phoenix专题

大数据-NoSQL数据库-HBase操作框架:Phoenix【Java写的基于JDBC API的操作HBase数据库的SQL引擎框架;低延迟、事务性、可使用sql语句、提供JDBC接口】
一、Phoenix概述 1、Phoenix 定义 Phoenix 最早是 saleforce 的一个开源项目,后来成为 Apache 的顶级项目。Phoenix 构建在 HBase 之上的开源 SQL 层. 能够让我们使用标准的 JDBC API 去建表, 插入数据和查询 HBase 中的数据, 从而可以避免使用 HBase 的客户端 API.在我们的应用和 HBase 之间添加了 Phoen

phoenix查询日期范围
官网太简易了 找官网的内置函数一个个试出来的 有点佩服我自己 哈哈哈 select * from "T_BCAllUserActLog" WHERE "reserved8" is not null and CAST(TO_DATE("reserved8") AS DATE) between CAST(TO_DATE('2018-09-18 00:00:00') AS DATE)and CA

java操作phoenix查询指定table_schema中的数据
原因: 1.phoenix映射hbase表的时候,如果hbase表是存放在某个命名空间下面的话,phoenix创建表的时候必须创建table_schema以后在取创建表,然后才能映射成功 解决方法: 1.如果用./sqlline.py 命令去启动的话,访问schema中的表数据的时候要先使用use <table_schema>命令先指定特定的schema,然后在去访问
springboot上用mybaties与phoenix和hbase进行整合
配置类 import com.alibaba.druid.pool.DruidDataSource;import org.apache.ibatis.session.SqlSessionFactory;import org.mybatis.spring.SqlSessionFactoryBean;import org.mybatis.spring.annotation.MapperScan

HBase的SQL中间层——Phoenix(附大数据入门指南)
大数据依然是当前较为火热的领域,其背后的核心价值是数据。今天分享一个GitHub上一个系类文章,作者是heibaiying,大数据入门指南(2019)地址:https://github.com/heibaiying/BigData-Notes(本文末点击阅读原文进入),内容涉及下图的相关技术。 本文分享其中HBase主题系列里一篇关于Phoenix入门使用的文章,刊载以飨读者,建议复
利用Phoenix为HBase创建二级索引
为什么需要Secondary Index 对于HBase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询。如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄。对于较大的表,全表扫瞄的代价是不可接受的。 但是,很多情况下,需要从多个角度查询数据。例如,在定位某个人的时候,可以通过姓名、身份证号、学籍号等不同的角度来查询,要想把这么多角度的数据都放到row

Phoenix / HBase中的salted table
What are salted tables 为了避免读写HBase表数据时产生hot-spot问题,我们使用Phoenix来创建表时可以采用salted table。 salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,也就避免了读写操作都集中在
使用Phoenix的JDBC接口
使用Phoenix的JDBC接口 Phoenix提供了JDBC接口,可以在Client中方便地以SQL的形式来访问HBase中的数据。 下面以Java代码来展示用法 /*** Created by tao on 4/20/15.** 运行方法:* java -cp rest-server-1.0-SNAPSHOT.jar:jars/* cn.gridx.examples.TestPho

Phoenix 二级索引之— —Global Indexing
1. 说明 在Hbase中,只有一个单一的按照字典序排序的rowKey索引,当使用rowKey来进行数据查询的时候速度较快,但是如果不使用rowKey来查询的话就会使用filter来对全表进行扫描,很大程度上降低了检索性能。而Phoenix提供了二级索引技术来应对这种使用rowKey之外的条件进行检索的场景。 Phoenix支持两种类型的索引技术:Global Indexing和Lo
使用 Phoenix 通过 sql 语句 更新操作 hbase 数据
hbase 提供很方便的shell脚本,可以对数据表进行 CURD 操作,但是毕竟是有一定的学习成本的,基本上对于开发来讲,sql 语句都是看家本领,那么,有没有一种方法可以把 sql 语句转换成 hbase的原生API呢? 这样就可以通过普通平常的 sql 来对hbase 进行数据的管理,使用成本大大降低。Apache Phoenix 组件就完成了这种需求,官方注解为 “Phoenix - w

phoenix实战(hadoop2、hbase0.96)
版本: phoenix:2.2.2,可以下载源码(https://github.com/forcedotcom/phoenix/tree/port-0.96)自己编译,或者从这里下载(http://download.csdn.net/detail/fansy1990/7146479、http://download.csdn.net/detail/fansy1990/7146501)。 h

HBase查询引擎——Phoenix的使用
介绍:Phoenix查询引擎会将SQL查询转换为一个或多个HBase scan,并编排执行以生成标准的JDBC结果集。直接使用HBase API、协同处理器与自定义过滤器,对于简单查询来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。更多参考官网:http://phoenix.apache.org/ 命令行:Sqlline安装: 1、将phoenix-3.0.0-incu
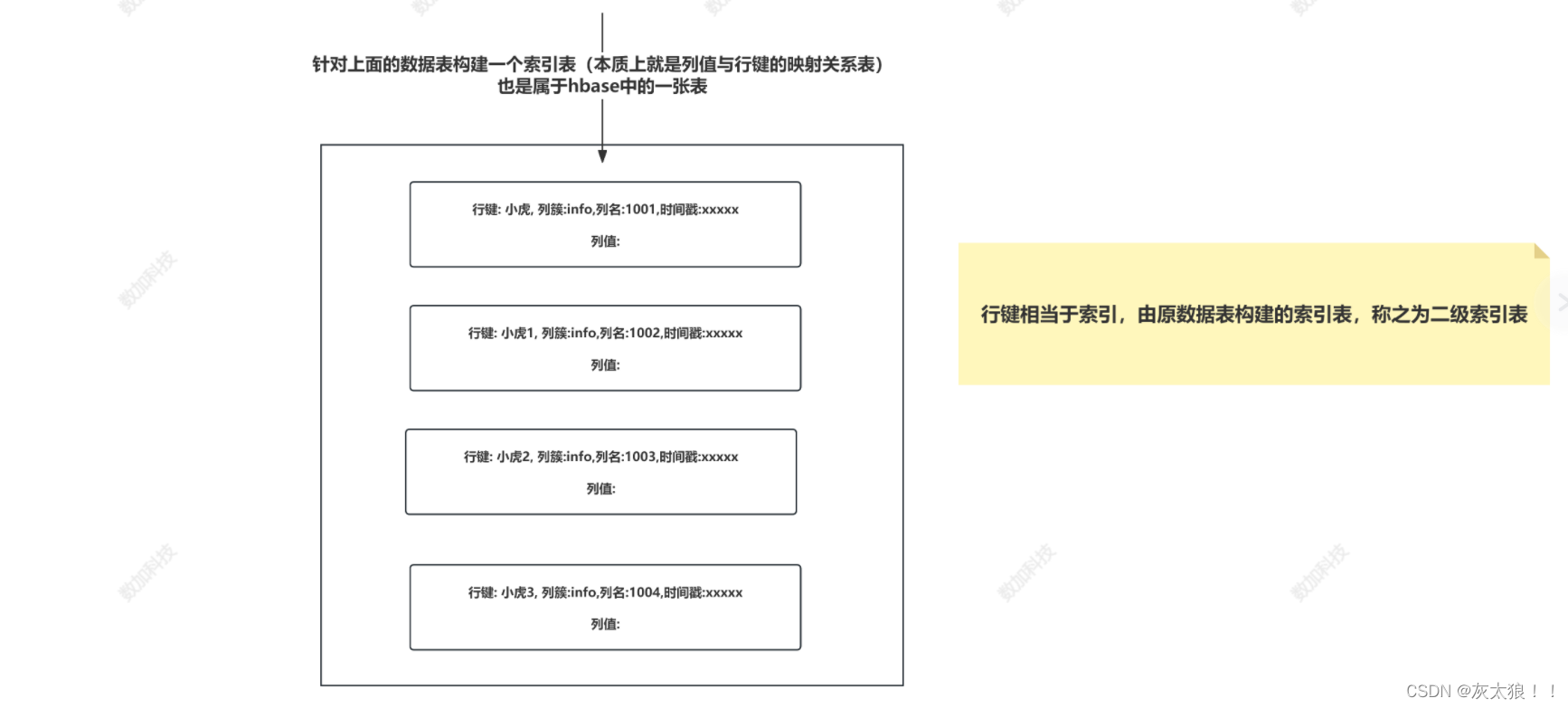
Hbase中二级索引与Phoenix二级索引实现
1、引入 HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。 所以我们引进一个二级索引的概念。二级索引的本质就是建立各列值与行键之间的映射关系 。 图解: 2、常见实现二级索引的方案: HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级

大数据入门之如何利用Phoenix访问Hbase
在大数据的世界里,HBase和Phoenix可谓是一对黄金搭档。HBase以其高效的列式存储和强大的数据扩展能力,成为大数据存储领域的佼佼者;而Phoenix则以其SQL化的操作方式,简化了对HBase的访问过程。今天,就让我们一起看看如何利用Phoenix轻松访问HBase。 题外话,感觉这个配图很贴切,同意的大家请点赞。 一、HBase:大数据的“仓库管理员” HBase,就像是一个
Spring Boot 整合 Apache Phoenix 进行 HBase 数据操作指南
在Spring Boot中集成Apache Phoenix以便执行SQL查询和表操作,你可以使用Phoenix的JDBC驱动。下面是一个简单的示例,展示了如何在Spring Boot应用中集成Phoenix,并执行基本的表操作和查询。 1. 添加依赖 首先,你需要在你的pom.xml文件中添加Phoenix和HBase的JDBC依赖: xml复制代码 <dependencies> <!
phoenix调优小记
从17年调优到了18年,数据从100机器每天1200万,不到两星期累加到了小2个亿数据。 数据插入和查询效率都很低。 1.5 15:520: jdbc:phoenix:localhost:2181> select count(*) from METRIC_RECORD;+-----------+| COUNT(1) |+-----------+| 34244885 |+----

RWTH-PHOENIX Weather数据集模型说明和下载
RWTH-PHOENIX Weather 2014 T数据集说明: 德国公共电视台PHOENIX在三年内(2009 年至 2011 年) 录制了配有手语翻译的每日新闻和天气预报节目,并使用注释符号转录了 386 个版本的天气预报。 此外,我们使用自动语音识别和手动清理来转录原始德语语音。因此,该语料库允许训练从手语视频输入到口语的端到端手语翻译系统。
phoenix客户端API使用
1.准备条件 phoenix与Hbase已经安装好 phoenix-4.3.0 hbase-0.98 2.客户端使用(服务器上使用客户端) 在客户端创建如下文件test.java: import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.S
phoenix操作注意点
一.与hbase 的映射 1.空表格映射 在phoenix中创建表格,会自动映射到hbase中,我们可以通过hbase shell 来查看。举个例子,我们创建了一个表, create table hbase_col_test(pk varchar not null primary key, //primary key 映射到hbase 中的rowkey"cf1"."col1"
springboot集成phoenix,操作hbase
文章目录 前言1、版本要求1.1 对hbase版本的支持 2、微服务集成2.1 创建gradle项目,添加依赖2.2 application.yml配置2.3 准备调试环境2.3.1 服务器配置2.3.2 本地配置 3 Phoenix语法3.1 创建表3.2 删除表3.3 查询数据3.4 删除数据3.5 插入或更新数据3.6 Phoenix映射HBase以正确的姿势创建表映射创建表来进行表
基于 HBase Phoenix 构建实时数仓(2)—— HBase 完全分布式安装
目录 一、开启 HDFS 机柜感知 1. 增加 core-site.xml 配置项 2. 创建机柜感知脚本 3. 创建机柜配置信息文件 4. 分发相关文件到其它节点 5. 重启 HDFS 使机柜感知生效 二、主机规划 三、安装配置 HBase 完全分布式集群 1. 在所有节点上配置环境变量 2. 解压、配置环境 3. 修改 $HBASE_HOME/conf/regionser
基于 HBase Phoenix 构建实时数仓(3)—— Phoenix 安装
目录 一、主机规划 二、Phoenix 安装 1. 解压、配置环境 2. 将 phoenix-server-hbase-2.5-5.1.3.jar 文件复制到 HBase 的 lib 目录中 3. 重启 HBase 集群 4. 安装验证 (1)连接 HBase (2)视图映射 (3)表映射 参考: 一、主机规划 继续上一篇,本篇介绍在同一环境中安装

SanctuaryAI推出Phoenix: 专为工作而设计的人形通用机器人
文章目录 1. Company2. Main2.1 关于凤凰™ (Phoenix)2.2 关于碳™(Carbon)2.3 商业化部署2.4 关于 Sanctuary Corporation 3. My thoughtsReference彩蛋:将手机变为桌面小机器人 唯一入选《时代》杂志 2023 年最佳发明的通用机器人。 称机器人自主做家务的速度和灵活度已达到了和人类相当的水平。

Sanctuary AI旗下世界上首个采用Carbon驱动的人形通用机器人Phoenix最新演示视频
Phoenix,作为世界上首个采用Carbon驱动的人形通用机器人,展现了一种开创性和独特的AI控制系统,赋予了机器人接近人类的智能水平。这一革命性的Carbon系统能够将自然语言无缝转化为现实世界中的实际行动,从而赋予Phoenix跨足多个行业的能力,完成数百项精确且多样化的任务。这一技术突破不仅拓宽了机器人的应用范围,还预示着人工智能与人类交互方式的新篇章。 更多消息:AI人工智能行
Phoenix使用ROW_TIMESTAMP字段导致无法从null更新数据的故障描述
在使用Phoenix的过程中,发现了一个奇怪的异常现象,其中一个表,有个字段(VARCHAR类型),一旦这个字段被更新为null值,从此就无法重新更新该字段的值。 我在测试过程中,重新新建一张表,就发现可以正常更新,是我困惑不已。 最后经过反复对比,发现是另外一个字段设置成ROW_TIMESTAMP导致的,下面详细讲述一些问题的复习。 目前测试发现问题的Phoenix版本为4.14.0