本文主要是介绍关系型数据库的数据隔离级别Read Committed与Repeatable Read,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
数据库隔离级别会影响到我们的查询,本文试图以生产中的示例,给你一个直观的认识。
所谓,理论要结合实践,才能让我们理解得更加透彻。
另外,隔离级别的知识面很大,本文也不可能俱全,下面给出本文要阐述的目标:
二、目标
- Read Committed与Repeatable Read的区别
- 实际编程中的使用场景
- 什么是Phamtom
- 什么是Write Skew
三、隔离级别
1、可重复读
可以重复读的意思是,在同一个事务中,多次读取同一条记录,返回的数据是相同的;不会因为其他的事务修改它而变化。
必须要先理解这个默认隔离级别,才好反过来理解读已提交的级别。
最后,在你实际的应用中,要决定是否降低隔离级别。(以我实际的使用经验看,降低到读已提交级别,不仅符合程序的要求,而且提升了数据库的性能)
我们都知道,隔离级别越低,数据库的读写性能就越高,所谓“鱼与熊掌不可兼得”~~
下面摘引一个示例:
-- 事务A查询主键ID=7的姓名,返回是Aaron
session1> BEGIN;
session1> SELECT firstname FROM names WHERE id = 7;
Aaron-- 事务B查询主键ID=7的姓名,返回是Aaron
-- 随后,把它修改为Bob,最后提交事务
session2> BEGIN;
session2> SELECT firstname FROM names WHERE id = 7;
Aaron
session2> UPDATE names SET firstname = 'Bob' WHERE id = 7;
session2> SELECT firstname FROM names WHERE id = 7;
Bob
session2> COMMIT;-- 事务A二次查询主键ID=7的姓名,返回仍然是Aaron
session1> SELECT firstname FROM names WHERE id = 7;
Aaron
session1> COMMIT;
上述的过程与结论好理解,在实际编程中,你一定要考虑,现实场景会是需要如此吗?
如果更新换成账户余额、库存和积分等变化频繁的场景呢。。。
把问题先留在这里,我们继续另外一个问题:
- 因为 Phamtom 而导致的 Write Skew现象
再举一个示例:
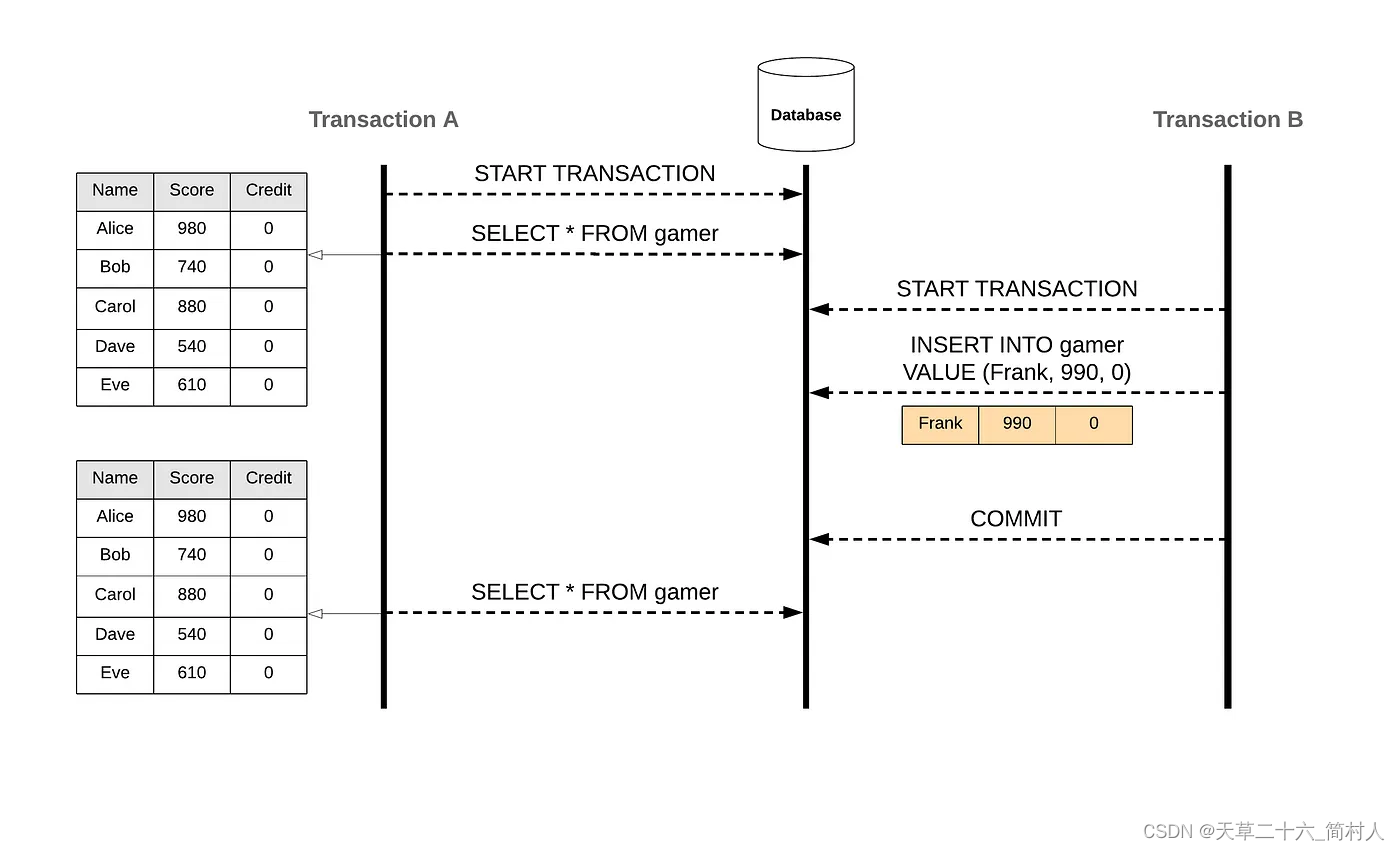
重复演示一遍,什么是可重复读的隔离级别。。
那么怎么会导致幻影Phamtom呢?
所谓幻影是指第一次查询的时候没有它,而更新的时候,却把它更新成功了。
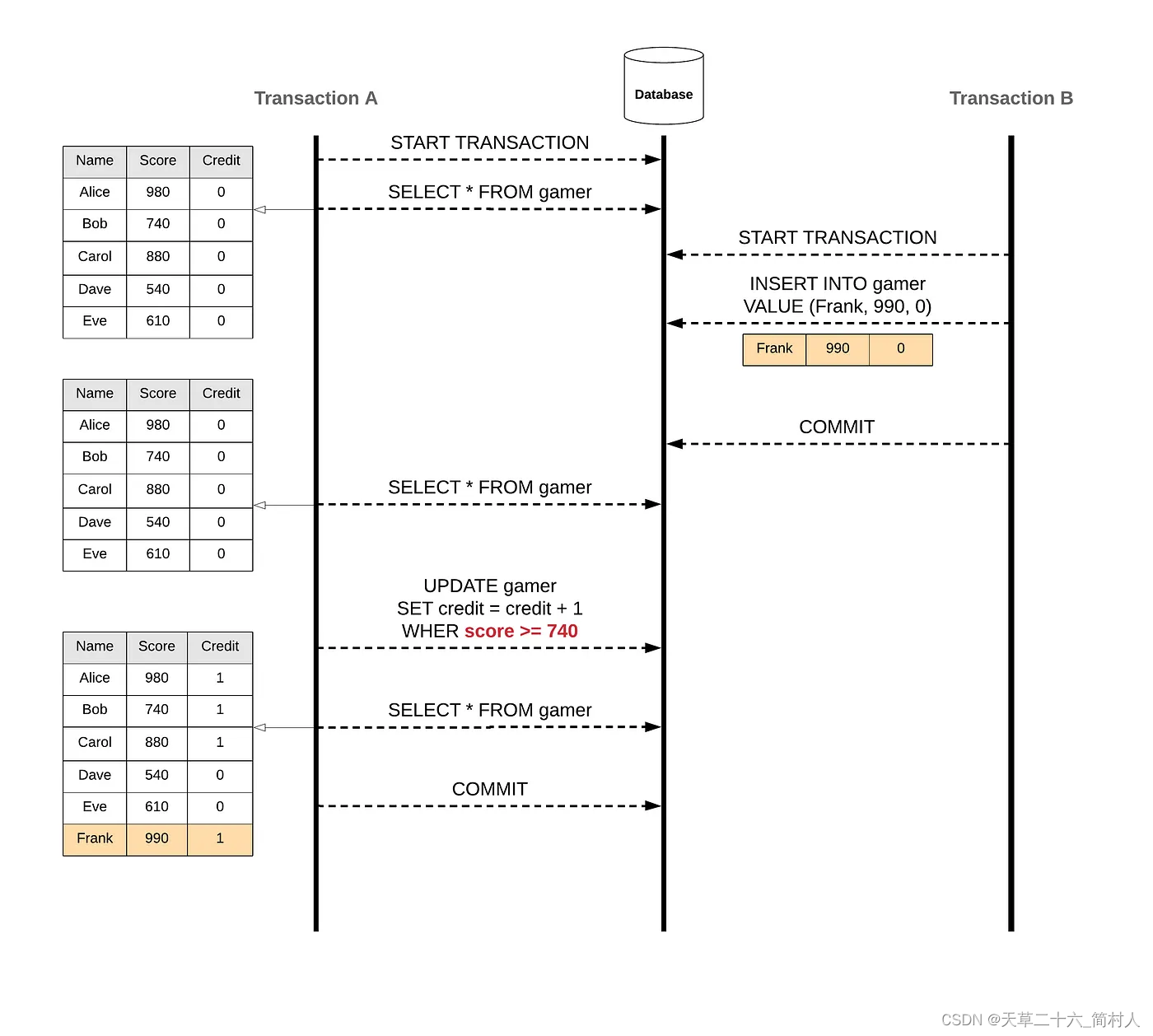
事务A,期望是更新Alice/Bob/Carol这三个人的积分+1
当事务B,新增了一个人Frank,其积分也大于740。
结果,事务A按更新条件(score > 740)执行,导致不在期望中的Frank也被更改了。
这就是Write Skew。
换句话说,可重复读,虽然可以避免查询的可重复,但是它解决不了幻影带来的写倾斜Write Skew。
- 怎么解决幻影现象
批量更新记录,更新条件是上一步查询出来的记录ID集合。
select * from gamer where score >= 740;
# 100
# 101
# 102
# 103
update gamer a set a.credit = credit + 1 where a.id in (100,101,102,103);-- 不要使用区间比较
update gamer a set a.credit = credit + 1 where a.score >= 740;2、读已提交
和可重复读相比,它会读取到其他事务提交的记录。
这里,以第一个示例进行修改举例。
-- 事务A查询主键ID=7的姓名,返回是Aaron
session1> BEGIN;
session1> SELECT firstname FROM names WHERE id = 7;
Aaron-- 事务B查询主键ID=7的姓名,返回是Aaron
-- 随后,把它修改为Bob,最后提交事务
session2> BEGIN;
session2> SELECT firstname FROM names WHERE id = 7;
Aaron
session2> UPDATE names SET firstname = 'Bob' WHERE id = 7;
session2> SELECT firstname FROM names WHERE id = 7;
Bob
session2> COMMIT;-- 事务A二次查询主键ID=7的姓名,返回变成了Bob
session1> SELECT firstname FROM names WHERE id = 7;
Bob
session1> COMMIT;
同一个事务的两次相同查询,返回的记录会因为其他事务的提交而变化。
那么它的适用场景是什么呢?
- sql乐观锁更新的自旋
sql乐观锁更新,不外乎以下两种写法:
-- version机制, 先查询出version, 每次更新记录的时候,version值自动加1
select version as old_version from gamer where id = 101;
# 1
int new_score = 1000;
update gamer a set a.score = {new_score}, a.version = a.verson + 1
where id = 101 and version={old_version}
-- 实际执行语句:
update gamer a set a.score = 1000, a.version = a.verson + 1
where id = 101 and version=1;-- 更新条件, 将查询出来的score作为查询条件,保证在更新的时候,被更新的值是前面查询出来的值。
select score as old_score from gamer where id = 101;
# 980int new_score = 1000;
update gamer a set a.score={new_score} where id = 101 and score={old_score};
-- 实际执行语句:
update gamer a set a.score=1000 where id = 101 and score=980;
这里有一个问题,如果更新的并发度比较大的时候,会出现频繁的更新失败。
所以,建议你在更新的外围,使用一个自旋。
下面是一个java语言实现的伪代码:
// 自旋3次
boolean flag = false;
int newScore = 1000;
for (int i = 0; i < 3; i++)
{// 每次自旋,都再次查询数据库,因为其他事务可能修改该记录。所以隔离级别必须是读已提交。// 如果是可重复读,这里的自旋就没有任何意义。Game game = gameService.findById(101);falg = gameService.update(game.getScore(), game.getId(), newScore);//或者 falg = gameService.update(game.getScore(), game.getId());// 更新成功,提前退出if (flag) {break;}
}
四、查询和设置事务隔离级别
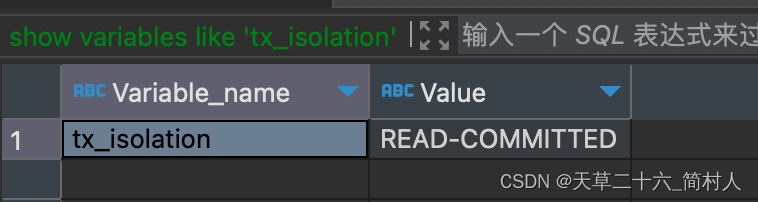
show variables like 'transaction_isolation';
show variables like 'tx_isolation';
-- 设置全局事务级别为 READ-COMMITTED
set global transaction isolation level read committed;
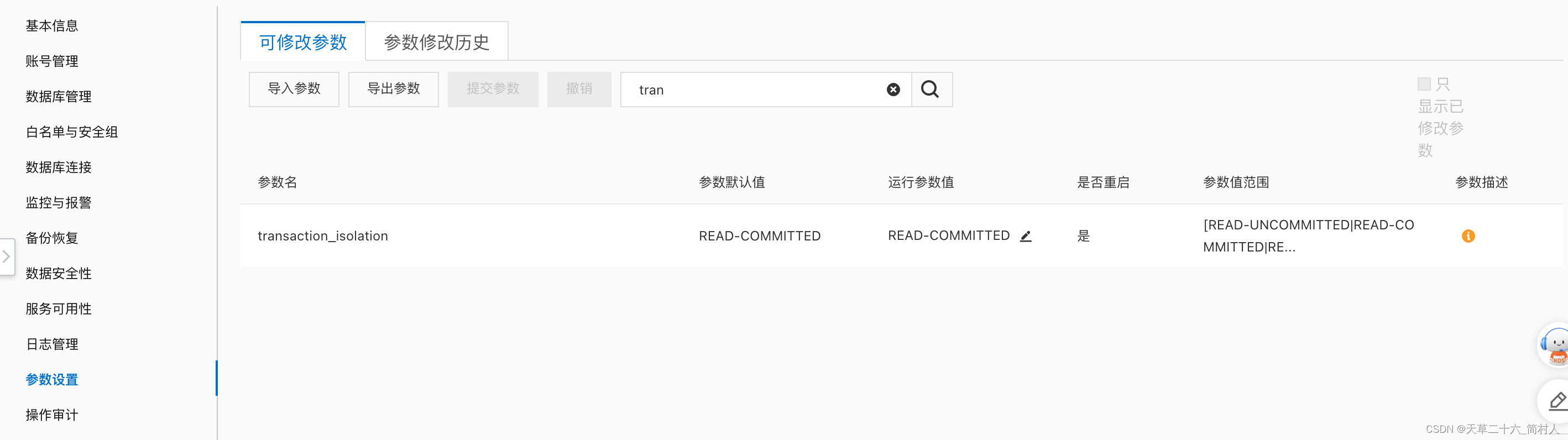
阿里云的RDS,支持修改该参数,不过需要重启生效。
这篇关于关系型数据库的数据隔离级别Read Committed与Repeatable Read的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





