本文主要是介绍kafka学习笔记(三、生产者Producer使用及配置参数),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

1.简介
1.1.producer介绍
生产者就是负责向kafka发送消息的应用程序。消息在通过send()方法发往broker的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用后才能被真正的发往broker。
demo:
public class KafkaClient {private static final String brokerList = "localhost:9092";private static final String tipic = "topic-test";public static Properties initConfig() {Properties props = new Properties();props.put("bootstrap.servers", brokerList);props.put("key.serializer", "org.apache.kafka.common.seralization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.seralization.StringSerializer");props.put("clinet.id", "producer.client.id.test");return props;} public static void main(String[] args) {Properties props = initConfig();KafkaProducer<String, String> producer = new KafkaProducer<>(props);ProducerRecord<String, String> record = new ProducerRecord<>(topic, "kafka producer test.");try {producer.send(record);} catch (Exception e) {e.printStackTrace();}}
}
ProducerRecord类:
public class ProducerRecord<K, V> {private final String topic; // 主题private final Integer partition; // 分区号private final Headers headers; // 消息头部private final K key; // 键private final V value; // 值private final Long timestamp; // 消息的时间戳
}
-
ProducerRecord类中的key属性:
key用来指定消息的键,不仅是附加消息还可以用来计算分区号而可以让消息发往特定的分区。同一个key的消息会被划分到同一分区有key的消息还可以支持日志压缩的功能
-
必要参数:
- bootstrap.servers:客户端连接kafka集群所属broker地址(host1:port1),
并非需要所有的broker地址,生产者会从给定的broker中查到其他broker信息,建议至少设置两个以上。 - key.serializer和value.serializer:broker端接收的消息必须以字节数组(
byte[])的形式存在。发往broker之前需要将消息中对应的key和value做相应的序列化操作来转换整字节数组。
- bootstrap.servers:客户端连接kafka集群所属broker地址(host1:port1),
- KafkaProducer是线程安全的,可以在多个线程中共享单个KafkaProducer实例,也可以将KafkaProducer实例进行池化来供其他线程使用。
- 消息发送有三种模式
- 发后即忘(fire-and-forget):
producer.send(record);- 同步(sync):
producer.send(record).get();- 异步(async):
producer.send(record, callback);// 回调函数的调用可以保证分区有序。
1.2.生产者拦截器
用来在消息发送前做一些准备工作,比如按照某个规则过滤、修改消息内容等,也可以用来在发送回调逻辑中做一些定制化的需求。
实现: 需自定义实现
org.apache.kafka.clinets.producer.ProducerInterception接口。接口中有三个方法:public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record); // 对消息进行相应的定制化处理// 在消息被应答或发送失败时调用,优先于Callback之前执行。此方法运行在Producer的IO线程中,所以 // 此方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。 public void onAcknowledgement(RecordMetadata metadata, Exception exception);public void close();
KafkaProducer可以指定多个拦截器形成拦截链。拦截链会按照interceptor.classes参数配置的拦截器顺序来执行。
1.3.序列化
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给kafka。而在对侧,消费者需要反序列化器(Deserializer)把从kafka中收到的字节数组转换成对应的对象。
客户端自带的序列化器都实现了
org.apache.kafka.common.serialization.Serializer接口,此接口有三个方法:public void configure(Map<String, ?> configs, boolean isKey); // 配置当前类,主要确定编码类型 public byte[] serialize(String topic, T data); // 将类型T的数据转换为byte[] public void close(); // 关闭当前的序列化器,一般情况下为空方法生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的。
1.4.分区器
为消息分配分区。如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。
kafka提供的默认分区器是
org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了org.apache.kafka.clients.producer.Partitioner接口,此接口中定义了两个方法:// 用来计算分区号 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); public void close(); // 关闭分区器的时候用来回收一些资源Partitioner接口还有一个父接口
org.apache.kafka.common.Configurable,此接口只有一个方法:void configure(Map<String, ?> configs); // 获取配置信息机初始化数据
kafka中除了使用默认的分区器进行分区外还可以使用自定义的分区器,只要实现Partitioner即可。
2.整体架构
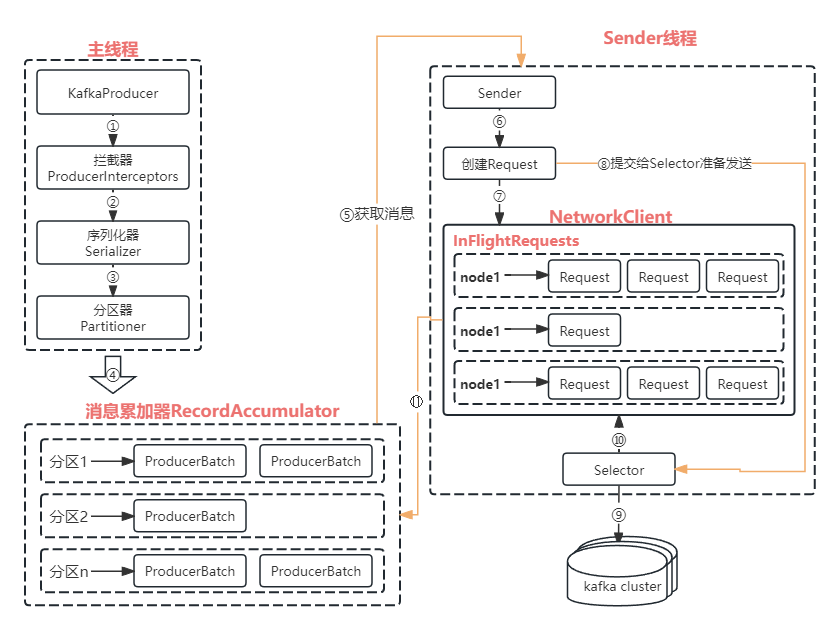
2.1.RecordAccumulator讲解
主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源以便提升性能。(缓存大小通过生产者客户端参数buffer.memory配置,默认32MB)。
如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,此时KafkaProducer的send()方法调用要么被堵塞要么抛出异常,这个取决于参数max.block.ms的配置,默认为60秒。
- 主线程发送过来的消息都会被追加到RecordAccumulator的某个
双端队列(Deque)中,RecordAccumulator内部为每个分区都维护了一个双端队列,队列的内容就是ProducerBatch,即Deque<ProducerBatch>。注意: ProducerBatch中包含一个或多个ProducerRecord。ProducerRecord是生产者创建的消息,ProducerBatch是一个消息批次,ProducerRecord会被包含在ProducerBatch中,使字节的使用更加紧凑,也可以减少网络请求的次数以提高整体的吞吐量。
- 消息写入缓存时,追加到
Deque的尾部;Sender读取消息时,从Deque的头部读取。 - Kafka生产者客户端通过
java.io.ByteBuffer实现消息内存的创建和释放,不过频繁的创建和释放是比较耗费资源的,所以在RecordAccumulator内部存在一个BufferPool来实现ByteBuffer的复用,达到缓存高效利用的目的。BufferPool只针对特定大小(通过
batch.size参数指定,默认16KB)的ByteBuffer进行管理,其他大小的ByteBuffer不会缓存到BufferPool中,我们可以适当的调大batch.size参数以便多缓存一些消息。
2.2.消息进入RecordAccumulator的逻辑
当一条ProducerRecord进入RecordAccumulator时:
- 先寻找与消息分区对应的Deque(没有则创建);
- 再从这个Deque尾部获取一个ProducerBatch(没有则创建);
- 查看ProducerBatch中是否可以写入这个ProducerRecord,可以则写入不可以则需新建ProducerBatch再写入;
新建ProducerBatch时需
评估这条消息是否超过batch.size参数的大小,如不超过则以batch.size参数大小来创建ProducerBatch(使用完这段内存区域后可以通过BufferPool的管理来复用),若超过则以评估的大小来创建(此段内存区域不会被复用)。
2.3.Sender步骤
Sender线程从RecordAccumulator中获取缓存的消息后:
- 将
<分区, Deque<ProducerBatch>>转换为<Node, List<ProducerBatch>>,其中Node表示kafka集群的节点;对网络连接来说,生产者客户端是与具体的broker节点建立连接,不关心消息的分区;而KafkaProducer的应用逻辑则只关注往哪个分区发送那些消息,所以这里需要做一个应用逻辑层面到网络IO层面的转换。
- 将转换的
<Node, List<ProducerBatch>>进一步封装成<Node, Request>的形式,这样就可以将Request发往各个Node了。这里的Request指kafka的各种协议请求,对于消息的发送而言就是指具体的ProducerRequest。
- 请求在从Sender线程发往kafka之前还会以
Map<NodeId, Deque<Request>>形式保存到InFlightRequest中,以缓存已经发出去但还没有收到相应的请求。通过配置参数可以限制每个连接(客户端与Node之间的连接)最多缓存的请求数。此配置参数为:max.in.flight.requests.per.connection,默认为5,即每个连接最多只能缓存5个未响应的请求,超过此值之后就不能再向这个连接发送更多的请求了,除非有缓存的请求收到了响应。
2.4.元数据
值kafka集群的元数据,这些数据包括集群中有主题信息、主题上的分区信息、分区的leader副本信息、follower副本信息、副本的AR和ISR集合信息、集群的节点信息以及控制器节点信息等。
更新元数据信息的条件:
- 当客户端中没有需要使用的元数据信息,比如没有指定的Topic信息;
- 超过
metadata.max.age.ms时间没有更新元数据信息,此配置默认为5分钟;
更新元数据信息的步骤:
- 元数据更新操作时在是在客户端内部进行的,对外部不可见。
- 当需要更新元数据信息时,会先挑选出
leastLoadedNode,然后向这个Node发送MetadataRequest请求来获取具体的元数据信息。 - 这个跟新操作由
Sender线程发起,在创建完MetadataRequest之后同样会存入InFlightRequests,之后的步骤和发送消息类似。
元数据信息
Sender线程负责更新,主线程需要读取,所以这里的数据同步通过synchronized和final关键字来保障。
Producer配置参数
| 参数 | 默认值 | 含义 |
|---|---|---|
bootstarp.servers | “” | 指定连接kafka集群的broker地址(可以只有部分broker地址) |
key.serializer | “” | 消息中key对应的序列化类,需实现org.apahce.kafka.common.serialization.Serialiaer |
value.serializer | “” | 消息中value对应的序列化类,需实现org.apahce.kafka.common.serialization.Serialiaer |
client.id | “” | 指定kafkaProducer对应的客户端id(用来标记消息是从哪个客户端发来的) |
acks | “1” | 指定分区中必须有多少个副本收到此条消息生产者才会认为这条消息是成功写入的。它涉及消息的可靠性和吞吐量之间的权衡。asks=1:leader成功写入则返回成功;acks=0:发送消息后不需要等待服务器的响应;scks=-1/all:ISK集合中所有副本成功写入才能收到服务器的成功响应。 |
buffer.memory | 32MB | 生产者客户端中用于缓存消息的缓冲区大小。详见本章节#2.1 |
batch.size | 16KB | 用于指定producerBatch可以复用的内存区域的大小。 |
max.request.size | 1MB | 限制生产者客户端能发送消息的最大值,一般不建议盲目的增大,因为此参数与broker端的message.max.bytes参数有联动。 |
retries | 0 | 生产者重试次数 |
retry.backoff.ms | 100 | 设定两次重试之间的时间间隔 |
metadata.max.age | 30000ms | 如果在这个时间内无数据没有更新的话会被强制更新 |
compression.type | “none” | 指定消息的压缩方式,默认情况下消息不会被压缩,,该参数还可以配置为"gzip"、"snappy"和"l24"。消息压缩可极大的减少网络传输量,减低网络的IO,提高整体的性能,是一种以时间换空间的优化方式。 |
connections.max.idle.ms | 540000ms | 指定多久之后关闭闲置的连接 |
linger.ms | 0 | 指定生产者发送producerBatch之前等待更过的producerRecord加入ProducerBatch的时间。生产者客户端会在producerBatch被填满或等待时间超过linger.ms值时发送出去。 |
receive.buffer.bytes | 32KB | 设置socket接收消息缓冲区(SO_RECBUF)的大小。如果设置为-1,则使用操作系统的默认值;如果Producer与kafka处于不同的机房,则可以适当调大这个参数值。 |
send.buffer.bytes | 128KB | 设置socket发送消息缓冲区的大小… |
request.timeout.ms | 30000ms | 配置Producer等待请求响应的最大时间。注意此参数需要比broker端参数replica.lag.time.max.ms的值大,这样可以减少因客户端重试而引起的消息重复的概率。 |
max.block.ms | 60000 | 用来控制kafkaProducer中send()方法和partitionsFor()方法的阻塞时间。当生产者的送缓冲区已满或者没有可用的元数据时,这些方法就会阻塞。 |
partitioner.class | ~Defaultpartitioner | 用来指定分区器,需要实现org.apache.kafka.clients.producer.partitioner |
enable.idempotence | false | 是否开启幂等性功能。所谓幂等简单说就是对接口的多次调用所产生的结果和调用一次是一致的。生产者在进行重试的时候有可能会重复的写入消息,而使用kafka的幂等性功能之后就可以避免这种情况。 |
interceptor.classes | “” | 用来设定生产者拦截器,需实现org.apache.kafka.clients.producer.ProducerInterceptor接口。 |
max.in.fligh.request | 5 | 限制客户端与Node之间的连接最多缓存的请求数。 |
per.connection.transactional.id | null | 设置事务id,必须唯一。 |
这篇关于kafka学习笔记(三、生产者Producer使用及配置参数)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




