本文主要是介绍更加深入剖析Kafka--Producer篇(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
Kafka诞生于Linkedin,以可靠性和巨量吞吐著称,网上清一色将它归为消息队列,用户可以按主题发布及订阅流经Kafka的数据,从这角度看它确实是消息队列,但这仅仅是它的一个方面,在这之上它首先是流式数据传输管道。
管道对实时分析的价值是巨大的,首先它是实时分析系统的天然缓冲屏障,可以通过固定的消费频率避免被突如其来的流量峰值击垮;其次它架起了业务系统到分析系统的数据路径,也将分析和业务两个系统在一定程度上解耦。仅从数据角度看,管道成了分析系统的入口。
为什么是更深入
经过我过人的”视野“洞察后,我决定踢开”百撕不得其姐“的Spark,改从入口的Kafka突破。小卡也的确很贴心,Producer端完全java化了,我也逐渐了适应了Idea烦人的快捷键和界面,看起源码来开始得心应手。其实一开始我也没打算看源码,买了本厚厚的书,期待它能像《深度理解Java虚拟机》一样开启我的智慧,结果它光只贴源码了,我一直认为真正的懂是撇开代码能讲清楚一件事,所以决定还是一行行的阅读代码,然后尽可能分析得比书更深入,所以就叫《更加深入剖析Kafka》,这一周会陆续补完生产者篇。
数据集成
数据集成从领域/系统集成角度看很类似早期的数据库表接口,有过这种经历的都会明白其中的痛苦,suffer a lot,这也是为什么业界在反思后更多主张依赖抽象的接口集成方式。理论上对任何事物做抽象后都是数据,所以数据集成架构可以解决任何事情,但这种解决是建立在人对数据有所定义上,当数据的生产和消费不是一个人时就很容易出现问题。
消息系统也有类似问题,如果由源系统定义消息结构,消息的任何变动就需要充分评估,这就像回到了关系集成的时代,要改表尤其修改某个字段语义变得几乎不可能,先召集大家开会,再制定改动方案,而往往是即使做了充分的事前评估,落地时还是一堆问题,几乎永远评估不到这份数据的使用全貌。因此往往源系统定义的消息都会字段超多,因为只能加字段而无法改和删。如果在协作上由下游系统定义消息结构,它就会更类似是个抽象接口,但在下游系统很多且共通性很小时这也变得几乎不可能。所以消息只能带来松耦合而无法换来高内聚,源系统开发一定会是想拿刀捅死胆敢要求修改消息结构的那群人,呲牙瞠目的喊“How dare u,fucker”
我不是反对消息以及数据集成,只是反思这种方式,也不主张接口万岁,没有一种集成方式是万能的。集成方式应该基于团队协作方式制定,比如提供web服务那肯定是接口比消息更适合。
地图
我喜欢抠代码细节会比较啰嗦,所以光生产者篇就会很长。我觉得架构设计就是细节,系统设计撇开细节只谈愿景是无意义的。比如Spring Ioc,原型上很简单,不就是个反射吗,很多人也跟我这么说过,但是深入到细节里就会发现其扩展性之优秀、配置可描述性之完备以及场景丰富度支撑之多等都是看到后会真心发出”挖草“的。Kafka也是这样的优秀中间件,很多细节处理得都特别精妙,简直就是极尽所能在榨干工程师智慧获得性能和稳定性上的一点一点提升。
本篇会分三章去叙述:
第一章主要讲关键概念、集群拓扑结构以及客户端如何自感知结构变更
第二章主要讲客户端、传输协议和最核心的积累器
第三章则主要讲优异性能和吞吐的关键批次
概念
Broker,Server,Producer和Consumer是Kafka的四个关键概念,每个中间件都有自己特有的一套术语命名方式,用大白话讲它们分别就是节点、服务端、消息生产者和消息消费者。
生产者
生产者泛指一切消息源,KafkaProducer并不是Kafka的生产者实现,而是提供给生产者使用的编程API。生产者使用KafkaProducer.send实际只是将消息暂存至待发送批次,而在此之前它会依次被过滤、序列化和分区。
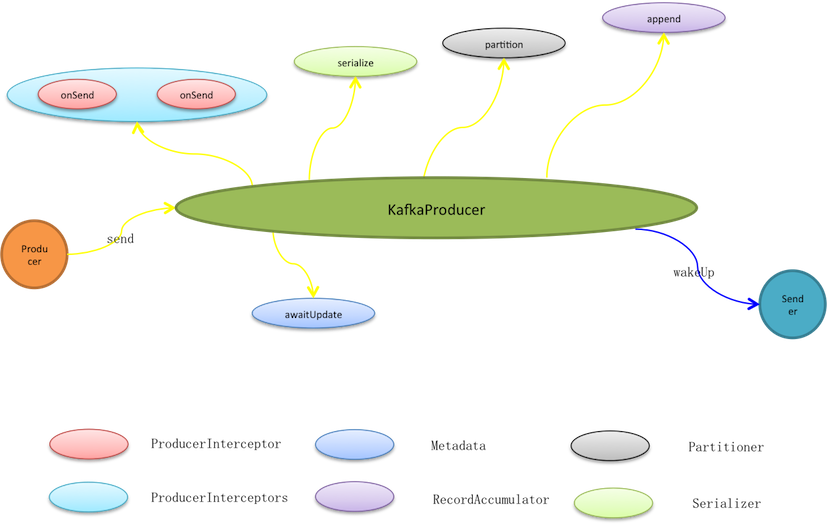
* 过滤是链式动作,通过interceptor.classes可以指定多个ProducerInterceptor类型的过滤器,按预定义顺序它们被编排入过滤链(ProducerInterceptors)。消息发送、异常以及ack动作都会触发过滤链的相应过滤动作,过滤器再根据编排顺序被依次调用。消息发送就会先过滤再处理,过滤器可以修改消息内容,但无法终止消息发送甚至无法中断过滤链,因为过滤链catch所有异常且不抛出只log记录。
* 消息被传输之前是暂存在预分配的ByteBuffer上,因此需要将消息序列化成Byte数组。KafkaProducer按照用户预定义的key.serializer和value.serializer序列化方式进行序列化,将键和值都转成Byte数组。
发送者
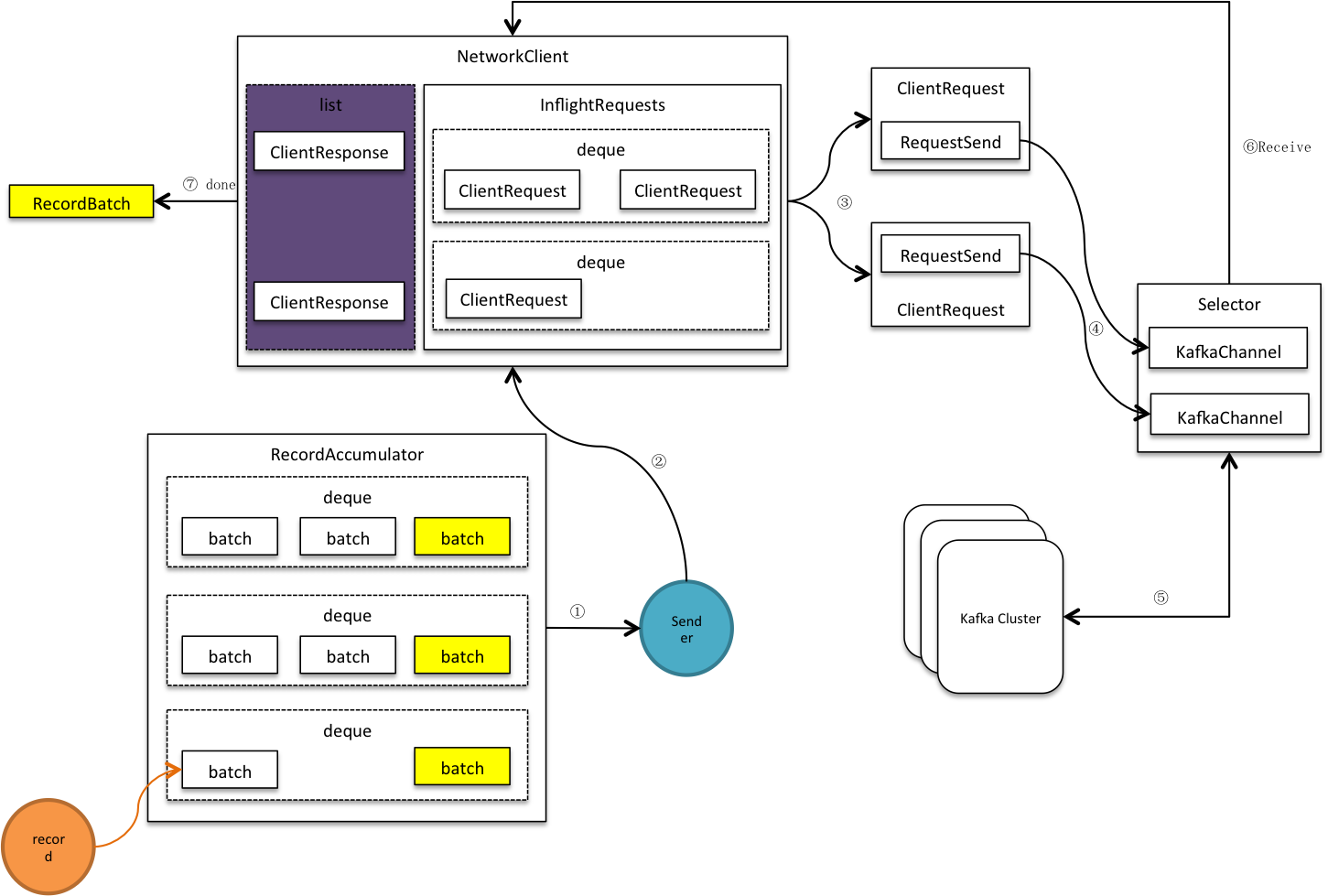
发送者是个守护线程,它1)收集可发送批次,将发送到相同节点的多个批次合并到同个请求,这些请求被放入<处理中请求(InFlightRequests)>,接着再写进网络通道。2)客户端开始网络轮询,发送通道中的缓冲数据,同时接收服务端应答数据。3)移除InFlightRequests中的完成请求,并进行客户端响应,关闭相关批次,释放批次所占内存。
集群
集群是对完整能力的纵向切分,目标是将流量均摊而且能水平扩展。Kafka在纵向以外又对集群横向切分。两个维度的交叉切分形成网格化的精细布局,数据被填入网格中,使读写甚至清理都效率很多,同时还能有效避免Hadoop的单点困境,领袖网格在各个节点均匀分布,流量也相应被切分平摊。
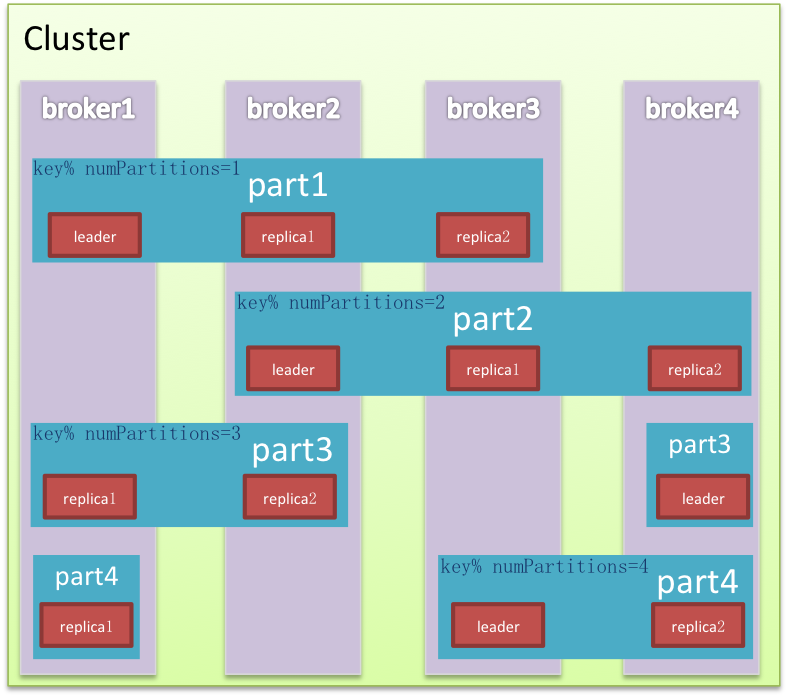
节点Node是集群的物理组成单元,也是垂直切分后的计算单元。Kafka除极少数以外的服务能力均由领袖提供,是非典型中心化集群,因为Kafka会尽量保证领袖的均匀分布,这样中心流量就被均匀打散。
分区是逻辑存储单元,是水平切分的产物,数据相对均匀的分散在各个分区,磁盘I/O处理效率也会因此大大提升。同时为保证集群高可用,分区内节点以及角色也是相对动态的,Kafka在分区内做冗余备份有多份Replica,在leader/follower故障的情况下自动做备援转移到可用节点。
元数据
节点、分区以及领袖、备份的分布等集群拓扑信息被称为元数据Metadata,元数据会动态变化,例如单点Broker故障,又或者使用Admin删除topic,…… ,因此客户端需要不断更新以及时感知这些变化。
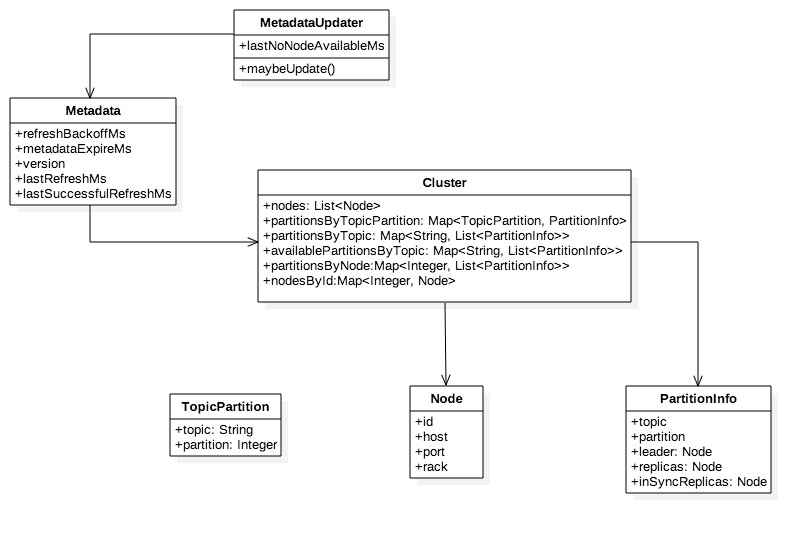
+ MetadataUpdater是刷新元数据的外观类,是KafkaClient组成部分,它尝试发起元数据更新,如果满足更新条件则立即发起更新请求。
+ Metadata的refreshBackoffMs和metadataExpireMs分别代表刷新周期和失效延时,lastRefreshMs和lastSuccessfulRefreshMs则分别代表上次刷新时间和上次成功刷新时间,注意二者区别,前者只要发生update就会被记录无关成功与否。version代表元数据版本,每次成功更新默认加1。
+ Cluster是客户端维护的集群拓扑结构,可以进行多维查询,在元数据更新成功后会被覆盖。
+ 分区信息(PartitionInfo)中的inSyncReplicas即ISR是指在同步状态的副本,其他属性都比较直观不做过多说明,。
元数据更新
每个topic都是一个二维拓扑结构,映射到具体的节点和分区;集群容纳多个topic,因此集群拓扑结构是三维的,映射到具体topic加节点加分区。更新实质就是拉取服务端的相关topics的拓扑信息,因此每次更新都需要指定感兴趣的topics。
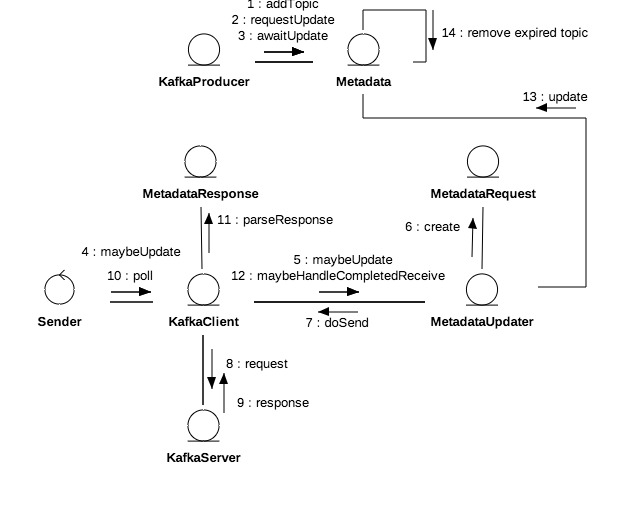
元数据更新是周期性的,客户端每次轮询网络都会先尝试更新元数据。MetadataUpdater是客户端的元数据更新组件,它会综合元数据更新延时和重连延时判定是否需要发起更新,其公式为A=Max(元数据更新延时,重连延时)。如果A>0或者有元数据获取正在进行中不进行更新。
1. 元数据更新延时=Max(失效时间, 更新时间),
+ 更新时间=上次刷新时间+刷新周期(retry.backoff.ms)-当前时间。
+ 失效时间=上次成功刷新时间+失效延时(metadata.max.age.ms)-当前时间,如果元数据被标记为强制更新(needUpdate),则立即失效。
2. 重连延时=无可用节点发生时间+重试周期-now。
3. 元数据获取是指请求已发送但结果还未返回,正在等待结果获取中。
生产者每次发送消息前都会强制元数据更新,它标记元数据需要更新并阻塞等待直至超时或更新成功。但这并不意味每一笔消息都产生一次网络更新请求,参考以上更新发起条件,即使标记需要更新在更新周期以外也不会发生更新,因此同一更新周期内的多次更新会堵塞等待同一笔更新成功。
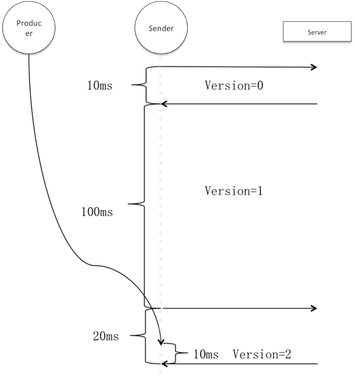
上图假设刷新周期是100ms,并且在第一次和第二次轮询期间无更新请求。生产者的请求在阶段3进来,此时元数据轮询请求已经发出,因此用户线程实际只阻塞了10ms。假设阶段3有多个用户线程,则平均等待时间应为<刷新周期+更新请求时间/2>。
服务端的任意节点而非仅领袖节点都有完整的拓扑结构,为了获得最快的响应速度客户端只需请求负载最小的可用节点。负载的依据是客户端自己发出的到每个节点处理中请求数,即inFlightRequests大小,所以其并不代表绝对意义上的最小负载。如无可用节点,客户端会记录下无可用节点时间lastNoNodeAvailableMs。
选出的节点若是断开状态但可进行重试(距离最近建立连接的时间超过reconnect.backoff.ms),则立即初始化连接。因为Non-blocking I/O建立连接不一定立即成功,所以不能立即发送更新请求而是延到之后的执行周期。
客户端收到服务端更新应答后对元数据更新,更新会做两件事情:淘汰过期(默认5分钟)topic和覆盖客户端拓扑结构。如果发生网络异常比如建立连接失败、连接断开以及连接超时,直接标记元数据需要更新,因为此时有可能是服务端拓扑结构发生变化。但这种情况更新不需要重新指定topic,因为发生连接问题不会有服务端响应则更不会有元数据更新。
这篇关于更加深入剖析Kafka--Producer篇(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





