producer专题

RocketMQ源码分析----Producer队列选择与容错策略
队列选择 在HA的文章里大概讲了一下Producer如何为高可用贡献出一份力量的,当时只是说了遍历列表选择队列,然后选择一个,没有深入分析,这篇文章深入分析一下其源码,首先从发送消息选择队列的代码开始: String lastBrokerName = null == mq ? null : mq.getBrokerName();MessageQueue tmpmq = this.sel
RocketMQ源码分析----Producer启动过程
总体流程 首先从demo为入口分析整个启动过程 public static void main(String[] args) throws MQClientException {DefaultMQProducer producer = new DefaultMQProducer("ProducerGroupName");producer.setNamesrvAddr("127.0.0.1:9
kafka ---- producer与broker配置详解以及ack机制详解
一、producer 配置 1、bootstrap.servers kafka broker集群的ip列表,格式为:host1:port1,host2:port2,… 2、client.id 用于追踪消息的源头 3、retries 当发送失败时客户端会进行重试,重试的次数由retries指定,默认值是2147483647,即 Integer.MAX_VALUE;在重试次数耗尽和deli

Kafka·Producer
Producer发送原理 拦截器进行拦截 对key和value进行序列化 org.apache.kafka.clients.producer.KafkaProducer#doSend 分区选择 计算消息要发送到topic的哪个分区上 若指定了分区,则使用指定的值没有指定的话则使用分区器计算得到或者使用hash取余的方式 暂存消息到累加器 Producer并不会立刻发送消息到Bro

【Kafka】Kafka Producer 分区-05
【Kafka】Kafka Producer 分区-05 1. 分区的好处2. 分区策略2.1 默认的分区器 DefaultPartitioner 3. 自定义分区器 1. 分区的好处 (1)便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。 (2)提
tensorflow中 tf.train.slice_input_producer() 函数和 tf.train.batch() 函数
原创:https://blog.csdn.net/dcrmg/article/details/79776876 别人总结的转载方便自己以后看 tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责
Kafka之Producer原理
1. 生产者发送消息源码分析 public class SimpleProducer {public static void main(String[] args) {Properties pros=new Properties();pros.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146

RocketMq源码解析四:生产者Producer启动
一、主要接口和类 生产者服务核心接口和类的关系如下图所示: MQProducer是生产者解耦,这里找几个有代表性的方法 // 同步发送消息 SendResult send(final Message msg) throws MQClientException, RemotingException, MQBrokerException,Interrupte

Kafka producer拦截器(interceptor)详解
一、 拦截器原理 Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。 对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(i
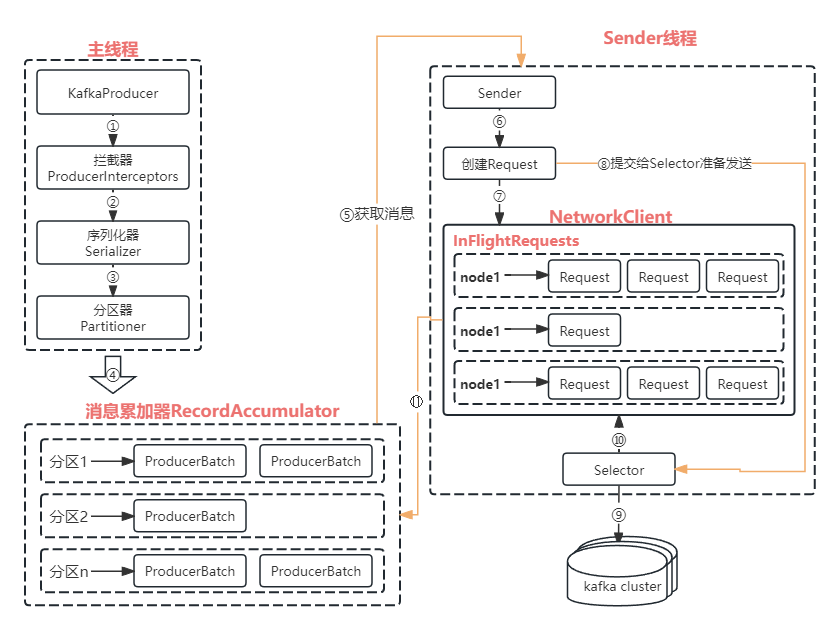
kafka学习笔记(三、生产者Producer使用及配置参数)
1.简介 1.1.producer介绍 生产者就是负责向kafka发送消息的应用程序。消息在通过send()方法发往broker的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用后才能被真正的发往broker。 demo: public class KafkaClient {private stat

Apache Kafka(六)- High Throughput Producer
High Throughput Producer 在有大量消息需要发送的情况下,默认的Kafka Producer配置可能无法达到一个可观的的吞吐。在这种情况下,我们可以考虑调整两个方面,以提高Producer 的吞吐。分别为消息压缩(message compression),以及消息批量发送(batching)。 1. Message Compression Producer一般发送的数据

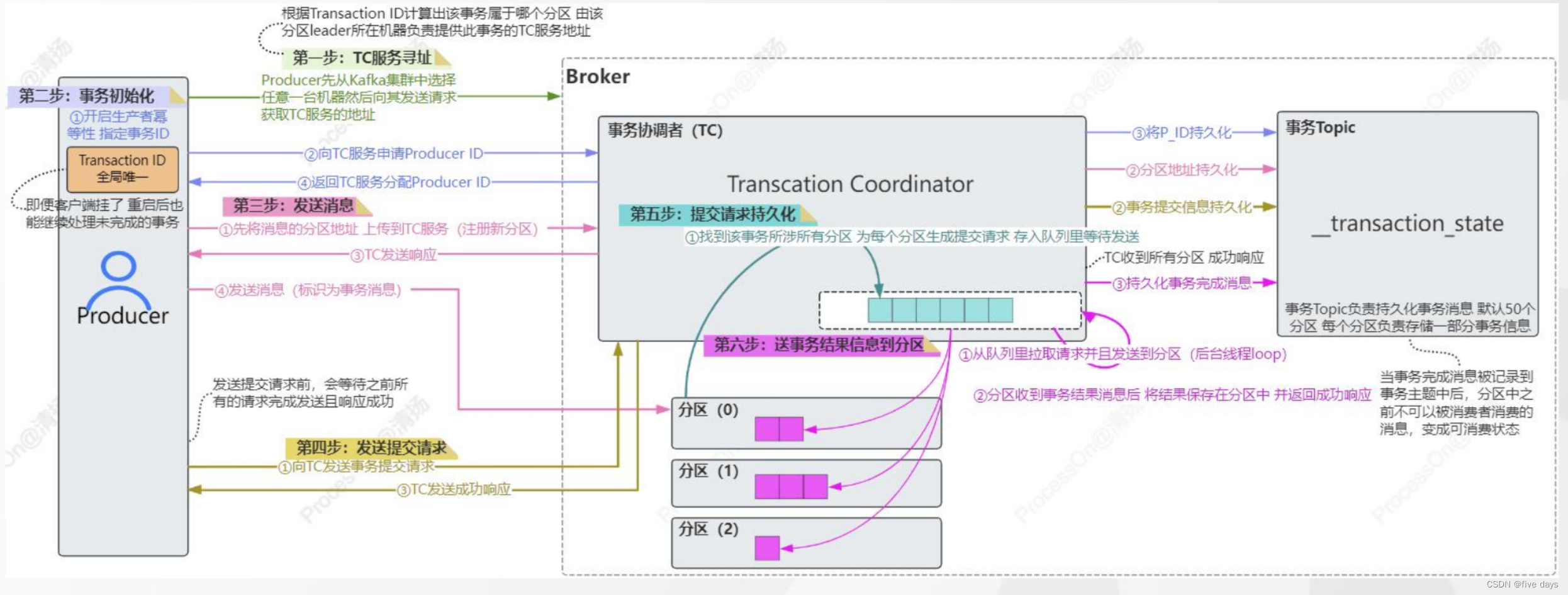
Apache Kafka(五)- Safe Kafka Producer
Kafka Safe Producer 在应用Kafka的场景中,需要考虑到在异常发生时(如网络异常),被发送的消息有可能会出现丢失、乱序、以及重复消息。 对于这些情况,我们可以创建一个“safe producer”,用于规避这些问题。下面我们会先介绍对于这几种情况的说明以及配置,最后给出一个配置示例。 1. acks 详述 之前我们介绍过 Kafka Producer 的 acks 有三种
alpakka-kafka(1)-producer
alpakka项目是一个基于akka-streams流处理编程工具的scala/java开源项目,通过提供connector连接各种数据源并在akka-streams里进行数据处理。alpakka-kafka就是alpakka项目里的kafka-connector。对于我们来说:可以用alpakka-kafka来对接kafka,使用kafka提供的功能。或者从另外一个角度讲:alpakka-kaf

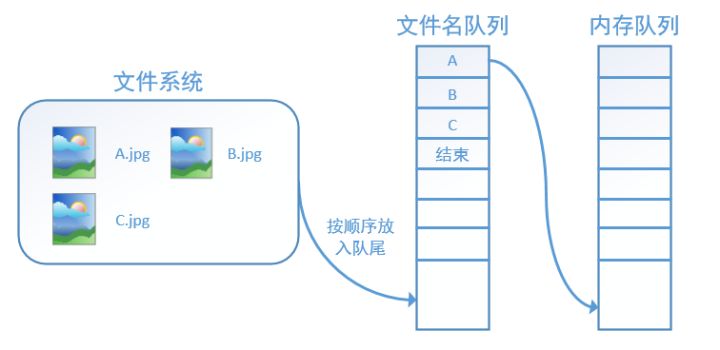
tensorflow笔记 string_input_producer, slice_input_producer
tensorflow将读取数据分为了两个步骤,先读入文件名队列,再读入内存队列进行运算。为了减少GPU的等待时间,提高计算速度,tensorflow使用两个线程来分别处理这两个步骤。tf有三个函数string_input_producer, slice_input_producer, input_producer用于建立文件名队列。 函数参数如下所示,除了tensor list是必须外,其余都可

linux下C语言实现多线程通信—环形缓冲区,可用于生产者(producer)/消费者(consumer)
一、概念引入 日常生活中,每当我们缺少某些生活用品时,我们都会去超市进行购买,那么,你有没有想过,你是以什么身份去的超市呢?相信大部分人都会说自己是消费者,确实如此,那么既然我们是消费者,又是谁替我们生产各种各样的商品呢?当然是超市的各大供货商,自然而然地也就成了我们的生产者。如此一来,生产者有了,消费者也有了,那么将二者联系起来的超市又该作何理解呢?诚然,它本身是作为一座交易场所而诞生。 将上

Kafka Producer异步发送消息技巧大揭秘
欢迎来到我的博客,代码的世界里,每一行都是一个故事 Kafka Producer异步发送消息技巧大揭秘 前言异步发送概述方法实现2. `producer.send(msg)` 方法详解方法签名和参数说明异步发送示例代码及效果分析 3. `producer.send(msg, callback)` 方法解析支持事务的消息发送方法介绍发送消息并回滚的实践案例 4. Li

一文彻底搞懂Producer端流程以及原理
一、引言 无论你是刚接触Pulsar还是使用Pulsar多年,相信你对下面这段代码都很熟悉,这就是生产者端最常写的代码没有之一,其中最核心的其实就三行代码,分别用红色数字标识出来了,其中对应的就是1、客户端对象创建 2、生产者对象创建 3、消息发送。今天就分别针对这三个步骤进行深入的探索。 二、创建客户端对象 无论是写生产者还是消费者端代码,第一步都是要创建客户端对象,那么客户端对象都做了
大数据技术之_10_Kafka学习_Kafka概述+Kafka集群部署+Kafka工作流程分析+Kafka API实战+Kafka Producer拦截器+Kafka Streams
大数据技术之_10_Kafka学习 第1章 Kafka概述1.1 消息队列1.2 为什么需要消息队列1.3 什么是Kafka1.4 Kafka架构 第2章 Kafka集群部署2.1 环境准备2.1.1 集群规划2.1.2 jar包下载 2.2 Kafka集群部署2.3 Kafka命令行操作 第3章 Kafka工作流程分析3.1 Kafka 生产过程分析3.1.1 写入方式3.1.2 分区(P
RocketMQ之Producer
1 Producer有个ProducerGroup的值需要设置,因为Producer是可以分布式部署的,我们需要将逻辑上属于一个整体的producer关联起来,那就靠ProducerGroup这个值来设置的,同属一个group的producer产生的消息理论上应该是一个业务类型。构造Producer的时候可以指定: private final DefaultMQProducer PRODUCE
EOS中plugin之producer_plugin
EOS中plugin之producer_plugin EOS中的插件是非常重要的工具,其中大大小小总共有26个插件,其中比较重要的插件有chain_plugin、producer_plugin、http_plugin、net_plugin等四个插件。这四个插件在EOS服务器端启动后也开始启动进行工作。 abstract_plugin EOS中所有插件继承于plugin类,而plugin类又继
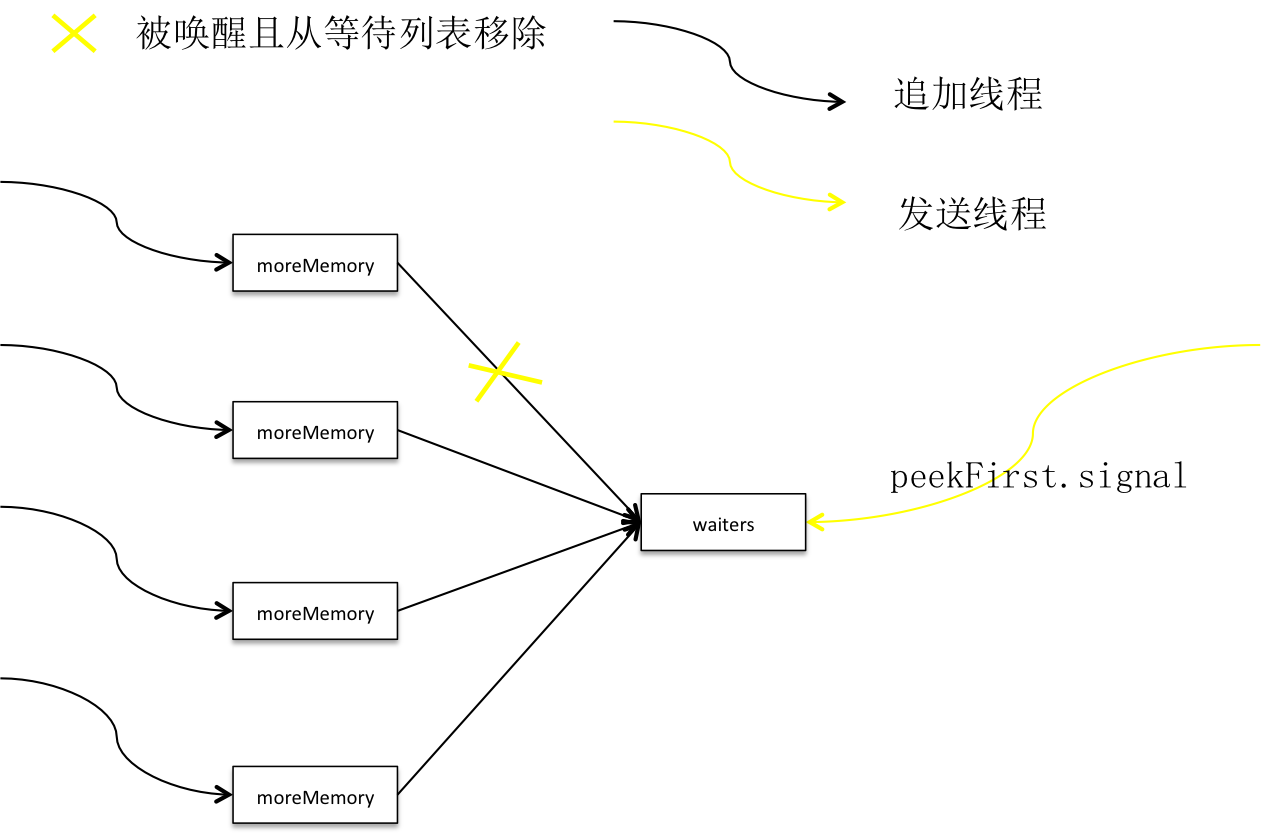
更加深入理解Kafka--Producer篇(下)
批次 积累器在创建批次之前,就在堆上为它预分配一段空间,这段空间用于装载消息。消息最终会顺序落到内存块中形成消息集。批次的逻辑结构如下: 5.0.1 * MemoryRecords即消息集的抽象,它容纳0到多条Record。 * Record则代表消息在内存中的状态,即按二进制协议格式化之后的消息结构,它是消息集的元素。 * 用户可通过compression.type
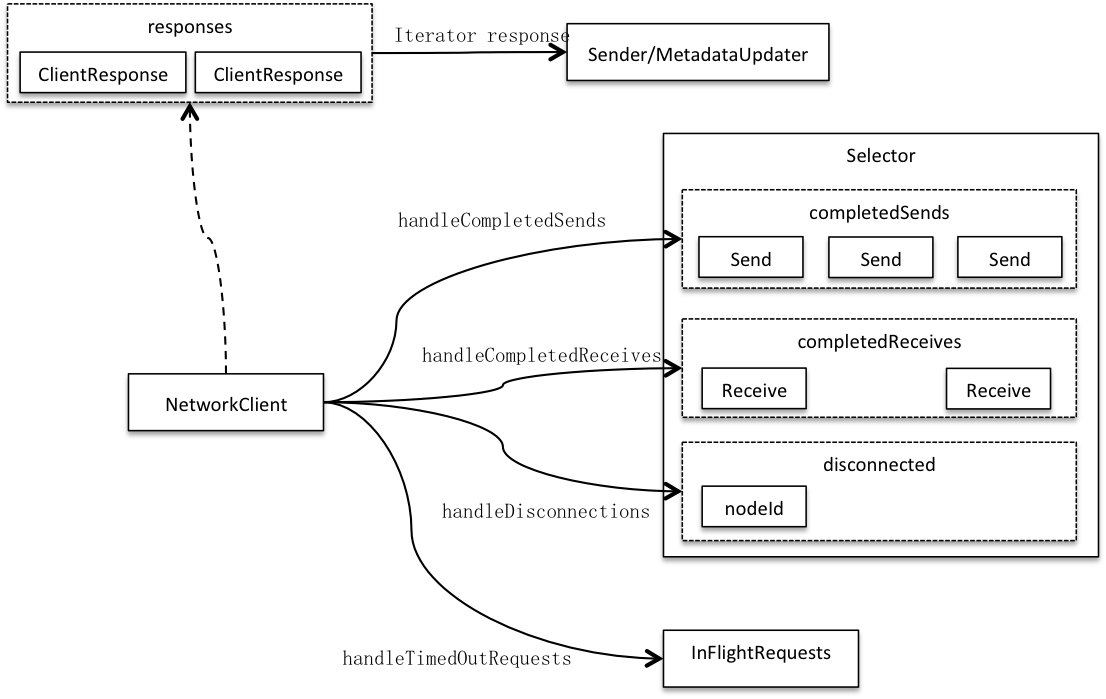
更加深入剖析Kafka--Producer篇(中)
客户端 客户端和服务端都是网络传输的终(端)点,两者角色是相对而言的,前者主动发起请求并接收后者应答。 3.0.1 两端之间由通道(连接)连通,每个客户端都有0到多个通道连接0到多个服务端。通道通过传输层交换数据,传输层有加密和明文两种实现。客户端通过选择器轮询所有通道,标记连接状态并收发网络数据,客户端获得所有通道处理结果再统一应答。这样就将客户端与具体网络I/O
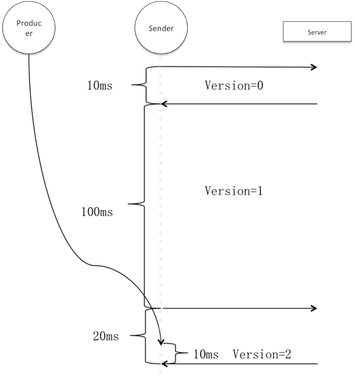
更加深入剖析Kafka--Producer篇(上)
背景 Kafka诞生于Linkedin,以可靠性和巨量吞吐著称,网上清一色将它归为消息队列,用户可以按主题发布及订阅流经Kafka的数据,从这角度看它确实是消息队列,但这仅仅是它的一个方面,在这之上它首先是流式数据传输管道。 管道对实时分析的价值是巨大的,首先它是实时分析系统的天然缓冲屏障,可以通过固定的消费频率避免被突如其来的流量峰值击垮;其次它架起了业务系统到分析系统的数据路径,也将分析和
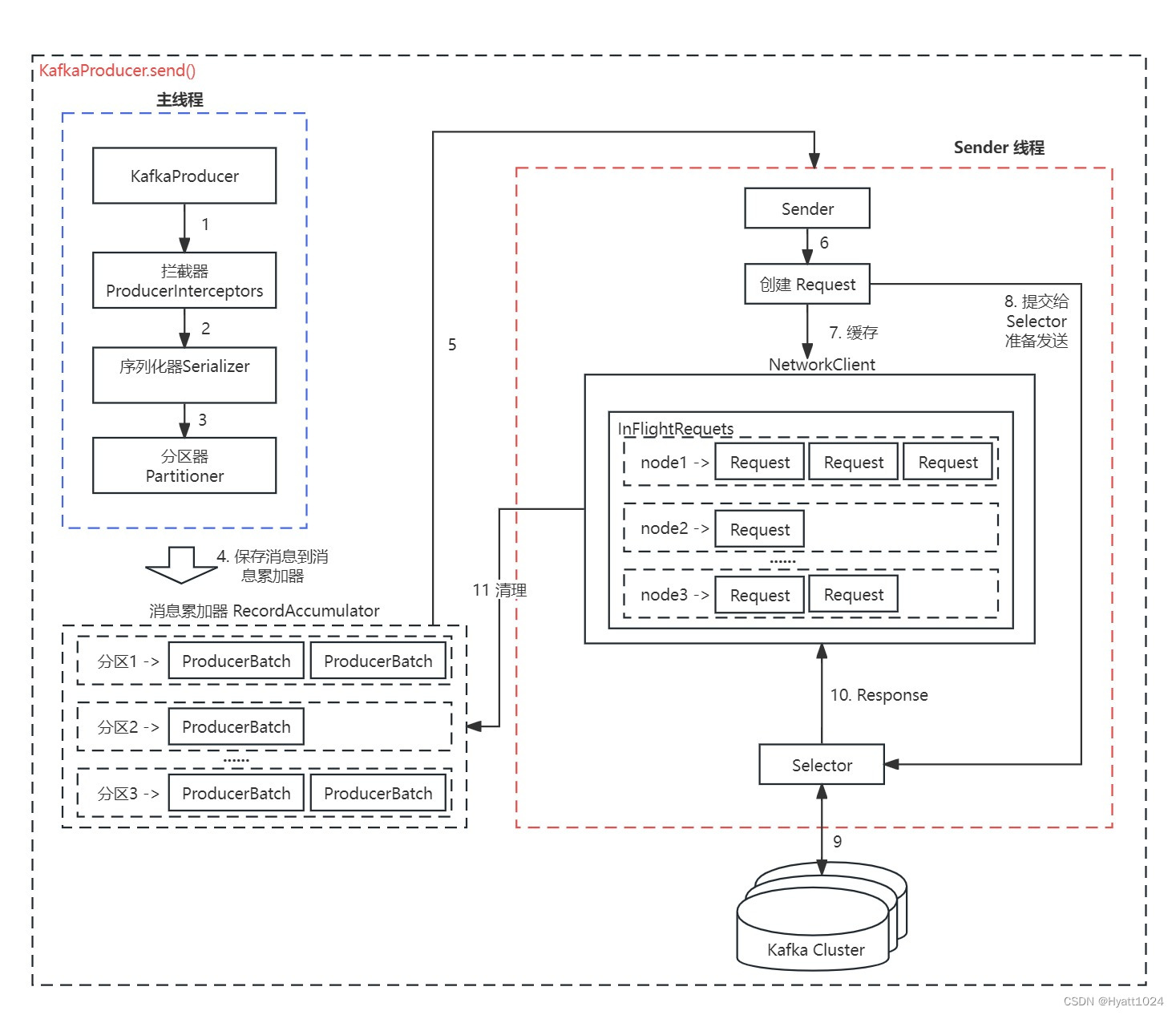
【Kafka系列 06】Kafka Producer源码解析
温馨提示:本文基于 Kafka 2.3.1 版本。 一、Kafka Producer 原理图 生产者的 API 使用还是比较简单,创建一个 ProducerRecord 对象(这个对象包含目标主题和要发送的内容,当然还可以指定键以及分区),然后调用 send 方法就把消息发送出去了。 talk is cheap,show me the code。先来看一段创建 Producer 的代码

FL Studio Producer Edition2024中文进阶版Win/Mac
FL Studio Producer Edition,特别是其【中文进阶版 + Win/Mac】,是数字音乐制作领域中的一款知名软件。它为广大音乐制作人、声音工程师以及音乐爱好者提供了一个从音乐构思到最终作品发布的完整解决方案。这个版本特别为中文用户优化,并兼容Windows和Mac操作系统,确保了跨平台的无缝体验。 FL Studio 21.2.3 Win-安装包下载如下: https://

FL Studio Producer Edition v21.2.3.4004 最新版本作为 Windows 离线安装程序2024免费下载
Fl Studio 21.2.3.4004最新中文版直装版是最新的音乐制作工具。它可以与各种音乐制作令人惊叹的音乐工作。它提供了一个相当简单和用户友好的集成开发环境工作。这整个音乐工作站是由比利时公司图像线开发的。其先进的理念帮助初学者和专业人士创作、安排、录制、编辑和混合音乐。 Fl Studio 21.2.3.4004使您能够用高质量的主音乐制作音乐。您可以创建各种轨道与它的最新功能。FL