本文主要是介绍【论文阅读 VLDB22】On-Demand State Separation for Cloud Data Warehousing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
On-Demand State Separation for Cloud Data Warehousing
问题背景
首先是问题背景,目前除了大规模PB级别的AP会使用云数据库,越来越多的百G大小的中小规模的负载也开始进行上云分析和处理,而这些ap任务不需要消耗整个集群的资源,往往只需要单个节点运行。
那么这个过程中,如何选择合适的工作机就是一个问题,考虑到负载变化以及降低成本或者需要提高算力等等场景,往往就会涉及到在节点之间进行查询迁移。
此外,传统的云数据仓库架构在性能、灵活性和成本之间存在平衡的挑战,对于无共享架构提供高性能但扩展性有限,而存储分离架构虽然可以独立扩展计算和存储,但对单个查询的弹性和容错能力有限。而完全状态分离会导致较低的性能。
本文提出按需状态分离兼顾了性能和灵活性,在本地查询中充分利用存储分离架构的全部性能,同时在必要时仍支持查询迁移和弹性,且开销最小。
整体思路
整体思路:
- 定义整体目标、查询状态和进度
- 实验分析workload的状态大小、进度分析
- 状态选择
- 状态提取
- 查询计划修改和传输
- 延续查询
整个按需状态分离的思路是首先定义了状态分离的目标,给出了查询状态和进度的定义,然后实验分析了在TPC-DS负载下的状态大小和进度的特点
然后讨论选择哪些状态进行分离,怎么样把需要分离的状态提取出来以及怎么样对查询计划进行修改以方便后续延续查询,以及最后迁移到的服务器怎么样延续之前的查询
定义与目标
State Separation:将查询的工作状态和进度与执行它的机器解耦的过程
目标:在最小化进度损失和查询状态的同时,实现状态分离,而不影响本地执行的性能。
Query State:物化的tuples,还在被其他管道使用的物化tuples。(所有在连接到尚未完成的管道的已完成管道的阻塞操作符中物化的元组。)
Query Progress:(# of finished pipelines)/(# of total pipelines)
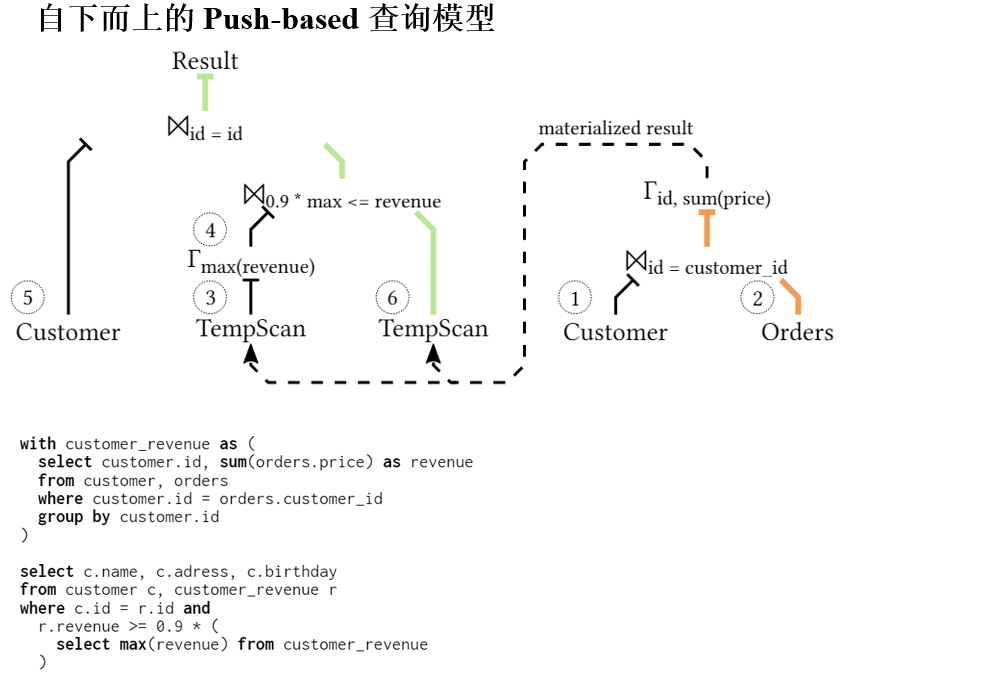
在Umbra上实现的方法,Umbra使用基于管道的执行模型,将查询分割成管道,然后将其转换为代码并编译执行。Umbra还支持将查询计划导出和导入到JSON格式,我们使用它在实例之间共享查询。
系统必须能够提供运行查询的进度信息,以管道为粒度跟踪查询进度。
中间结果通常在阻塞操作符中物化,即在管道的末端。,向量化系统如MonetDB在每个操作符中都会物化结果。
结果例如在管道1之后的连接哈希表中物化,在管道3之后的聚合中物化。
状态大小分析
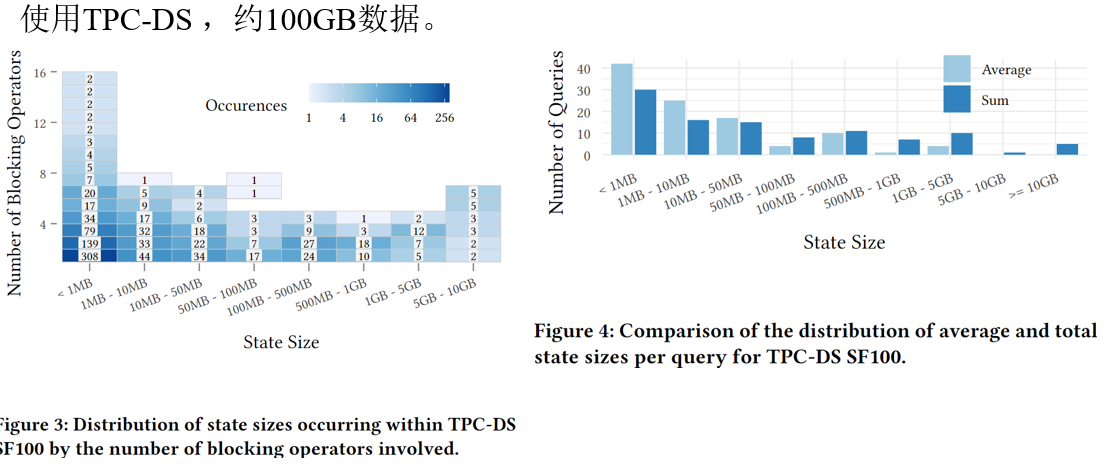
左图是分析了所有查询中出现的状态大小的分布,测量了每个管道后存储的元组的大小和物化这些元组的阻塞操作符的数量
绝大多数状态包括少量的操作符,数据量不到十兆字节。但有几个状态的大小超过了五个吉字节
总体而言,30%的状态包含一个数据量不到1MB的单一阻塞操作符,86%的状态大小不超过100MB。尽管中位数状态大小只有133KB,但平均状态大小为265MB
图4显示了每个查询的平均状态大小和总状态大小的分布。所有状态的平均大小为2.6GB,因此大约大了10倍。因为它可能包含同一个管道结果多次。管道2的结果是从管道3开始的所有状态的一部分完全排除这些重复项也是不准确的,因为它们必须多次传输给工作节点。例如,管道2的结果是管道3和6的工作节点所需的
状态进度分析
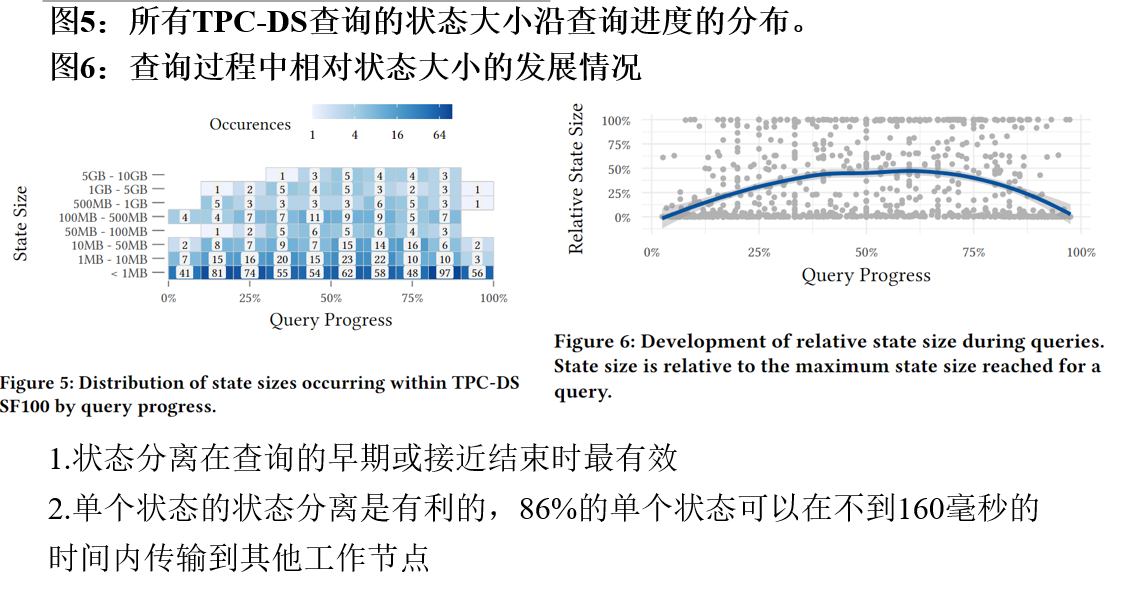
根据先前对查询进度的定义,实验分析了查询的状态大小沿查询进度的分布。在查询开始和结束的时候大的状态较少,但是变化不明显
于是分析了相对状态大小,状态大小增长到大约40%的管道完成后趋于平稳,直到大约70%。从那时起,状态持续缩小
例如在图2中,前两个状态只包括单个管道的结果。在管道5之后,状态达到最大,包含了三个物化的管道结果(2,4和5)。10Gbit/s的网络连接
按需状态分离
**查询迁移:**将查询处理从执行服务器A移动到服务器B而不丢失在A上为查询取得的进度的过程
查询迁移是状态分离的一种应用场景,其他如延迟执行、快照等
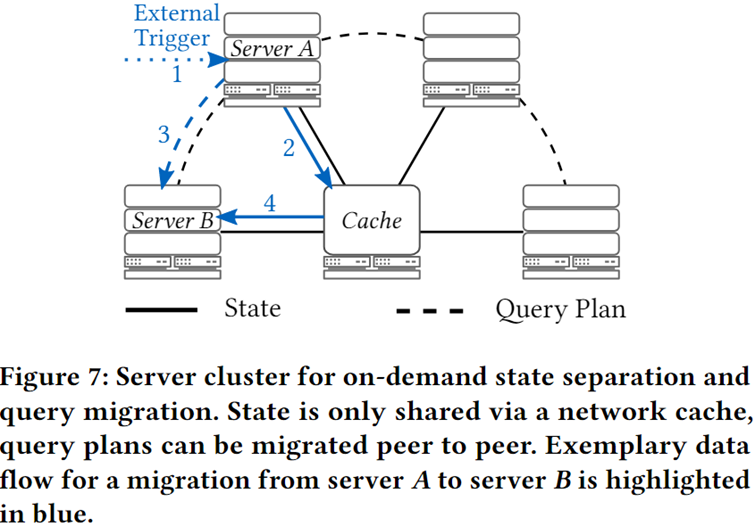
按需状态分离过程的大致步骤
1.系统需要检测到迁移的需求,并向服务器报告。迁移可以由多个事件触发,例如云提供商指出即将回收临时计算资源,或者出现了更快或更便宜的现货实例。
2.然后,在服务器A上,需要根据定义2识别查询的当前状态,并从如哈希表等结构中提取出来。服务器A随后将提取出的状态传输到外部缓存。
3.服务器A上,查询计划随后被修改以便从当前状态继续执行,并传输到接收服务器B。
4.服务器B编译接收到的查询计划并继续执行。当需要首次扫描状态中的部分结果时,它会从缓存中获取并本地保存。
推迟执行:为了优先处理其他查询,可以暂时挂起某个查询的执行。这意味着当前查询的状态被保存下来,查询执行被暂停,从而为更紧急或优先级更高的查询腾出资源。一旦条件允许,可以恢复推迟的查询,继续其执行而无需重新开始。
2.快照:可以定期创建查询的状态快照,以便在必要时能够从特定点恢复查询。这对于长时间运行的查询非常有用,因为它减少了在发生故障时需要重做的工作量。快照还可以用于分析和调试目的,例如,开发者可以检查某个时刻查询的中间状态,以了解其执行过程。
状态选择
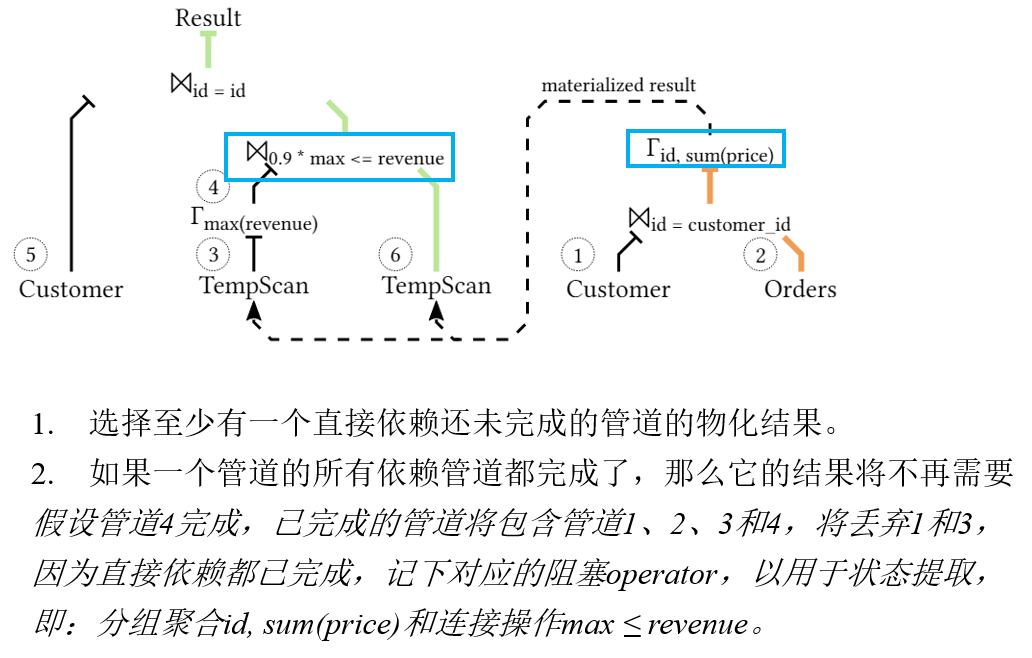
那么需要选择什么样的状态进行分离从而能保证续作呢?
文中是给出了算法的伪代码,其实主要还是用管道之间的依赖进行丁旭,首先是给出了直接以来的定义
如果一个管道A的执行直接需要另一个管道B的结果,那么管道A直接依赖于管道B。例如,在图2中,管道3依赖于管道2的结果,但并不依赖于管道1。
在这个过程中,⨝ 0.9 * max <= revenue这部分的连接操作,实际上是在做以下两个步骤:
- 计算customer_revenue中的最大收入值(即子查询select max(revenue) from customer_revenue)。
- 将得到的最大收入值乘以0.9,得到新的阈值。
- 然后,比较每个客户在customer_revenue中的收入是否达到或超过这个阈值。
因此,这个连接操作是customer_revenue这个临时视图自身的内连接,用来过滤出收入高于某个阈值的客户记录。在这个例子中,并不是两个不同表之间的连接,而是基于从同一个临时视图中提取的数据的比较。这是一个常见的OLAP查询模式,用于识别出收入最高的一群客户,例如用于市场营销活动或者客户忠诚度分析。
状态提取
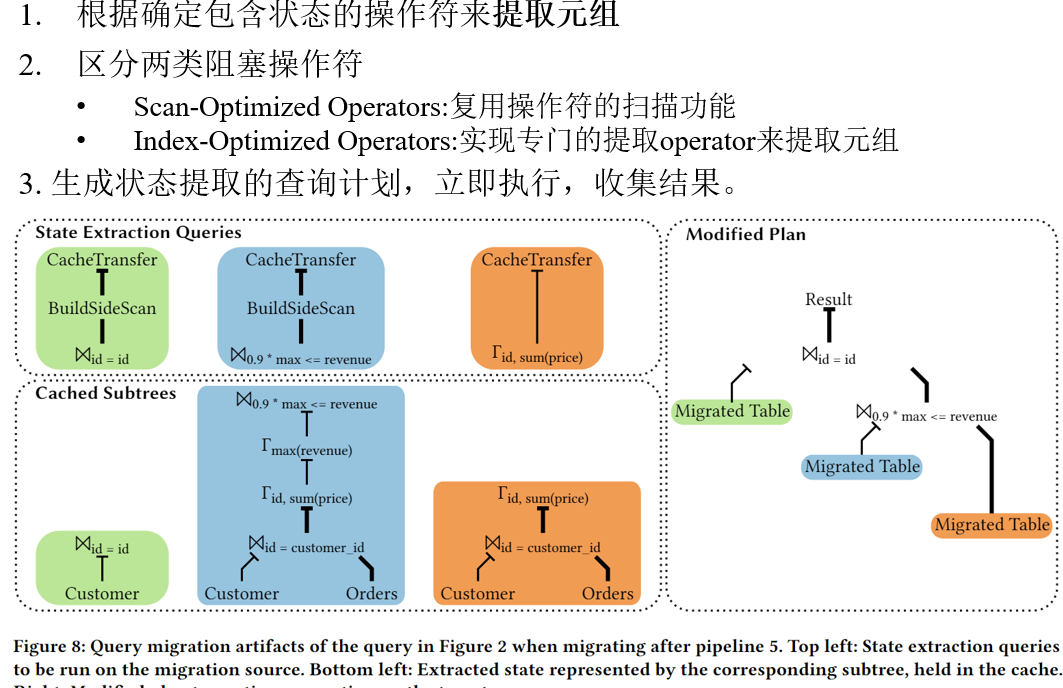
根据之前选择的包含状态的操作符来提取元组,这里他是分了两类操作符,一类是扫描优化操作符,只作为阻塞操作符出现在查询中的操作符,比如聚合、排序、集合操作,这些操作符提供了扫描所有元组的功能
索引优化操作符:具有更复杂访问模式的操作符,如连接操作,例如,哈希连接优化了基于连接谓词的点访问,通常不提供全扫描的功能。这里是实现专门的
最后是把复用数据库内部的现有逻辑和访问路径,以查询的形式实现提取,生成一个提取的查询计划,所有提取查询都被安排为立即执行,并且为了防止在提取完成之前修改状态,与常规查询不同,状态提取查询不向用户报告结果
Build-side(构建侧)通常是指在某些数据库连接操作中用于存储连接键值的一侧,例如,在哈希连接中,构建侧是预先填充的哈希表,用于快速查找。Build-side scan(构建侧扫描)则是指对这个构建侧的哈希表进行的扫描操作,以便从中提取数据。
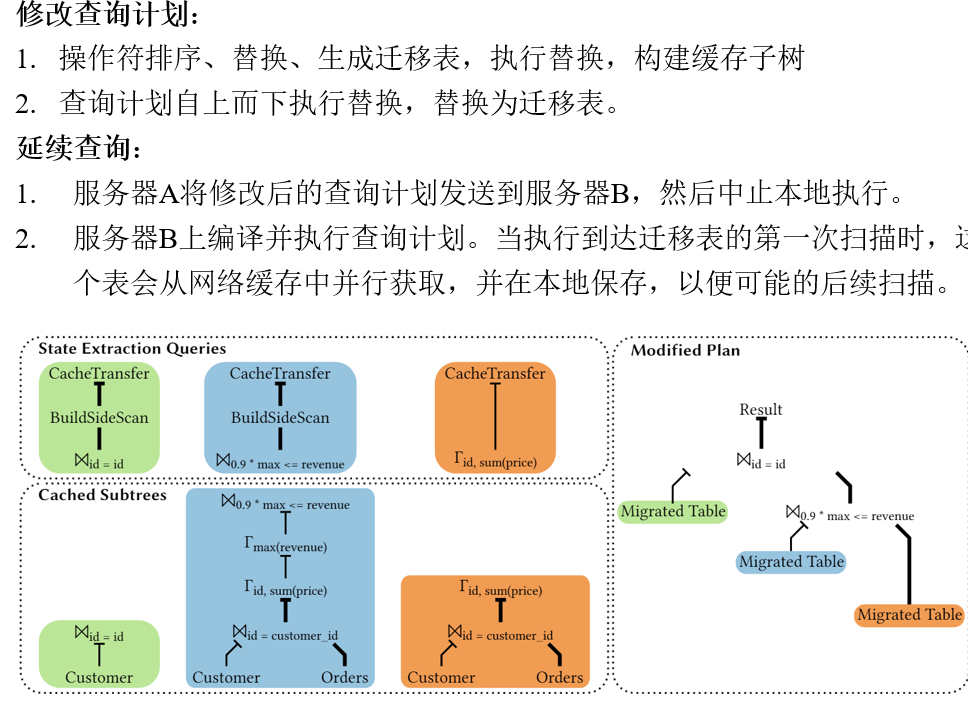
修改查询计划且延续查询
实验
实验主要包括两部分
- 按需状态分离对查询处理的开销和来源:网络开销和执行开销
- 该方法的可行性
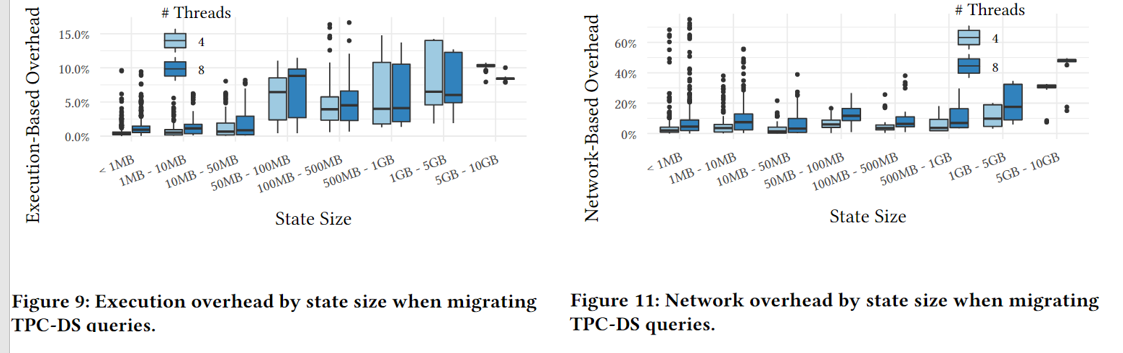
执行:对于较小状态大小的异常值主要来自于执行时间以毫秒计的小型快速查询,对于小于50MB的状态(占所有状态的83%),平均开销不超过1.9%
网络:但对于小于50MB的状态,平均开销不超过查询运行时间的11%。
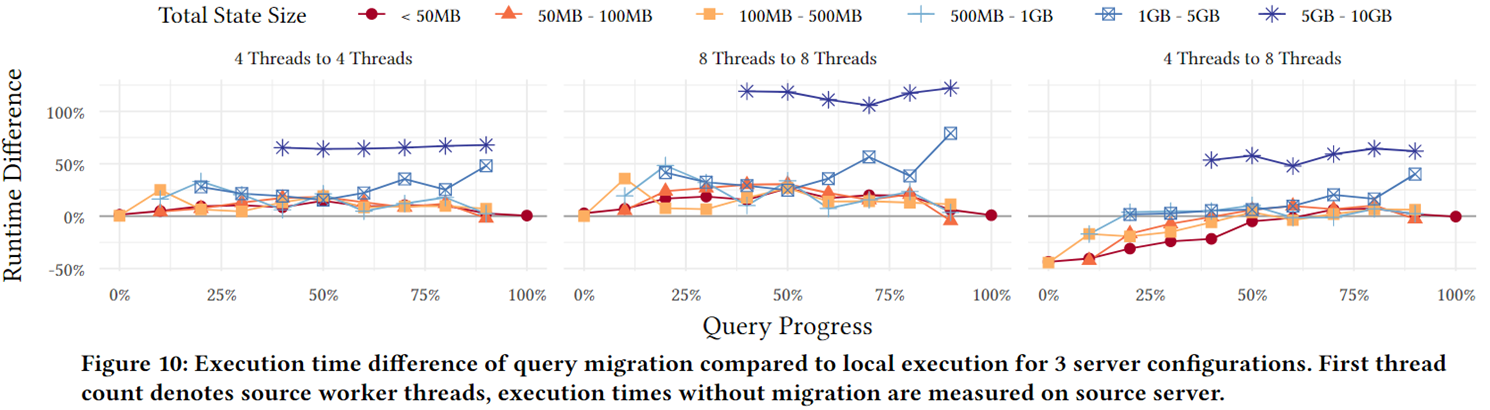
图12 按需迁移基本恒定,对于使用八个线程的情况,全迁移会导致超过100%的开销,而按需分离的开销从未超过10%
下图的延迟是触发迁移到每个查询的状态和计划分别发送到缓存和目标服务器的时间
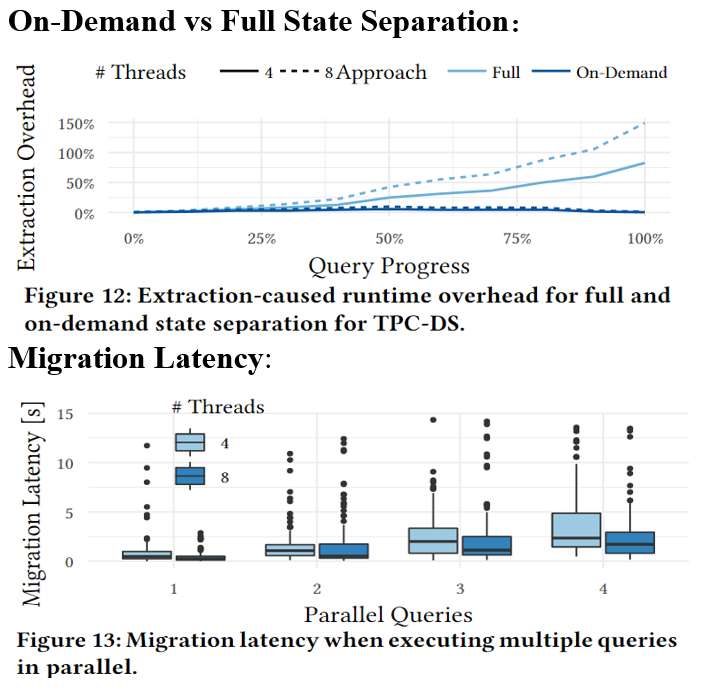
图12 按需迁移基本恒定,对于使用八个线程的情况,全迁移会导致超过100%的开销,而按需分离的开销从未超过10%
下图的延迟是触发迁移到每个查询的状态和计划分别发送到缓存和目标服务器的时间
这篇关于【论文阅读 VLDB22】On-Demand State Separation for Cloud Data Warehousing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









