neon专题

NEON + OpenMP测试
在嵌入式的开发中,一直有在使用OpenMP和NEON加速,这次对二者的加速效果做了一个对比,包括二者的组合效果,因为只测试了加法的情况,其他的运行逻辑需要再实际使用中评估。 具体的测试代码如下: #include <QCoreApplication>#include <omp.h>#include <arm_neon.h>#include <QTime>#include <QDebug

【ARMv8/ARMv9 硬件加速系列 2.3 -- ARM NEON 的四舍五入指令】
文章目录 NEON 的四舍五入SRSHLR 指令格式SRSHLR 操作说明SRSHLR 示例解释 NEON 的四舍五入 SRSHR指令是ARMv8 NEON SIMD指令集中的一部分,用于对向量中的每个元素进行向右的算术位移操作,并将结果四舍五入。SRSHR指令的全称是Signed Rounding Shift Right,适用于带符号的整数。这个指令对于进行数据尺度缩小、平

【ARMv8/ARMv9 硬件加速系列 2.2 -- ARM NEON 的加减乘除(左移右移)运算】
文章目录 NEON 加减乘除 NEON 加减乘除 下面代码是使用ARMv8汇编语言对向量寄存器v0-v31执行加、减、乘以及左移和右移操作的示例。 ARMv8的SIMD指令集允许对向量寄存器中的多个数据进行并行操作。v0和v1加载数据,对它们进行加、减和乘,左移和右移操作。最后,我们会将结果存储到内存地址0xb0000000处, 方便观察结果。 func neon_calc_

【ARMv8/ARMv9 硬件加速系列 1 -- SVE | NEON | SIMD | VFP | MVE | MPE 基础介绍】
文章目录 ARM 扩展功能介绍VFP (Vector Floating Point)SIMD (Single Instruction, Multiple Data)NEONSVE (Scalable Vector Extension)SME (Scalable Matrix Extension)CME (Compute Matrix Engine)MVE (M-profile Vector
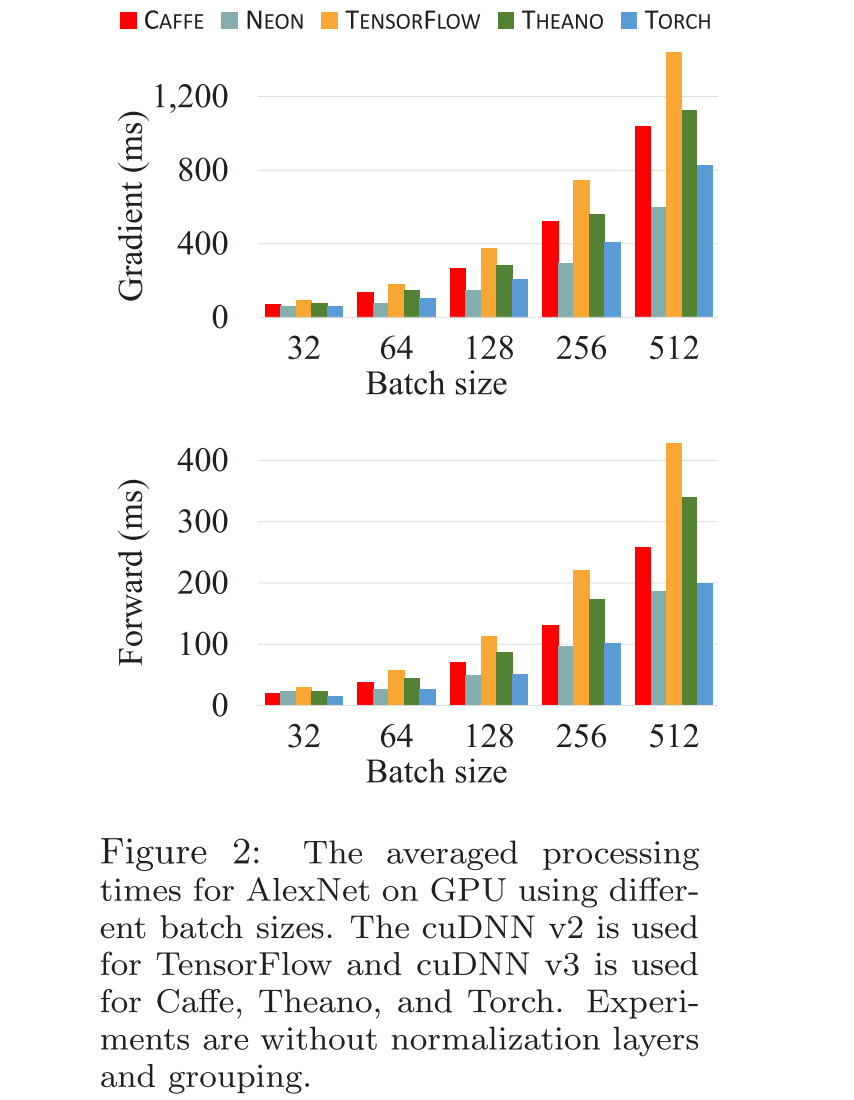
Comparative Study of Deep Learning Software Frameworks( caffe、Neon、TensorFlow、Theano、Torch 之比较)
reference:http://blog.csdn.net/u010167269/article/details/51810613 Preface 最近不少人问我哪个开源框架好用,我自己用过 caffe、TensorFlow、Theano、Torch,用过之后虽然有一定的感觉。但我想很多东西需要实验来具体的验证。 正好我看自己的 Mendeley 中有一篇这个文章:《Comp
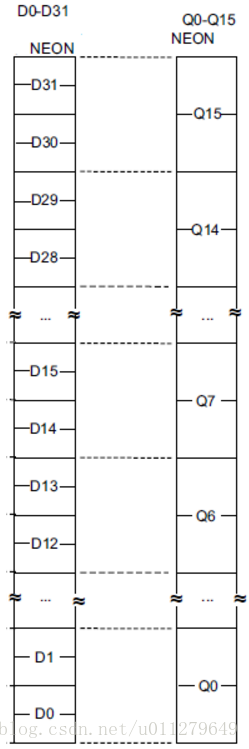
TFLite: neon基础知识
neon介绍 Neon是适用于ARM Cortex-A系列处理器的一种SIMD(Single Instruction, Multiple Data)扩展结构。NEON有自己的执行管道和寄存器组,neon寄存器组包含32个64位的寄存器和16个128位的寄存器,它们分别被标识为(D0-D31),(Q0-Q15)。 实际上D寄存器和Q寄存器是重叠的,如下图所示。NEON 技术本质上是一
UVA 1510 Neon Sign(计数)
UVA 1510 Neon Sign 题目链接 题意:给定一些点两两相连,已知每两点连接是红色还是蓝色,问同色三角形有多少个 思路:由于不同色三角形也有两边同色,直接考虑不好考虑,反过来考虑,先找出不同色三角形,对于每个点而言,找一个红边和一个蓝边就能构成不同色三角形,那么每个三角形被选了3次,其中一次是同色的不用考虑,所以最后答案除以2,然后在用总情况数C(n, 3) - s

使用自动矢量化编译Neon
概述 作为程序员,你有多种方式使用 Neon 技术: 支持 Neon 的开源库,例如 Arm Compute Library提供一种最简单的方式使用 Neon编译器的自动矢量优化特性可以利用 Neon 技术自动优化你的代码Neon intrinsics内建函数,编译器用相应的 Neon 指令进行了封装,你可以在 C/C++ 代码中直接使用 Neon 指令对于经验丰富的程序员来说,为了获得极佳的
【NEON 和 VFP 编程】NEON通用算术指令
本节包括以下小节: • VABA{L} 和 VABD{L} 向量差值绝对值累加和差值绝对值。 • V{Q}ABS 和 V{Q}NEG 向量绝对值和求反。 • V{Q}ADD、VADDL、VADDW、V{Q}SUB、VSUBL 和 VSUBW 向量加法和减法。 • V{R}ADDHN 和 V{R}SUBHN 选择高半部分的向量加法和选择高半部分的向量减法。 • V{R}HADD 和
【NEON 和 VFP 编程】NEON移位指令
本节包括以下小节: • VSHL、VQSHL、VQSHLU 和 VSHLL(按立即数) 按立即值左移。 • V{Q}{R}SHL(按有符号变量) 按有符号变量左移。 • V{R}SHR{N}、V{R}SRA(按立即数) 按立即值右移。 • VQ{R}SHR{U}N(按立即数) 按立即值右移并进行饱和。 • VSLI 和 VSRI 左移并插入,右移并插入。 一、VSHL、VQS
【NEON 和 VFP 编程】NEON通用数据处理指令
本节包括以下小节: • VCVT 向量在定点数或整数与浮点数之间转换。 • VDUP 将标量复制到向量的所有向量线。 • VEXT 提取。 • VMOV、VMVN(立即数) 移动和求反移动(立即数)。 • VMOVL、V{Q}MOVN、VQMOVUN 移动(寄存器)。 • VREV 反转向量中的元素。 • VSWP 交换向量。 • VTBL、VTBX 向量表查找。
【NEON 和 VFP 编程】NEON 逻辑运算和比较运算
这节内容包括: • VAND、VBIC、VEOR、VORN 和 VORR(寄存器) 按位与、位清除、异或、或非以及或(寄存器)。 • VBIC 和 VORR(立即数) 按位位清除和或(立即数)。 •VBIF、VBIT 和 VBSL 为 False 时按位插入,为 True 时按位插入以及按位选择。 • VMOV、VMVN(寄存器) 移动和求反移动。 • VACGE 和 VACGT
【NEON 和 VFP 编程】NEON 和 VFP 共享的指令
NEON 和 VFP 共享的指令包括以下内容: 1.VLDR 和 VSTR 扩展寄存器加载和存储。 2.VLDM、VSTM、VPOP 和 VPUSH 扩展寄存器加载多个和存储多个。 3.VMOV(在两个 ARM 寄存器和一个扩展寄存器之间) 在两个 ARM 寄存器和一个 64 位扩展寄存器之间传送内容。 4.VMOV(在一个 ARM 寄存器和一个 NEON 标量之间) 在一个 AR
【NEON 和 VFP 编程】通用信息
为避免重复,下面列出了许多指令共有的一些信息。 • 浮点异常 • 体系机构的版本 • NEON 和 VFP 数据类型 • NEON 中的正常指令、长指令、宽指令、窄指令和饱和指令 • NEON 标量 • 扩展记号 • {0,1} 上的多项式算法 • VFP 协处理器 • VFP 寄存器 一、浮点异常 在会导致浮点异常的那些指令的描述中,会列出相应的异常。 二、体系机构的版本

【NEON 和 VFP 编程】扩展寄存器组
NEON 是适用于 ARM Cortex-A 系列处理器的一种128位 SIMD(Single Instruction, Multiple Data, 单指令、多数据)扩展结构。 VFP 代表用于矢量运算的矢量浮点架构。迄今为止,VFP 主要有三个版本: VFPv1 已废弃; VFPv2 是对 ARMv5TE、ARMv5TEJ 和 ARMv6 架构中 ARM 指令集的可选扩展; VFPv3

【NEON 和 VFP 编程】条件代码
在 ARM 状态下,可以使用条件代码来控制 VFP 指令的执行。 此类指令是根据 APSR 中的状态标记有条件执行的,执行方式与几乎所有其他 ARM 指令完全相同。 在 ARM 状态下,除 VFP 和 NEON 公用的指令之外,不能使用条件代码来控制 NEON 指令的执行。 在 Thumb-2 处理器上的 Thumb® 状态下,使用一个 IT 指令最多可在随后的四个 NEON 或 VFP 指令
记ARM NEON指令集深度优化
最近和同事一直讨论优化的事情,优化这个概念是模糊的,通常我们都是为了达到某种性能才考虑优化,当某种算法跑在CPU上较为消耗算力,达不到性能指标,可能就要优化。如果我们的代码是用JAVA编写的,那么可以使用Native(C/C++)语言替代其实现。如果Native语言还是无法满足性能要求,那么我们首先想到的应该是如何将Native实现为最优的版本,比如可以使用空间换时间—将一部分固定值先计算好,通过
Failed to read candidate component class: file [F:\eclipse neon\.metadata\.plugins\org.eclipse.wst.s
一、今天在写项目中遇到一个问题,异常如标题 二、这个项目是以前运行过的,并没有修改代码 ,但是却出现了错误。 org.springframework.beans.factory.BeanDefinitionStoreException: Failed to read candidate component class: file [F:\eclipse neon\.metadata\.plug

关于LinuxMelis Kernel Neon使用的一些总结
单指令多数据(Single Instruction Multiple Data, SIMD)是一种使用一条指令就可以同时处理多个数据的技术,其实现原理是把要处理器的多个数据批量加载到位宽比较大的寄存器中,然后使用一条专用的指令对这些数据进行并行处理,如下图所示,SMD的应用场景包括科学计算,音视频编解码,图形处理,机器学习。 NEON的历史 ARM最初是在 armv6上引入SIMD技
x265中量化函数neon汇编实现分析
// uint32_t quant_c(const int16_t* coef, const int32_t quantScale, int32_t* deltaU, int16_t* qCoef, int qBits, int add, int numCoeff) function x265_quant_neon mov w9, #1 //x9的低32位 = 1
x264 arm64汇编分析 quant8x8_neon分析
一 C语言实现 #define QUANT_ONE( coef, mf, f ) \ { \ if( (coef) > 0 ) \ (coef) = (f + (coef)) * (mf) >> 16; \ else \ (coef) = - ((f - (coef)) * (mf) >> 16); \ nz |= (coef); \

NEON 内嵌函数梳理
文章目录 一、介绍1. 简介2. 应用特点3. NEON寄存器4. Neon intrinsics 二、使用方法1. NEON数据类型2. 操作函数3. 案例3.1 RGB 存储3.1.1 C 语言写法3.1.2 Neon写法3.1.3 效果对比 3.2 地图加载3.2.1 C 语言写法3.2.2 Neon写法3.2.3 效果对比 三、注意事项附录rgb_neon.cppmap_neon
性能优化(CPU优化技术)-NEON指令详解
原文来自ARM SIMD 指令集:NEON 简介 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:高性能(HPC)开发基础教程 🎀CSDN主页 发狂的小花 🌄人生秘诀:学习的本质就是极致重复! 目录 ARM SIMD 指令集:NEON 简介 一、NEON 简介 1.1、NEON 简介 1.2、NEON 使用方式 1.3、编译器自动向量化的编译选项 1.3.1 Ar
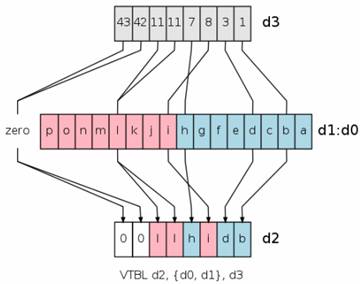
ARM和NEON指令 very nice
在移动平台上进行一些复杂算法的开发,一般需要用到指令集来进行加速。目前在移动上使用最多的是ARM芯片。 ARM是微处理器行业的一家知名企业,其芯片结构有:armv5、armv6、armv7和armv8系列。芯片类型有:arm7、arm9、arm11、cortex系列。指令集有:armv5、armv6和neon指令。关于ARM到知识参考:http://baike.baidu.com/view/11

从0开始学习NEON(1)
1、前言 在上个博客中对NEON有了基础的了解,本文将针对一个图像下采样的例子对NEON进行学习。 学习链接:CPU优化技术 - NEON 开发进阶 上文链接:https://blog.csdn.net/weixin_42108183/article/details/136412104 2、第一个例子 现在有一张图片,需要对UV通道的数据进行下采样,对于同种类型的数据,相邻的4个元素求和