numa专题

计算机基础之:UMA与NUMA区别
基础 UMA(Uniform Memory Access)与NUMA(Non-Uniform Memory Access)是两种不同的内存架构设计,主要应用于多处理器系统中,它们的主要区别在于内存访问的效率和方式: UMA(Uniform Memory Access) 架构描述:UMA架构是一种对称多处理器(SMP)设计,所有处理器通过一个共享的内存控制器访问共同的物理内存池。这意味着所有处

SMP、NUMA、MMP的简介
原文地址:《SMP、NUMA、MMP的简介》 1、什么是SMP架构 SMP是指对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)。对SMP服务器进行扩展的方式包括增加内存、使用更快的CPU、增加CPU、扩充I/O

《What every programmer should know about memory》-NUMA Support译
原文PDF: http://futuretech.blinkenlights.nl/misc/cpumemory.pdf 一二章参考博文:https://www.oschina.net/translate/what-every-programmer-should-know-about-memory-part1?lang=chs&p=6 目的在边学习边翻译让自己理解的更加深刻。 5. NUMA
openGauss 鲲鹏NUMA架构优化
鲲鹏NUMA架构优化 可获得性 本特性自openGauss 1.0.0版本开始引入。 特性简介 鲲鹏NUMA架构优化,主要面向鲲鹏处理器架构特点、ARMv8指令集等,进行相应的系统优化,涉及到操作系统、软件架构、锁并发、日志、原子操作、Cache访问等一系列的多层次优化,从而大幅提升了openGauss数据库在鲲鹏平台上的处理性能。 客户价值 数据库的处理性能,例如每分钟处理交易量(T
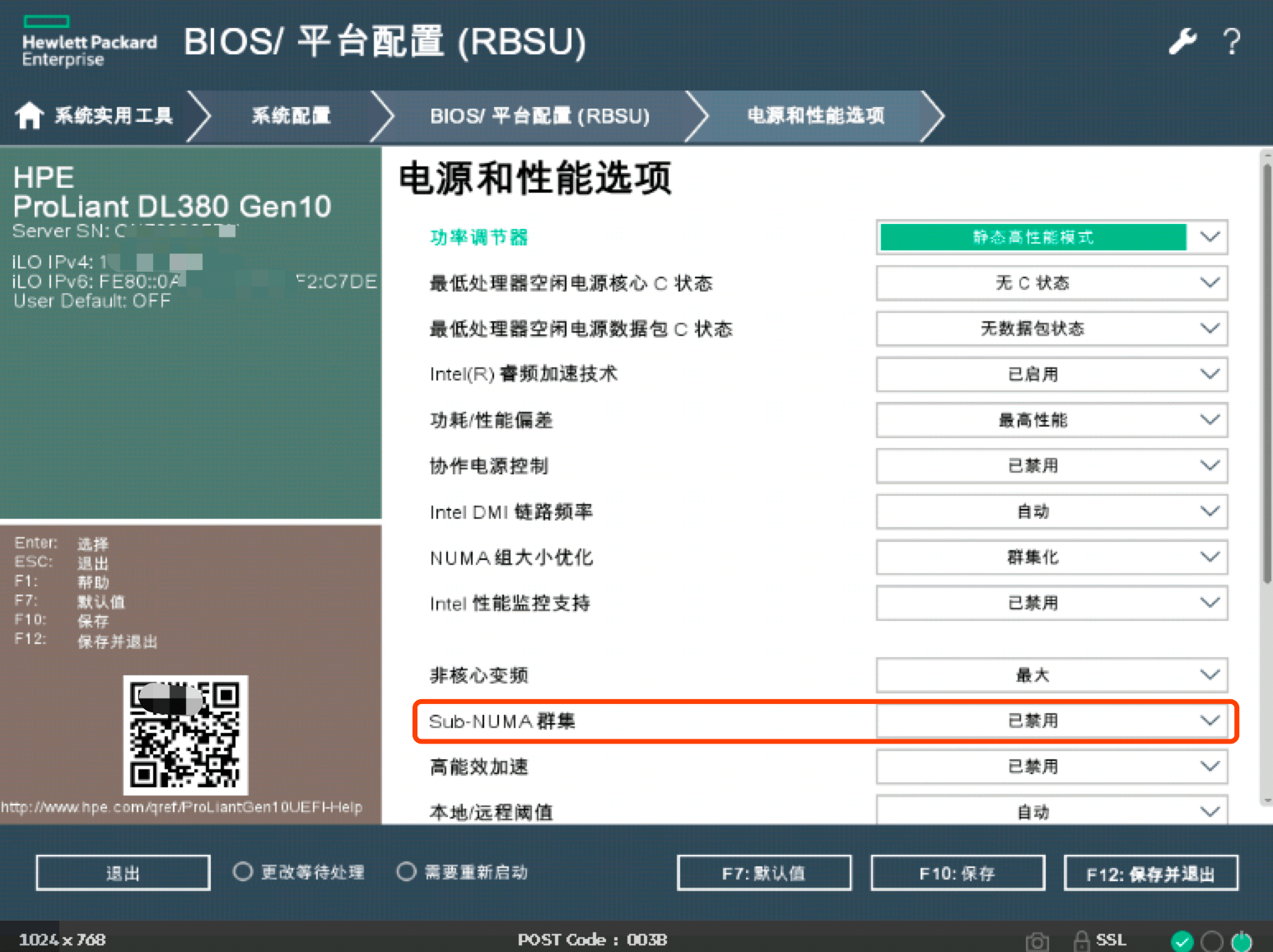
linux服务器ilo口如何查看,HPE DL380 Gen10服务器通过iLO查看/开启/关闭NUMA平衡
修改服务器NUMA需重启服务器生效 第一步:内存选项中禁用节点交错(开启HPE服务器numa平衡需要禁用内存选项中节点交错功能): 解释:可以使用Node Interleaving(节点交错)选项启用或禁用NUMA节点交错,通常,可以禁用该选项以在NUMA节点上获得最佳性能,启用该选项后内存地址,内存地址将交错分散在为每个处理器安装的内存之间,某些工作负载可能会提高性能 1.过程:System

NUMA(Non-Uniform Memory Access)架构的介绍
1. NUMA由来 最早的CPU是以下面这种形式访问内存的: 在这种架构中,所有的CPU都是通过一条总线来访问内存,我们把这种架构叫做SMP架构(Symmetric Multi-Processor),也就是对称多处理器结构。可以看出来,SMP架构有下面4个特点: CPU和CPU以及CPU和内存都是通过一条总线连接起来CPU都是平等的,没有主从关系所有的硬件资源都是共享的,即每个CPU都能
linux性能优化——关于NUMA的配置
检查NUMA配置 numa是为了应对多处理器系统共享同一个总线导致的总线负载过大问题。本质上将M个处理器分为N组,每组处理器之间用IMC BUS总线进行连接,每一组叫做一个Node,其结构类似于一个小的UMA(Uniform Memory Access),每个Node中有一个集成的内存控制器IMC,Intergrated Memory Controller。组内CPU用IMCBUS总线连接,No
CPU亲和性和NUMA架构
何为CPU的亲和性 CPU的亲和性,进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性,进程迁移的频率小就意味着产生的负载小。亲和性一词是从affinity翻译来的,实际可以称为CPU绑定。 在多核运行的机器上,每个CPU本身自己会有缓存,在缓存中存着进程使用的数据,而没有绑定CPU的话,进程可能会被操作系统调度到其他CPU上,如此CPU cache(高速缓冲存储器)

关闭NUMA、透明大页和swap
一、关闭NUMA和透明大页 1.1、编辑/etc/default/grub,在GRUB CMDLINE LINUX 的最后添加: numa=off transparent_hugepage=never [root@pv1fps2dd1 ~]# vi /etc/default/grub GRUB TIMEOUT=5 GRUB_DISTRIBUTOR="$(sed's,rele

2021年二月上旬文章导读与高可用链接 | kmap,vmap,ioremap,Containers-LXC,NAT,virtio,RT,tunning(tuned),NUMA,IP
目录 文章总览 《Linux操作系统实时性分析》 《内存管理的另辟蹊径 - 腾讯云虚拟化开源团队为内核引入全新虚拟文件系统(dmemfs)》 《刨根问底儿,看我如何处理 Too many open files 错误!》 《Linux Containers》 《一次解决Linux内核内存泄漏实战全过程》 文章总览 《Redis为什么要分16个库》https://mp.w
【NUMA平衡】浅入介绍NUMA平衡技术及调度方式
在云计算方案设计或项目问题处理的时候,经常会遇到NUMA平衡的问题,进行让人不清楚NUMA到底有何用,如何发挥作用,本文就NUMA技术原理和调度进行简要整理,方便后续需要时候查阅学习。 一.背景 一般的对称多处理器中,所有处理器都共享系统总线,因此当处理器的数目增大时,系统总线的竞争冲突加大,系统总线将成为瓶颈,所以目前对称多处理器系统的CPU数目一般只有数十个,可扩展能力受到极大限制。NUM
NUMA架构对于程序设计的影响
NUMA指的是非一致性访问模型,现在越来越多的大型计算机系统中采用了NUMA架构的设计,主要是它的扩展性好,也可以降低成本,同一个机位可以存放一个更多核心和更多内存的机器,自然可以降低IDC的建设成本。 对于一个NUMA系统来说,CPU是属于不同的节点node的,内存也是属于不同的node,那么在访问内存时如果是相同node下的CPU和内存之间的访问,那么速度很快,而如果是跨越了node去访问内存