repeatable专题

OceanBase 的 Oracle 模式竟然可以使用 Repeatable Read?
OceanBase 的 Oracle 模式不是只支持 2 种隔离级别:读已提交(Read Committed)和可串行化(Serializable)。 作者:任仲禹,爱可生数据库工程师,擅长故障分析和性能优化。 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 本文约 1600 字,预计阅读需要 5 分钟。 背景 看到文章标题会有个疑惑,OceanBase
JAVA注解学习-@Repeatable注解
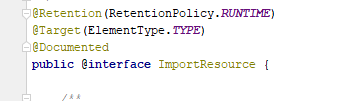
@Repeatable注解是用来标注一个注解在同一个地方可重复使用的一个注解,比如说你定义了一个注解,如果你的注解没有标记@Repeatable这个JDK自带的注解,那么你这个注解在引用的地方就只能使用一次。 例: 这里@ImportResource(value = “”)注解里面没有设置添加@Repeatable属性,所有引入的多次的时候就会报错, 参考链接 java8注解@Repe
关系型数据库的数据隔离级别Read Committed与Repeatable Read
一、背景 数据库隔离级别会影响到我们的查询,本文试图以生产中的示例,给你一个直观的认识。 所谓,理论要结合实践,才能让我们理解得更加透彻。 另外,隔离级别的知识面很大,本文也不可能俱全,下面给出本文要阐述的目标: 二、目标 Read Committed与Repeatable Read的区别实际编程中的使用场景什么是Phamtom什么是Write Skew 三、隔离级别 1、可重复读

MySQL综合应用二:事务机制二:四种隔离级别:【READ UNCOMMITTED】、【READ COMMITTED】、【REPEATABLE READ】、【SERIALIZABLE】;
目录 1.买票的业务场景:适合【READ UNCOMMITTED】的隔离级别 2.银行转账的业务场景:适合使用【READ COMMITTED】这种隔离级别 3.电商订单支付场景:适合使用【REPEATABLE READ】这种隔离级别 4.【SERIALIZABLE】隔离级别 数据库中的事务都是并发执行的,因为事务具有隔离性,会给一些业务带来问题。本篇博客主要介绍【事务并发执行的条件下

论文笔记:R2D2: Repeatable and Reliable Detector and Descriptor
论文链接:https://arxiv.org/pdf/1906.06195.pdf 代码链接:https://github.com/naver/r2d2 主要内容 本文首先指出显著区域未必是易辨识区域,因此用判断极值的方法来判断keypoint(关键点)位置的方法未必准确,这样会影响到所提取描述子的性能。相比于之前只重视特征点的repeatble(可重复性,即特征在连续图像中多次出现)的方法,
[论文解读]R2D2: Reliable and Repeatable Detector and Descriptor
NeurIPS 2019 代码地址 会议视频 abstract 仅仅学习可重复并显著的特征点不够,显著的区域并不一定是有区分性的,因此这样可能损害描述子性能。因此,文中认为描述子应仅在具有高置信度的区域学习。文中方法在Hpatch和 Aachen Day-Night localization benchmark有较好的表现。 上图用棋盘图像显示了这样一个例子:每个角或色块都是可重复的,但
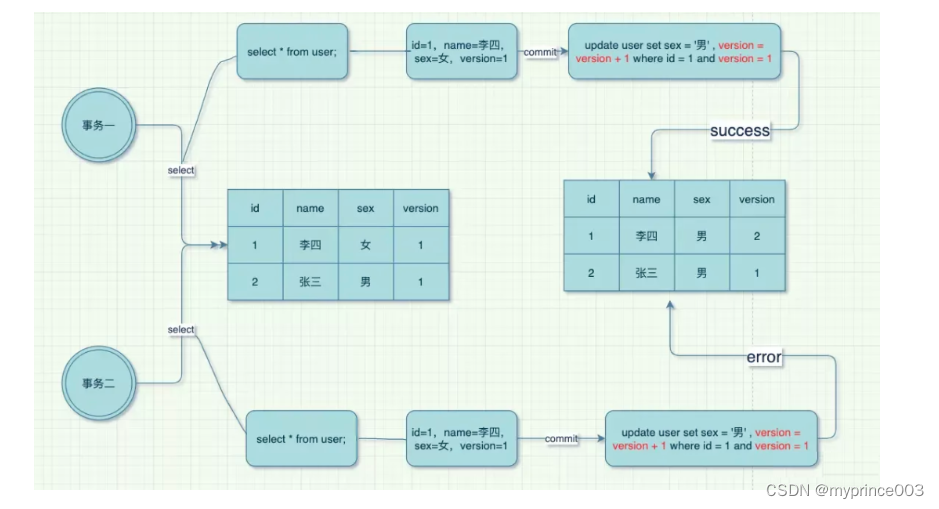
为什么 MySQL 选择 Repeatable Read 作为默认隔离级别
为什么 MySQL 选择 Repeatable Read 作为默认隔离级别? 我们知道,ANSI/ISO SQL-92 标准定义了 4 种隔离级别,从低到高依次为: 读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Reads)、序列化(Serializable)。 在 RU 级别下,可能会出现脏读、幻读、不可重复读等问

深入浅出 java 注解-03-java 元注解 @Retention、@Documented、@Target、@Inherited、@Repeatable
目录 目录元注解@Retention 实例说明 @Documented 实例 @Target 实例说明 @Inherited 实例说明 @Repeatable 实例 代码地址系列导航 元注解 适用于其他注释的注释称为元注释。在 java.lang.annotation 中定义了几个元注释类型。 @Retention 指定标记的注解如何存储: 属性说明RetentionPo