nltk专题

用nltk包出现的三个问题 报错显示 缺少 punkt_tab、averaged_perceptron_tagger、wordnet 这三个文件
用nltk包出现的三个问题 报错显示 缺少 punkt_tab、averaged_perceptron_tagger、wordnet 这三个文件 报错是分开来的,你自己缺少哪一个就下哪一个,我这里总共是缺少三个文件,所以我依次去下载的 首先 在自己的虚拟环境中建立一个nltk_data文件夹,然后去里面建立三个文件夹(这三个文件夹的命名看你报错的内容里面提到的),然后分别去下载对缺少的文件

使用Python和NLTK进行NLP分析的高级指南
在本文中,将利用数据集来比较和分析自然语言。 本文涵盖的基本构建块是: WordNet和同义词集相似度比较树和树岸命名实体识别 WordNet和同义词集 WordNet是NLTK中的大型词汇数据库语料库。WordNet维护与名词,动词,形容词,副词,同义词,反义词等相关的单词的认知同义词(通常称为同义词集)。 WordNet是一个非常有用的文本分析工具。根据许多许可(从开源到商业),它可

nlp---Nltk 常用方法
引言 在nltk的介绍文章中,前面几篇主要介绍了nltk自带的数据(书籍和语料),感觉系统学习意义不大,用到哪里看到那里就行(笑),所以这里会从一些常用功能开始,适当略过对于数据本体的介绍。 文本处理 词频提取 把切分好的词表进行词频排序(按照出现次数排序), 1 2 3 all_words = nltk.FreqDist(w.lower() fo

利用Python的NLTK库来查询指定单词的同义词
一、NTLK库介绍 NLTK(Natural Language Toolkit) 是Python中最为知名的自然语言处理(NLP)库之一,它提供了丰富的模块和数据结构,专门用于人类语言数据的统计自然语言处理。它包含了文本处理库用于分类、标记、语法分析、语义推理和展示等任务,以及覆盖语言学和计算语言学领域的大量实用工具。 主要功能 文本处理:包括分词、句子分割、词性标注、命名实体识别等。


Python自然语言处理(NLP)库之NLTK使用详解
概要 自然语言处理(NLP)是人工智能和计算机科学中的一个重要领域,涉及对人类语言的计算机理解和处理。Python的自然语言工具包(NLTK,Natural Language Toolkit)是一个功能强大的NLP库,提供了丰富的工具和数据集,帮助开发者进行各种NLP任务,如分词、词性标注、命名实体识别、语法解析等。本文将详细介绍NLTK库,包括其安装方法、主要特性、基本和高级功能,

机器学习:基于TF-IDF算法、决策树,使用NLTK库对亚马逊美食评论进行情绪分析
前言 系列专栏:机器学习:高级应用与实践【项目实战100+】【2024】✨︎ 在本专栏中不仅包含一些适合初学者的最新机器学习项目,每个项目都处理一组不同的问题,包括监督和无监督学习、分类、回归和聚类,而且涉及创建深度学习模型、处理非结构化数据以及指导复杂的模型,如卷积神经网络、门控循环单元、大型语言模型和强化学习模型 对于文本分析,我们将使用 NLTK 库。NLTK 是构建 Pyth

离线下载安装 NLTK 的 nltk_data 模块
在 Linux 上使用 NLTK,因为无法联网,只能离线安装。 离线下载的包:nltk_data,提取密码: 9uk5 查看下载配置位置,在 python 环境下,输入: import nltknltk.data.find(".") 就会显示对于这些数据的搜索路径,nltk 会自动搜索这些路径: 所以,只需要把刚刚离线下载的 nltk_data 放在其中任何一个位置即
![[python] nltk 报错[nltk_data] Error loading stopwords: hostname](/front/images/it_default.gif)
[python] nltk 报错[nltk_data] Error loading stopwords: hostname
下载stopwords import nltkimport ssltry:_create_unverified_https_context = ssl._create_unverified_contextexcept AttributeError:passelse:ssl._create_default_https_context = _create_unverified_https_co
NLTK(7)从文本提取信息(命名实体识别)
理论参考 https://blog.csdn.net/kunpen8944/article/details/83149567 https://blog.csdn.net/LuoXianXion/article/details/88823009 其他 https://www.cnblogs.com/AsuraDong/p/7050859.html#树状图 https://www.cnblogs.co
NLTK(3)处理文本、分词、词干提取与词形还原
文章目录 访问文本@字符串处理@编码@正则表达式分词@正则表达式分词(不好)Tokenize命令@自定义函数 规范化文本将文本转换为小写查找词干@自定义函数(不好)NLTK词干提取器PorterLancasterSnowball 词形还原 访问文本 方法一: f=open(r"E:\dict\q0.txt","r")for line in f:print(line.str

NLTK(0)参考文章
陈仕鸿老师http://www.scholat.com/ibm255 AsuraDong 博客NLTK学习笔记https://www.cnblogs.com/AsuraDong/tag/自然语言处理/miniAi学堂python自然语言处理笔记 https://blog.csdn.net/weixin_43935926?t=1黄九剑 https://blog.csdn.net/wangsiji_
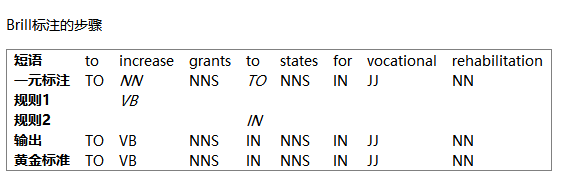
NLTK(5)词性标注
文章目录 如何确定一个词的词性1形态学线索2句法线索3语义线索 NLTK标注器标注语料库查看标注未简化标记集词性搜索 @字典定义字典反转字典字典方法 自动标注默认标注器(不好) 标注效果评估正则表达式标注器查询标注器回退 N-gram标注一元标注器N-gram标注器缺点 组合标注器标注生词一个基于上下文标注生词的方法: @准确性的极限Brill标注器思想Brill标注的步骤代码

NLTK (1.1)自然语言处理简介
文章目录 自然语言处理简介自然语言自然语言处理自然语言处理的应用文本处理的基本流程 自然语言处理简介 自然语言 所谓“自然语言”,是指人们日常交流使用的语言,如英语,印地语,葡萄牙语等。 相对于编程语言和数学符号这样的人工语言,自然语言随着一代人传给另一代人而不断演化,因而很难用明确的规则来刻画。 自然语言处理 从广义上讲,“自然语言处理”(Natural Languag
NLTK(6.2)文本分类方法理论
文章目录 特征工程计数向量作为特征==TF-IDF向量作为特征==词嵌入作为特征主题模型作为特征基于文本/NLP的特征 建模 来自知乎https://www.zhihu.com/tardis/sogou/art/37157010 特征工程 在这一步,原始数据将被转换为特征向量,另外也会根据现有的数据创建新的特征。为了从数据集中选出重要的特征,有以下几种方式: 计数向量作为特

NLTK(9.2)生成特征向量与文本相似度
文章目录 生成对应特征向量 生成对应特征向量 几种文本特征向量化方法 1.词集模型:one-hot编码向量化文本(统计各词在文本中是否出现) 2.词袋模型:文档中出现的词对应的one-hot向量相加(统计各词在文本中出现次数,在词集模型的基础上。) 3.词袋模型+IDF:TFIDF向量化文本(词袋模型+IDF值,考虑了词的重要性) 4.N-gram模型:考虑了词的顺序
NLTK自然语言处理(2)NLTK常用命令
文章目录 搜索文本相似上下文共同上下文单词的位置信息离散图 单词计数文本长度词汇表单词个数与单词占比平均词长、句长、每个词出现次数 简单的统计频率分布频率分布类中定义的函数 条件频率分布细粒度的选择词按字符长度选择单词多重条件选择单词 词语搭配和双连词 搜索文本 相似上下文 similar() 用来查看与目标词出现在相似上下文中的词。第一个参数是目标词,第二个参数是相似词的个

Python NLP自然语言处理 nltk载入自己语料库的方法以及文本分词处理
一、使用NLTK中的PlaintextCorpusReader 帮助下载入它们 PlaintextCorpusReader 初始化函数的第一个参数是你要加载的文件的路径,第二个参数可以是一个如['a.txt', 'test/b.txt']这样的 fileids链表,或者一个匹配所有fileids的模式 ,如:'[abc]\.txt' 假定你的文件在/usr/share/dict 目录下,匹配该
nltk下载出错问题
下载出错解决 直接从百度资源下载 https://blog.csdn.net/qq_41595507/article/details/104123975 记住使用时需要将压缩包解压 添加链接描述 nltk包中数据参考 添加链接描述 以及官网链接 添加链接描述

【AI系列】Python NLTK 库和停用词处理的应用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学习,不断总结,共同进步,活到老学到老导航 檀越剑指大厂系列:全面总结 java 核心技术点,如集合,jvm,并发编程 redis,kafka,Spring,微服务,Netty 等常用开发工具系列:罗列

使用Python进行自然语言处理(NLP):NLTK与Spacy的比较【第133篇—NLTK与Spacy】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 使用Python进行自然语言处理(NLP):NLTK与Spacy的比较 自然语言处理(NLP)是人工智能领域的一个重要分支,它涉及到计算机如何理解、解释和生成人类语言。在Python中,有许多库可以用于NLP任务,其中NLTK(Natural Langu

python3安装nltk
NLTK在自然语言处理方面很方便,最近正好在学习tensorflow,利用neural network对文本分类 完成上一篇博客中ubuntu14.04下python3安装tensorflow1.1的配置后,安装nltk 安装nltk pip3 install nltk (为了后续实验方便,这里采用python3, pip3安装) 完成后import nltk 没有出现错误 python
linux nltk.download()报错
可在https://github.com/nltk/nltk_data/ 下载,安装到对应的目录 比如wordnet的目录是在/users/***/anaconda3/envs/semeval2020/share/nltk_data/corpora/wordnet 因为我只需要wordnet,所以只下载了这个。