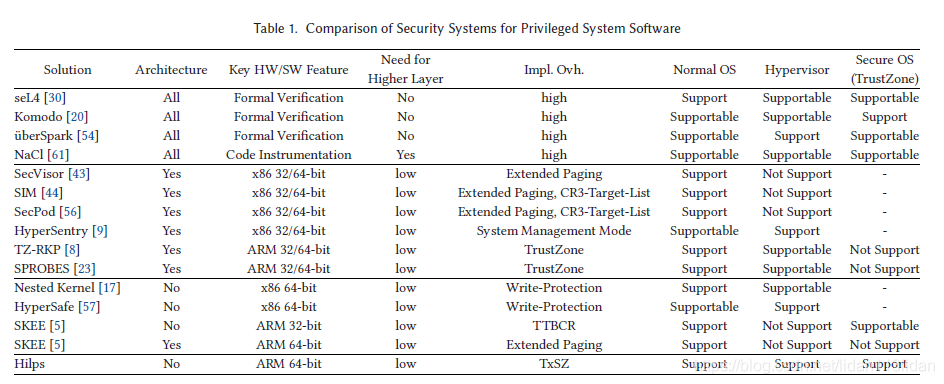
而Hilps的优势在于:
- 完全不依赖于更高一级别的特权级
- 其依赖的TxSZ在ARM64每个特权级都可用
三、背景知识
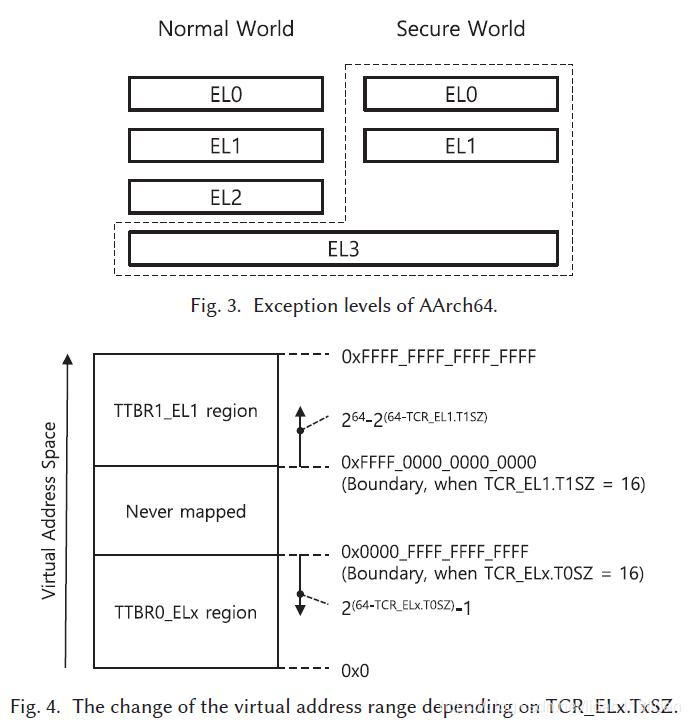
ARM64有EL0~El3 4个特权级,而对于Hilps来说主要的是两类关键寄存器:
1) TTBRs(Translation Table Base Registers):
ARM64中一共4个TTBR寄存器:
- TTBR0_EL1/TTBR1_EL1: 在EL1(通常内核态)可访问的寄存器,TTBR0_EL1负责用户态地址空间的转译,TTBR1_EL1负责内核态地址空间的转译;
- TTBR0_EL2: 在EL2可访问的寄存器,负责EL2的地址空间转译;
- TTBR0_EL3: 在EL3可访问的寄存器,负责EL3的地址空间转译;
这里需要注意的是TTBR0_ELx的地址空间都是0x0000_0000_0000_0000 开头的范围; 而TTBR1_EL1则是结束到 0xFFFF_FFFF_FFFF_FFFF,具体范围与TxSZ的值有关,如图:
还需要注意的是,正常系统进程切换时需要刷TLB, 因为TLB通常都是VIVT的, 如果不刷新则VT会导致缓存歧义(不同进程同一个VA映射到不同PA),而此刷新会导致TLB缓存命中率的降低, ARM则采取了ASID+nG的方式来缓解,具体原理是:
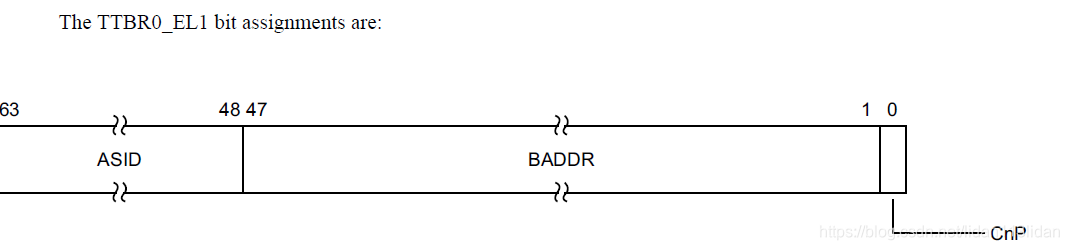
- ASID是TTBR0/TTBR1上高字节的多个bit位,如下图(EL2/EL3不支持ASID), TCR_EL1.A1决定了EL0/EL1地址转译时使用TTBR0_EL1还是TTBR1_EL1上预留的ASID bit位(二选一)
- nG是页表中的bit位, 如果nG为0则代表此页表项全局有效,否则此页表非全局有效
- 对于全局有效的页表,在TLB match时,只匹配VA,VA相同就代表match, 那么如果地址映射改变的话, 如上下文切换或页表修改,此VA对应的TLB必须要刷新,否则就会使用之前的错误映射;
- 对于非全局有效的页表,在TLB match时,需要VA+ASID 同时匹配:
* ASID实际上就是TTBRx_EL1上的一个数,操作系统在进程切换时决定哪个ASID分配给哪个进程
* 由于是VA+ASID同时匹配的, 故在 TLB cache中一个VA就可能对应多个TLB入口(ASID不同)
* 此时上下文切换无需刷新nG的页, 因为上下文切换导致ASID切换了, 之前的TLB不会match(而非nG的页通常是不变的页,故也不需要刷TLB)
* 但页表修改同样还是要刷新TLB,因为ASID还是同一个
四、设计
这里主要介绍的是Hilps中两个核心功能: 1) intra-level 的地址隔离; 2) Inner domain中的安全工具如何通过沙箱隔离;
4.1 Hilps概述:
1) Hilps将系统分为两个Domain, 安全工具运行在Inner domain, 正常系统运行在Outer domain:
Inner/Outer的隔离,是通过可访问地址范围(看到的内存布局)不同来区分的, 页表不变只修改TxSZ,可以让Inner可访问的地址范围变为Outer的两倍(或更多);
2) 随着Hilps中安全工具的增多, 同样会面临代码量导致的安全漏洞增加的风险,Hilps还在Inner Domain引入了sandbox隔离:
其sandbox隔离是基于软件插装实现的(SFI), Inner domain的所有安全工具都可以访问Outer domain,但不能访问Inner domain中其他安全工具;
Hilps的示意图如下:
需要注意的是, Hilps在EL1/EL2/EL3均可实现,但在EL1中和EL2/EL3中Hilps对内存的布局是不同的,原因在于:
- 对于EL2/EL3来说,页表是由TTBR0_ELx来控制的:
由前面图4可知随着T0SZ的减小,TTBR0的地址空间是向高地址增长的,此时L1页表的第一个页表项(pgd[0])总是代表VA 0x0000_0000_0000_0000的映射;
也就意味着对于TTBR0的转译来说, Outer domain永远在扩展后的低地址部分,扩大或缩小T0SZ不影响页表解析,故并不影响其VA=>PA映射关系;
- 而对于EL1来说,页表是由TTBR1_EL1来控制的:
由图4可知随着T1SZ的减小, TTBR1的地址空间是向低地址增长的, 此时L1页表的第一个页表项(pgd[0])代表的VA是变化的;
也就意味着对于TTBR1的转译来说, Outer domain永远在扩展后的高地址部分, 扩大或缩小T1SZ影响了页表解析,故影响其VA=>PA的映射关系;
(如扩大之前T1SZ=27, pgd[0]对应VA 0xFFFF_FFE0_0000_0000; 而扩大之后T1SZ=26,此时pgd[0]对应VA 0xFFFF_FFC0_0000_0000, 导致Outer domain的整个VA都线性的偏移了)
这也是为什么在4.2中要分别针对TTBR0/TTBR1设计Inner/Outer domain的映射方案;
4.2 Intra-level的隔离
首先Inner和Outer domain对于Outer domain的访问权限是一样的(TTBR0_ELx/TTBR1_EL1是不变的),区别只是访问的地址空间范围扩大了.
4.2.1 基于TTBR0的Intra-level隔离:
基于TTBR0_ELx的隔离主要是给Hypervisor(EL2)和Monitor(EL3)自隔离用的,以下图为例,当处于Outer domian 时:
- 最低的128G在Inner/Outer模式下都是给Outer domain的数据/代码用的,其地址范围为[0x0000_0000_0000_0000, 0x0000_001F_FFFF_FFFF]
- [128,255]G在Outer模式下不可访问,在Inner模式下是给Inner Domain的数据/代码用的,地址范围为[0x0000_0020_0000_0000, 0x0000_003F_FFFF_FFFF]
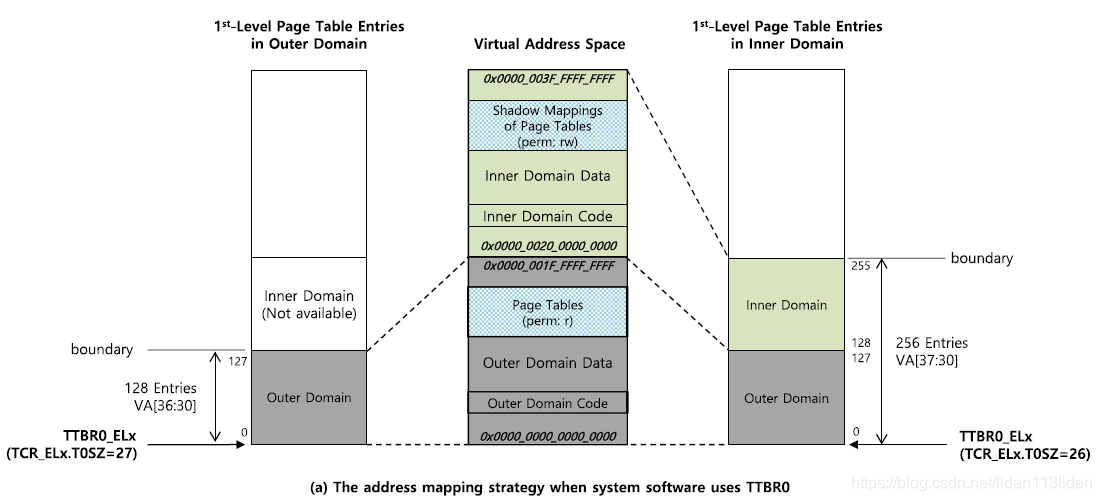
其本质是通过调整T0SZ,将L1的页表映射范围扩大了1倍;
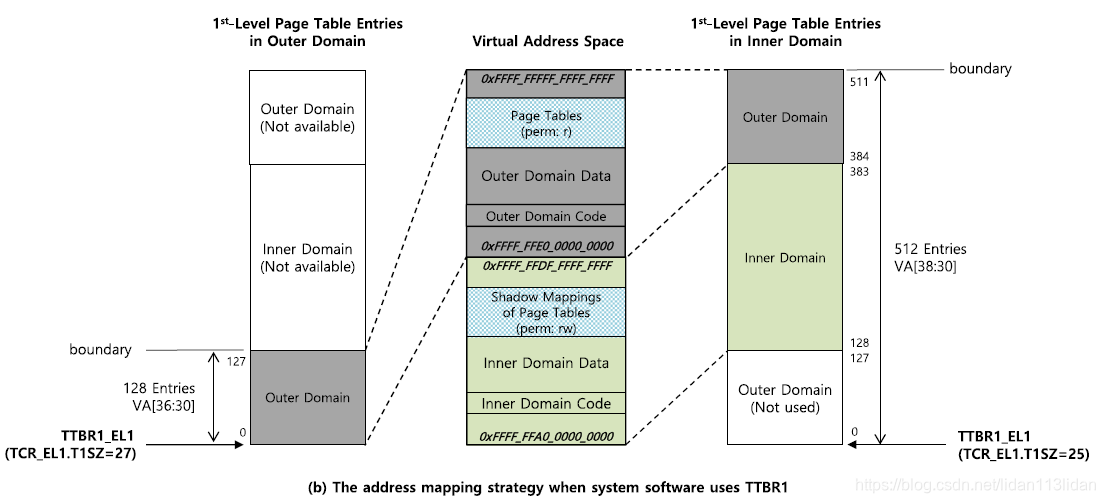
4.2.2 基于TTBR1的Intra-level隔离:
正常EL1的内核不能使用4.2.1中的映射方式,因为前面提到的当T1SZ减少时, pgd[0]代表的VA发生了变化,所以Hilps的处理方法是:
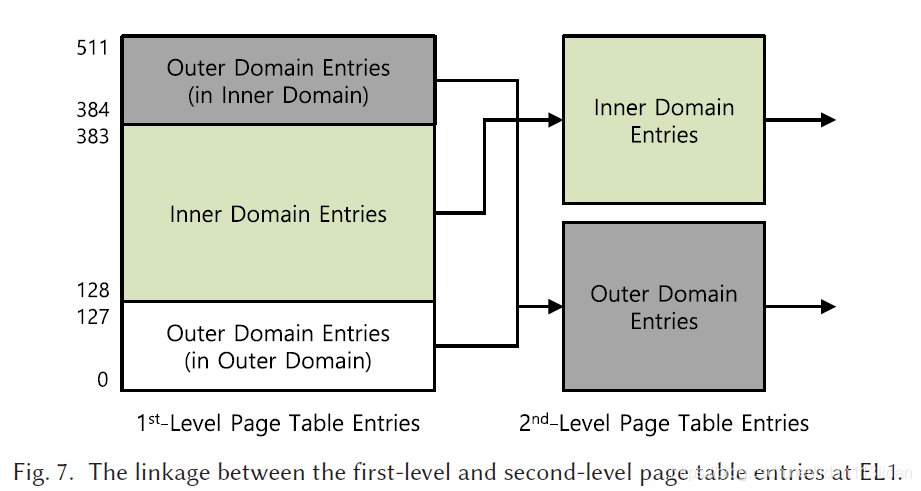
- 在Inner 模式时整个地址空间扩大2倍(=>511), 此时页表中Outer domain原有页表映射还是不变的,但其代表的VA发生了变化
- Hilps中将Outer domain的页表(0-127G的页表)原样的复制到了最高地址处([384,511]G),确保Outer domain的整个地址映射在Inner模式下也是正确的(否则因为VA的改变, Inner模式下访问Outer时需要做一个地址换算)
- Hilps同时需要在Inner模式下维护Outer domain的两份页表([384,511],[0,127]), 针对任何一个的修改都要同步到另一个, 由于需要同步的只是L1页表(L2指向相同的二级小页) 故此操作在运行时损失几乎可忽略), 见图7.
- Inner domain的代码和数据都位于[128,383](比TTBR0时的空间大了一倍), 同样只在Inner 模式可以访问
- 此修改对于Outer 模式同样无感知
- Inner 模式之所以要将地址空间扩大到2倍,是因为如果只扩大1倍的话, 两个Outer Domain之间就没有位置存放Inner Domain自身代码了(在Inner模式也不能去修改Not used那段Outer domain的映射,这会导致性能下降,非Hilps的初衷);
4.2.3 Intra-level隔离的安全增强
Intra隔离的关键在于页表以及系统控制寄存器在Outer domain不能被修改:
- 页表: 由于修改TxSZ只是扩大了地址范围,原有的页表属性是不会改变的, 而在Outer domain的页表要求是RO的, 故Hilps需要在Inner domain为所有页表做一个影子映射(和原有页表PA相同,但VA的访问属性为RW), 页表修改时实际修改的是影子映射中的页表. Hilps确保页表满足两个限制:
- inner domain的任何部分都不允许映射到outer domain
- outer domain的代码必须被配置为只读的
其他限制类似之前的SKEE等工作[5,8,17,56], 其他XN,PXN设置则略去不表
- 系统控制寄存器:
和之前的工作类似, Hilps也需要通过源码消除的方式消除系统Outer domain中所有控制寄存器操作指令,如SCTLR, TCR的操作指令, 同样和之前的研究类似.
4.2.4 DMA的限制
和其他之前的工作类似,DMA attack是此类防御方式中必解的问题,攻击者可以通过直接发起DMA操作来绕过此类CPU的保护机制[13, 38];
对应的在x86上的防御方案则是利用IOMMU来限制DMA访问范围, IOMMU的页表则同样需要受到Hilps的保护[4,33]; 而在ARM上则通过类似的System MMU(SMMU)来防御[6];
对于没有IOMMU/SMMU的系统,则同样需要将所有DMA操作相关内存映射到Inner domain,并在访问之前添加软件检查;
4.3 Domain切换机制
Hilps在Inner和Outer切换时提供了一对entry/exit gate函数,见图8, 这两个gate必须是整个OS中可以切换Inner/Outer domain的唯一方法. 这两个gate函数在Hilps中称为IDC(Inner Domain Call), entry/exit gate函数的操作是栈顺序相反的,以entry gate为例,其流程为:
- 关中断
- expand 整个VA的地址空间(看到的地址空间由Outer domain 变为 Inner domain)
- switch stack, 切换到Inner mode的stack
- jump Inner handler, 跳转到Inner的handler函数

4.3.1 VA范围的调整
在gate中有一步操作就是通过TxSZ来调整可访问的VA地址范围, 由于Outer domain中不存在其他可修改TxSZ的指令(TCR指令),所以不存在其他威胁点;
唯一的威胁点就是控制流劫持(CFH)后,直接跳转到entry gate中修改tcr(如直接跳转到图8的18行), 如果攻击者之前控制了x5寄存器的值,就可以修改tcr绕过Hilps, 而作者的解决方法就是软防ROP,在tcr写指令后面在做一个读检查,其亮点在于读检查失败后又去redo(line 14)重新设置了tcr, 这样就免去了攻击者对gate的攻击导致系统crash了(但也未必是好事,需要看具体场景);
4.3.2 关中断
正常Hilps的整个代码(Inner mode)执行时都是关中断执行的,这样会避免中断切换到outer domain代码的各种麻烦,故 entry gate入口的第一件事情就是关中断.
但攻击者如果CFH绕过了关中断,则切换tcr之后可能因为中断的触发将控制流劫持到Outer domain的代码, 故Hilps的处理方式和SKEE类似,都是在中断入口的处直接再添加一个检查, 区别在于SKEE检查的是TTBCR/TTBR0寄存器, 而Hilps检查的是TCR寄存器;
与此同时为了防止中断向量表被篡改, VBAR(中断向量表寄存器)也要受到保护, 也就是Outer domain中不应该存在修改VBAR的指令.
总结起来就是: 1) gate中要关中断, 2) 中断中要check TCR是否正确, 3) VBAR也要保护;
4.3.3 利用ASID提速
在退出Inner 模式时,由于Inner domain的页表转译信息都存在TLB中,如果不刷新TLB则此时在Outer domain中有可能可以直接访问到Inner domain的内容(不确定,切换TxSZ TLB如何转译需尝试一下[TODO]), 正常情况下这里需要一个TLBI*指令来flush.
但由于ARM64 EL1支持ASID, 实际上可以给Inner domain一个唯一的ASID(ASID在TTBR中,只有在Inner 模式才可改,但这里需要与kernel逻辑上同步),并将Inner domain的页标记为nG的,这样在exit gate时切换掉Inner domain 的ASID即可避免TLB刷新问题以提高性能;
但还有个问题是,正常ASID在TTBR中,修改ASID相当于引入了写TTBR的指令:
- 此指令不能放在Inner domain, 否则实际上是在Inner domain的TLB已经缓存给切换前的ASID后才切换的ASID, 这个被缓存的TLB表项一直在TLB中;
- 此指令也不能放在 entry/exit gate中,因为这样可以被攻击者CFH利用(实际上应该有解决方法)
作者的解法是利用ARM硬件特性和内核特点,在Inner domain中使用TTBR1_EL1中存储的ASID,在Outer domain中使用TTBR0_EL1中存储的ASID(因为内核正常就是用的TTBR0_EL1中的ASID,这里保持一致), 而切换操作则是通过修改TCR.A1来实现的,此寄存器在4.3.1 VA调整的过程中已经经过保护了,这里只是额外改了一个A1字段,见源码26行;
最终解法是在EL1的实现中并不需要再exit gate时刷TLB, 而只是切换下ASID即可; 但此方法对于EL2/EL3的实现不可用,因为这两个特权级不支持ASID, 而在这两个特权级的处理方法则只能是flush TLB;
4.3.4 Inner domain stack
Inner domain 和Outer domain的栈要分离,即在entry/exit gate时要做栈切换操作, 对于Inner mode来说其stack是 per cpu的且大小固定, entry gate中:
- 先通过mpidr_el1获取当前core编号(line 29)
- 再根据所有core的栈基地址,加上当前core的栈偏移(根据core编号算出来的), 将sp切换到inner domain中的栈内存即可;
4.3.5 向其他异常级别(ELx)的移植
EL2/3在entry/exit gate上和EL1的区别就在于需要将ASID切换指令替换为缓存刷新指令(TLBI*),其他都一样;
4.4 监控能力和沙箱机制
Hilps隔离出的系统实际上就是类似一个Hypervisor,其可以类似Hyp中使用虚拟机内省(VMI)监控VM的方式来监控kernel,其 kernel中的安全事件都可以通过hook的形式在Hilps中监控(如syscall, page fault处理等).其还通过SFI(软件隔离)将各个Inner domain中的安全工具互相隔离开了, Inner domain中的安全工具需要满足:
- P1: 所有工具都允许访问 Outer domain
- P2: 所有工具都不允许访问其地址空间范围外的Inner domain
- P3: 所有工具都不允许执行其代码范围外的任何代码
而SFI的原理可以简单描述为:
- 将代码中所有的间接转移和内存访问指令都替换成对应的伪指令序列
- 这个伪指令序列用来确保间接转移和内存访问不超过SFI的限制范围
SFI本身是AARCH32的工具,作者自己在AARCH64上做了类似实现:4.4.1/4.4.2则分别讲述了作者是如何划分Inner domain的(SFI的特点是被保护的代码需要划分好地址范围,这样在SFI的伪指令序列中才好检测),以及SFI中具体的伪指令序列的实现;
六、评估
本文中作者评估了基于Inner domain/Hypervisor/TEE几种方法的性能消耗、使用ASID或TLB flush的性能消耗、基于关键syscall和系统整体的benchmark、以及添加syscall监控和sandbox后的性能消耗,这里只记录部分,其余可参考原文;
6.1 gate switch的性能消耗
作者在这里对比了IDC gate和Hypervisor/TEE纯切换时的性能消耗如下图:
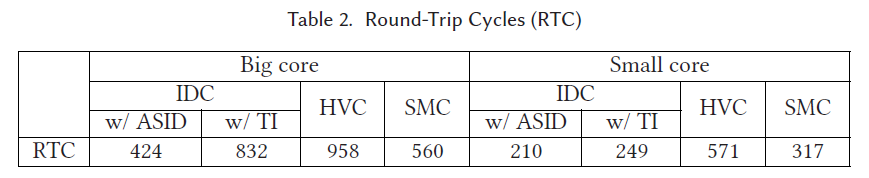
可见IDC的切换性能损失明显是低于HVC和SMC的,但由于执行环境切换在整个过程中占比很小,所以实际上三种方式的实现对最终整体性能影响很小;
6.2 Micro Benchmarks
Micro Benchmarks主要针对一些系统调用的执行时间进行测试,其中有的syscall中涉及gate转换,有的还要具体实现如页表修改等操作,如下图:
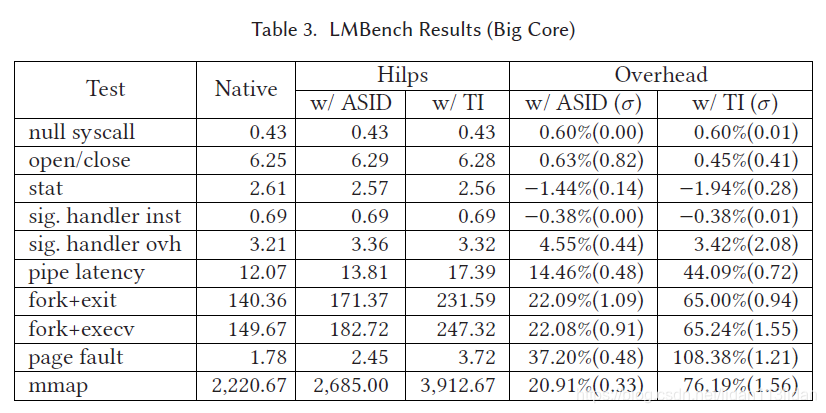
可以看到性能损失较多的是在fork_exec或page_fault这种对页表操作的函数中, 但这个只是syscall的损失,对系统整体性能影响还要参考跑分;
6.3 Marco Benchmarks
这里就是针对系统的benchmark,测试结果如下:

按照作者的话,支持ASID时整体性能损失约0.77%, 不使用ASID时为2.1%,这个性能对比SKEE来说应该是很好了
七、一些讨论和本文的限制
7.1模块加载的支持
模块加载前Hilps需要扫描整个模块中的代码,如果发现敏感指令,作者的处理思路是将其替换并最终跳转到IDC处理, 但对于复杂的case有时候并不是很容易处理,但后续可以通过其他方法改进;
7.2 安全工具的限制
目前Inner domain中安全工具中如果出bug则会直接crash, 后续会利用SFI的方式来handle这些错误;
7.3 Hilps的形式化验证
由于Inner domain的代码较少,后面可以通过形式化验证的方式增强其安全性;
7.4 针对IDC的攻击
攻击者有可能通过IDC gate触发Inner domain中代码的错误, 代码自身错误是不可避免的, 但Hilps中的代码通常都是简单的整型和flags操作,出问题概率较小;
八、参考资料:
[5] 2016. SKEE: A lightweight secure kernel-level execution environment for ARM. In Proceedings of the Network and Distributed System Security Symposium
[17] 2015. Nested kernel: An operating system architecture for intra-kernel privilege separation
[22] 2003. A virtual machine introspection-based architecture for intrusion detection
[25] 2011. Ensuring operating system kernel integrity with OSck
[37] 2007. Automated detection of persistent kernel control-flow attacks
[51] 2014. Defeating buffer overflow attacks via virtualization
[58] 2009. Countering kernel rootkits with lightweight hook protection
[11] 1984. Software errors and complexity: An empirical investigation(948)
[35] 2003. Relationships between selected software measures and latent bugdensity: Guidelines for improving quality
[36] 2002. The distribution of faults in a large industrial software system
[39] 2014. QSEE trustzone kernel integer overflow. In Black Hat USA
[40] 2013. Next generation mobile rootkits. In Black Hack Europe
[45] 2015. Attacking your trusted core: Exploiting trustzone on android. In Black Hat USA
[50] 2014. Here be dragons
[31] 1995. On micro-kernel construction
[20] 2017. Komodo: Using verification to disentangle secure-enclave hardware from software
[30] 2009. seL4: Formal verification of an OS kernel
[47] 2010. NOVA: A microhypervisor-based secure virtualization architecture
[53] 2013. Design, implementation and verification of an extensible and modular hypervisor framework
[54] 2016. überSpark: Enforcing verifiable object abstractions for automated compositional security analysis of a hypervisor
[59] 2013. Taming hosted hypervisors with (Mostly) deprivileged execution
[49] 2003. Improving the reliability of commodity operating systems
[13] 2005. FireWire: All your memory are belong to us. Proceedings of CanSecWest
[38] 2007. hacking in physically addressable memory
[4] 2006. Intel virtualization technology for directed I/O
[33] 2016. True IOMMU protection from DMA attacks: When copy is faster than zero copy
这篇关于Safe and Efficient Implementation of a Security System on ARM using Intra-level Privilege Separation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






