本文主要是介绍性能优化(CPU优化技术)-NEON指令详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文来自ARM SIMD 指令集:NEON 简介
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
ARM SIMD 指令集:NEON 简介
一、NEON 简介
1.1、NEON 简介
1.2、NEON 使用方式
1.3、编译器自动向量化的编译选项
1.3.1 Arm Compiler 中使能自动向量化
1.3.2 LLVM-clang 中使能自动向量化
1.3.3 GCC 中使能自动向量化
1.4、NEON intrisics 指令在x86平台的仿真
二、NEON 数据类型和指令类型
2.1、NEON 数据类型
2.2、 NEON 指令类型
三、NEON 指令简介
3.1、数据读取指令(内存数据加载到寄存器)
3.2、数据存储指令(寄存器数据回写到内存 )
3.3、数据处理指令
3.3.1 获取寄存器的值
3.3.2 设置寄存器的值
3.3.3 加减乘除运算
3.3.4 逻辑运算
3.3.5 数据类型转换
3.3.6 寄存器数据重排
四、NEON 进阶
五、参考连接
ARM SIMD 指令集:NEON 简介
-
- 一、NEON 简介
-
- 1.1、NEON 简介
- 1.2、NEON 使用方式
- 1.3、编译器自动向量化的编译选项
-
- 1.3.1 Arm Compiler 中使能自动向量化
- 1.3.2 LLVM-clang 中使能自动向量化
- 1.3.3 GCC 中使能自动向量化
- 1.4、NEON intrisics 指令在x86平台的仿真
- 二、NEON 数据类型和指令类型
-
- 2.1、NEON 数据类型
- 2.2、 NEON 指令类型
- 三、NEON 指令简介
-
- 3.1、数据读取指令(内存数据加载到寄存器)
- 3.2、数据存储指令(寄存器数据回写到内存 )
- 3.3、数据处理指令
-
- 3.3.1 获取寄存器的值
- 3.3.2 设置寄存器的值
- 3.3.3 加减乘除运算
- 3.3.4 逻辑运算
- 3.3.5 数据类型转换
- 3.3.6 寄存器数据重排
- 四、NEON 进阶
- 五、参考连接
一、NEON 简介
1.1、NEON 简介
- SIMD,即 single instruction multiple data,单指令流多数据流,也就是说一次运算指令可以执行多个数据流,从而提高程序的运算速度,实质是通过
数据并行来提高执行效率- ARM NEON 是 ARM 平台下的 SIMD 指令集,利用好这些指令可以使程序获得很大的速度提升。不过对很多人来说,直接利用汇编指令优化代码难度较大,这时就可以利用 ARM NEON intrinsic 指令,它是底层汇编指令的封装,不需要用户考虑底层寄存器的分配,但同时又可以达到原始汇编指令的性能。
- NEON 是一种 128 位的 SIMD 扩展指令集,由 ARMv7 引入,在 ARMv8 对其功能进行了扩展(支持向量化运算),支持包括加法、乘法、比较、移位、绝对值 、极大极小极值运算、保存和加载指令等运算
- ARM 架构下的下一代 SIMD 指令集为
SVE(Scalable Vector Extension,可扩展矢量指令),支持可变矢量长度编程,SVE 指令集的矢量寄存器的长度最小支持 128 位,最大可以支持 2048 位,以 128 位为增量- ARM NEON 技术的核心是 NEON 单元,主要由四个模块组成:
NEON 寄存器文件、整型执行流水线、单精度浮点执行流水线和数据加载存储和重排流水线- ARM 基本数据类型有三种:字节(
Byte,8bit)、半字(Halfword,16bit)、字(Word,32bit)- 新的 Armv8a 架构有
32个 128bit 向量寄存器,老的 ArmV7a 架构有32个 64bit(可当作16个128bit)向量寄存器,被用来存放向量数据,每个向量元素的类型必须相同,根据处理元素的大小可以划分为2/4/8/16个通道
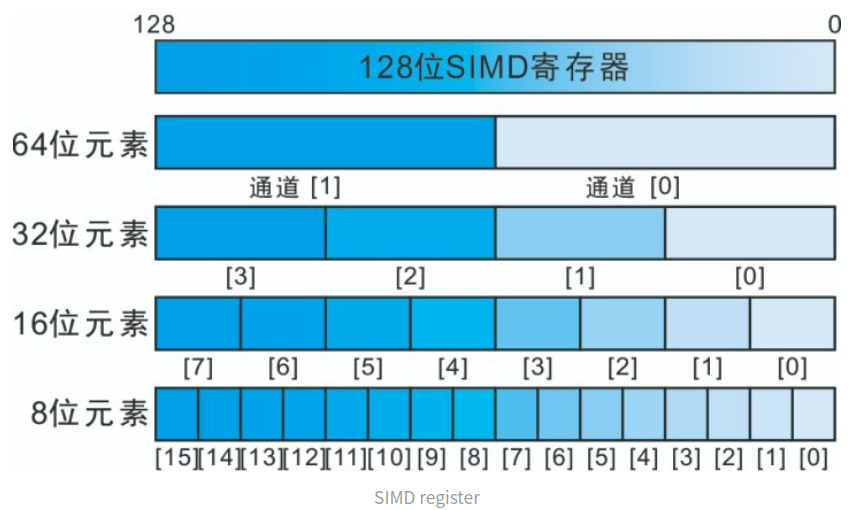
1.2、NEON 使用方式
- ARM 平台提供了四种使用 NEON 技术的方式,分别为 NEON 内嵌函数(
intrinsics)、NEON 汇编、NEON 开源库和编译器自动向量化- NEON 内嵌函数:类似于普通函数调用,简单易维护,编译器负责将 NEON 指令替换成汇编语言的复杂任务,主要包括寄
存器分配和代码调度以及指令集重排,来达到获取最高性能的目标 - NEON 汇编:汇编语言相对晦涩难懂,移植较难、不便于维护,但其
效率最高 - NEON 开源库:如 Ne10、OpenMAX、ffmpeg、Eigen3 和 Math-neon 等
- 编译器自动向量化:目前大多数编译器都具有自动向量化的功能,将 C/C++ 代码自动替换为 SIMD 指令。从编译技术上来说,自动向量化一般包含两部分:循环向量化(
Loop vectorization)和超字并行向量化(SLP,Superword-Level Parallelism vectorization,又称 Basic block vectorization)- 循环向量化:将循环进行展开,增加循环中的执行代码来减少循环次数
- SLP 向量化:编译器将多个标量运算绑定到一起,使其成为向量运算
- NEON 内嵌函数:类似于普通函数调用,简单易维护,编译器负责将 NEON 指令替换成汇编语言的复杂任务,主要包括寄
- 编写代码时要加上头文件:
#include <arm_neon.h>,编译时要加上相应的 编译选项:LOCAL_CFLAGS += -mcpu=cortex-a53 -mfloat-abi=softfp -mfpu=neon-vfpv4 -O3
1.3、编译器自动向量化的编译选项
- 目前支持自动向量化的编译器有 Arm Compiler 6、Arm C/C++ Compiler、LLVM-clang 以及 GCC,这几种编译器间的相互关系如下表所示:

1.3.1 Arm Compiler 中使能自动向量化
-
下文中 Arm Compiler 6 与 Arm C/C++ Compiler 使用
armclang统称,armclang 使能自动向量化配置信息如下表所示: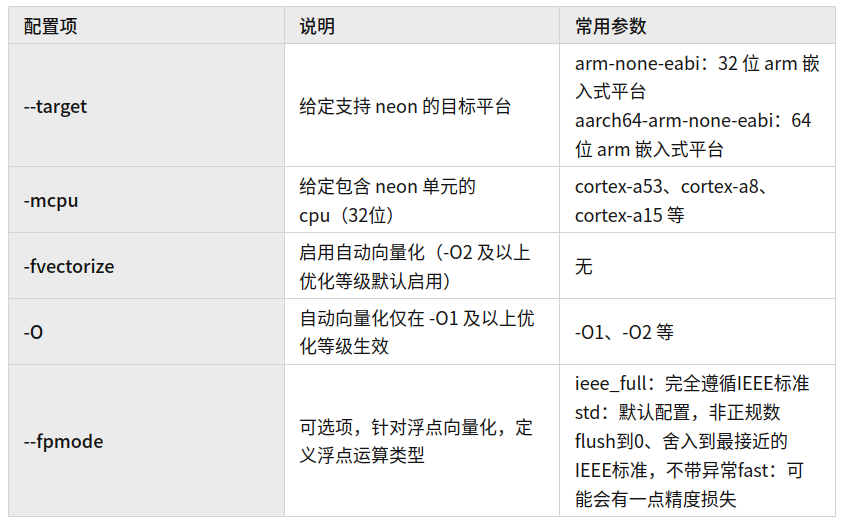
-
armclang 实现自动向量化示例:
# AArch32
armclang --target=arm-none-eabi -mcpu=cortex-a53 -O1 -fvectorize main.c# AArch64,O2 及以上优化等级默认启用自动向量化 -fvectorize
armclang --target=aarch64-arm-none-eabi -O2 main.c
1.3.2 LLVM-clang 中使能自动向量化
- Android NDK 从 r13 开始以
clang为默认编译器,使用 Android NDK 工具链使能自动向量化配置参数如下表所示:
- 在 CMake 中配置自动向量化方式如下:
# method 1
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O1 -fvectorize")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O1 -fvectorize")# method 2
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O2")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O2")
1.3.3 GCC 中使能自动向量化
- 在 gcc 中使能自动向量化配置参数如下:
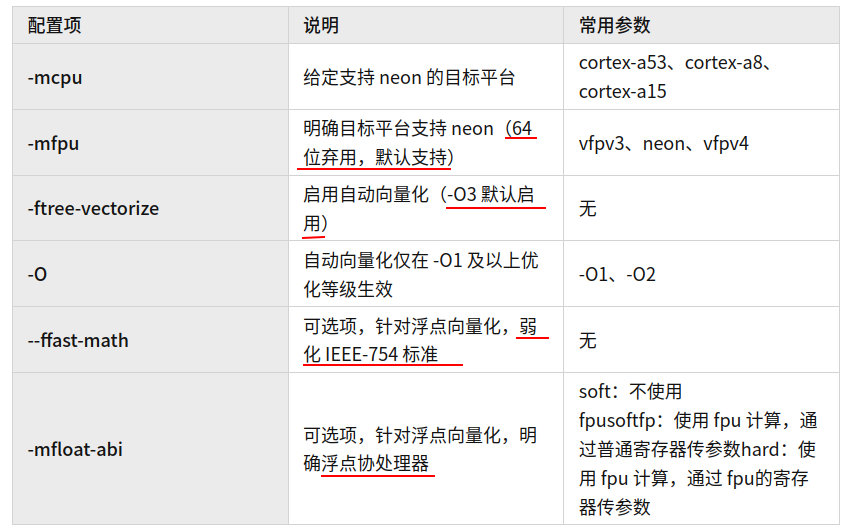
-
在不明确配置
-mcpu的情况下,编译器将使用默认配置(取决于编译工具链时的选项设置)进行编译,通常情况下-mfpu和-mcpu的配置存在关联性,对应关系如下: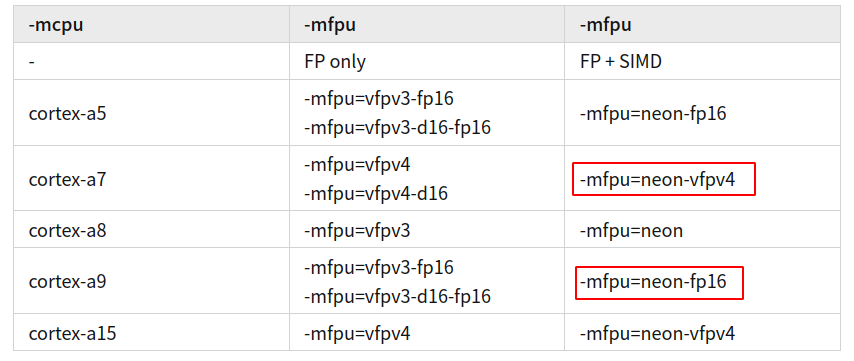
-
gcc 中实现自动向量化的编译配置如下:
# AArch32
arm-none-linux-gnueabihf-gcc -mcpu=cortex-a53 -mfpu=neon -ftree-vectorize -O2 main.c# AArch64
aarch64-none-linux-gnu-gcc -mcpu=cortex-a53 -ftree-vectorize -O2 main.c
1.4、NEON intrisics 指令在x86平台的仿真
- 为了便于 NEON 指令从 ARM 平台移植到 x86 平台使用,Intel 提供了一套转化接口 NEON2SSE,用于将 NEON 内联函数转化为
Intel SIMD(SSE)内联函数,大部分 x86 平台 C/C++编译器均支持 SSE,因此只需下载并包含接口头文件NEON_2_SSE.h,即可在x86平台调试 NEON 指令代码 - x86 上模拟实现可参考:
- NEON_2_SSE.h 是个好东西
- https://github.com/intel/ARM_NEON_2_x86_SSE
- https://github.com/christophe-lyon/arm-neon-tests
# 1、编程时加上头文件
#include "NEON_2_SSE.h"# 2、编译时加上如下编译选项(debug)
# gdb 调试时出现value optimized out 解决方法如下:
# 由于 gcc 在编译过程中默认使用 -O2 优化选项,希望进行单步跟踪调试时,应使用 -O0 选项
set(CMAKE_C_FLAGS "-w -mfma -mavx512f -msse4 -msse4.1 -msse4.2 -O0")
set(CMAKE_CXX_FLAGS "-w -mfma -mavx512f -msse4 -msse4.1 -msse4.2 -O0")
二、NEON 数据类型和指令类型
2.1、NEON 数据类型
- NEON 向量数据类型是根据以下模式命名的:
<type><size>x<number_of_lanes>_t,eg:int8x16_t是一个16 通道 的向量,每个通道包含一个有符号 8 位整数 - NEON 还提供了数组向量数据类型,命名模式如下:
<type><size>x<number of lanes>x<length of array>_t,eg:int8x16x4_t 是一个长度为 4 的数组,每一个数据的类型为 int8x16_t
struct int8x16x4_t {int8x16_t val[4]; // 数组元素的长度范围 2 ~ 4};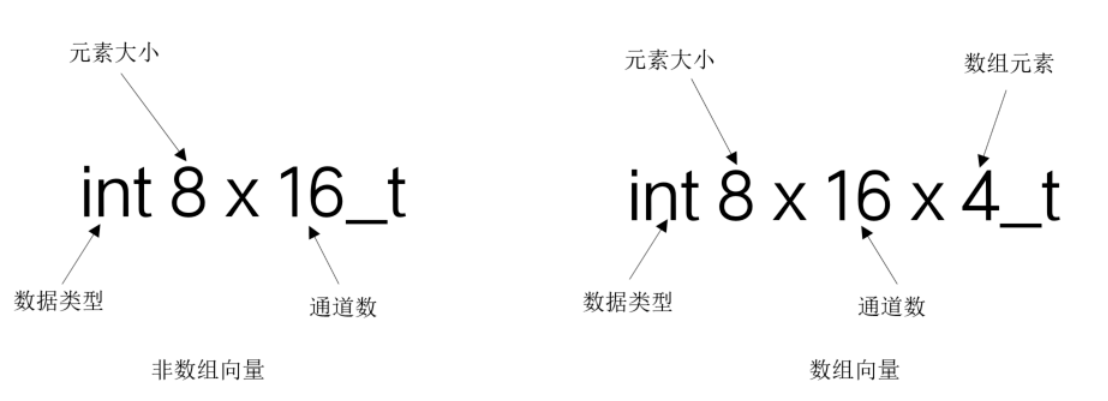
- 下表列出了 16 个
D 寄存器上的向量数据类型及 16 个Q 寄存器上的向量数据类型 - D 寄存器一次能处理
8个u8数据,Q 寄存器一次能处理16个u8数据
D寄存器(64-bit) | Q寄存器(128-bit) |
|---|---|
int8x8_t | int8x16_t |
| int16x4_t | int16x8_t |
| int32x2_t | int32x4_t |
| int64x1_t | int64x2_t |
uint8x8_t | uint8x16_t |
| uint16x4_t | uint16x8_t |
| uint32x2_t | uint32x4_t |
| uint64x1_t | uint64x2_t |
| float16x4_t | float16x8_t |
float32x2_t | float32x4_t |
| poly8x8_t | poly8x16_t |
| poly16x4_t | poly16x8_t |
2.2、 NEON 指令类型
NEON指令的函数名组成格式:
v<mod><opname><shape><flags>_<type>,逐元素进行操作
v:vector 的缩写,表示向量mod:
q:表示饱和计算,int8x8_t vqadd_s8(int8x8_t a, int8x8_t b); // a 加 b 的结果做饱和计算h:表示折半计算,int8x8_t vhsub_s8(int8x8_t a, int8x8_t b); // a 减 b 的结果右移一位d:表示加倍计算,int32x4_t vqdmull_s16(int16x4_t a, int16x4_t b); // a 乘 b 的结果扩大一倍, 最后做饱和操作r:表示舍入计算,int8x8_t vrhadd_s8(int8x8_t a, int8x8_t b); // 将 a 与 b 的和减半,同时做 rounding 操作, 每个通道可以表达为: (ai + bi + 1) >> 1p:表示 pairwise 计算,int8x8_t vpadd_s8(int8x8_t a, int8x8_t b); // 将 a, b 向量的相邻数据进行两两和操作opname:表示具体操作,比如 add,sub 等shape:
l:表示 long,输出向量的元素长度是输入长度的 2 倍,uint16x8_t vaddl_u8(uint8x8_t a, uint8x8_t b);w:表示 wide,第一个输入向量和输出向量类型一样,且是第二个输入向量元素长度的 2 倍,uint16x8_t vsubw_u8(uint16x8_t a, uint8x8_t b);n:表示 narrow,输出向量的元素长度是输入长度的 1/2 倍,uint32x2_t vmovn_u64(uint64x2_t a);_high:AArch64专用,而且和 l/n 配合使用,当使用 l(Long) 时,表示输入向量只有高 64bit 有效;当使用 n(Narrow) 时,表示输出只有高 64bit 有效,int16x8_t vsubl_high_s8(int8x16_t a, int8x16_t b); // a 和 b 只有高 64bit 参与运算_n:表示有标量参与向量计算,int8x8_t vshr_n_s8(int8x8_t a, const int n); // 向量 a 中的每个元素右移 n 位_lane: 指定向量中某个通道参与向量计算,int16x4_t vmul_lane_s16(int16x4_t a, int16x4_t v, const int lane); // 取向量 v 中下标为 lane 的元素与向量 a 做乘法计算flags:q表示 quad word,四字,指定函数对 128 位Q寄存器进行操作,不带 q 则对 64 位D寄存器进行操作type:表示函数的参数类型(u8/16/32/64、s8/16/32/64、f16/32等)
- 正常指令:
- 生成大小相同且类型通常与操作数向量相同的结果向量,结果大于 2 n 2^n 2n 的除以 2 n 2^n 2n 取余数,结果小于 0 的加上 2 n 2^n 2n
- eg:
int8x8_t vadd_s8 (int8x8_t __a, int8x8_t __b)
- 饱和指令:
- 当超过数据类型指定的范围则自动限制在该范围内(结果大于 2 n − 1 2^n - 1 2n−1 的截断到 2 n − 1 2^n - 1 2n−1 ,结果小于 0 的截断到 0 ),函数中用
q来标记(在v之后) - eg:
int8x8_t vqsub_s8 (int8x8_t __a, int8x8_t __b)
- 当超过数据类型指定的范围则自动限制在该范围内(结果大于 2 n − 1 2^n - 1 2n−1 的截断到 2 n − 1 2^n - 1 2n−1 ,结果小于 0 的截断到 0 ),函数中用
- 长指令:
- 对双字向量操作数执行运算,生成四字向量的结果,所生成的元素一般是操作数元素宽度的两倍,并属于同一类型,函数中用
l来标记,结果大于 2 n 2^n 2n 的减去 2 n 2^n 2n (一般不会),结果小于 0 的加上 2 n 2^n 2n (可能出现) - eg:
int16x8_t vaddl_s8 (int8x8_t __a, int8x8_t __b)
- 对双字向量操作数执行运算,生成四字向量的结果,所生成的元素一般是操作数元素宽度的两倍,并属于同一类型,函数中用
- 宽指令:
- 一个双字向量操作数和一个四字向量操作数执行运算,生成四字向量结果。所生成的元素和第一个操作数的元素是第二个操作数元素宽度的两倍,函数中用
w来标记 - eg:
int16x8_t vaddw_s8 (int16x8_t __a, int8x8_t __b)
- 一个双字向量操作数和一个四字向量操作数执行运算,生成四字向量结果。所生成的元素和第一个操作数的元素是第二个操作数元素宽度的两倍,函数中用
- 窄指令:
- 四字向量操作数执行运算,并生成双字向量结果,所生成的元素一般是操作数元素宽度的一半,函数中用
hn来标记 - eg:
int8x8_t vaddhn_s16 (int16x8_t __a, int16x8_t __b)
- 四字向量操作数执行运算,并生成双字向量结果,所生成的元素一般是操作数元素宽度的一半,函数中用
三、NEON 指令简介
- NEON 指令执行流程如下:

// 用 float 类型的 val 值,去初始化寄存器,值为 val
float32x4_t vec = vdupq_n_f32(val);
3.1、数据读取指令(内存数据加载到寄存器)
- 顺序读取
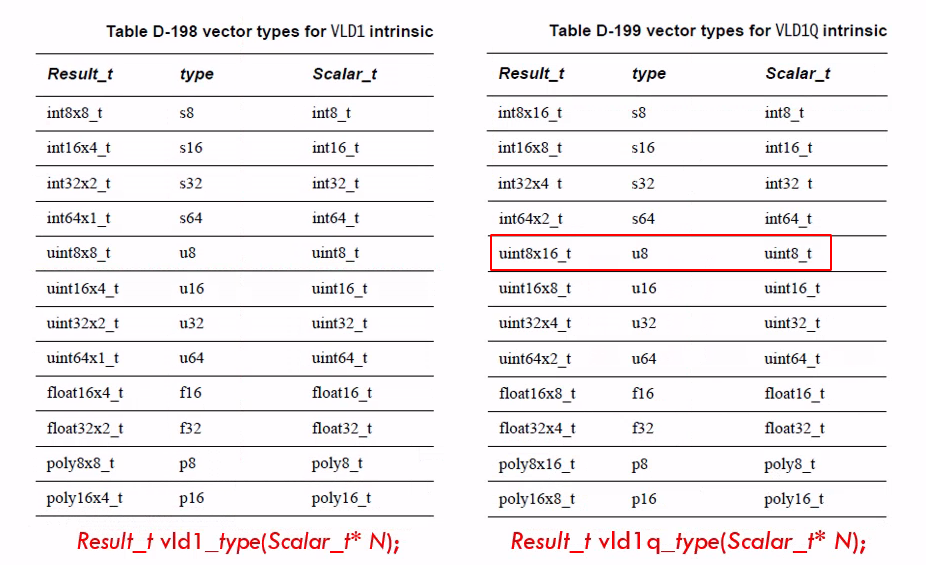
// vld1 -> loads a vector from memory
float32x2_t temp = vld1_f32(const float32_t * __a); // load 2 float32 64-bit
float32x4_t temp = vld1q_f32(const float32_t * __a); // load 4 float32 128-bit
- 交织读取
// vld2 -> loads 2 vector from memory,vld3 vld4 the same as vld2
// 交叉存放: a1 a2 a3 a4 -> temp.val[0]:a1 a3 ; temp.val[1]:a2 a4
float32x2x2_t temp = vld2_f32 (const float32_t * __a); // load 4 float32 64-bit
float32x4x2_t temp = vld2q_f32 (const float32_t * __a); // load 8 float32 128-bit
3.2、数据存储指令(寄存器数据回写到内存 )
- 顺序存储
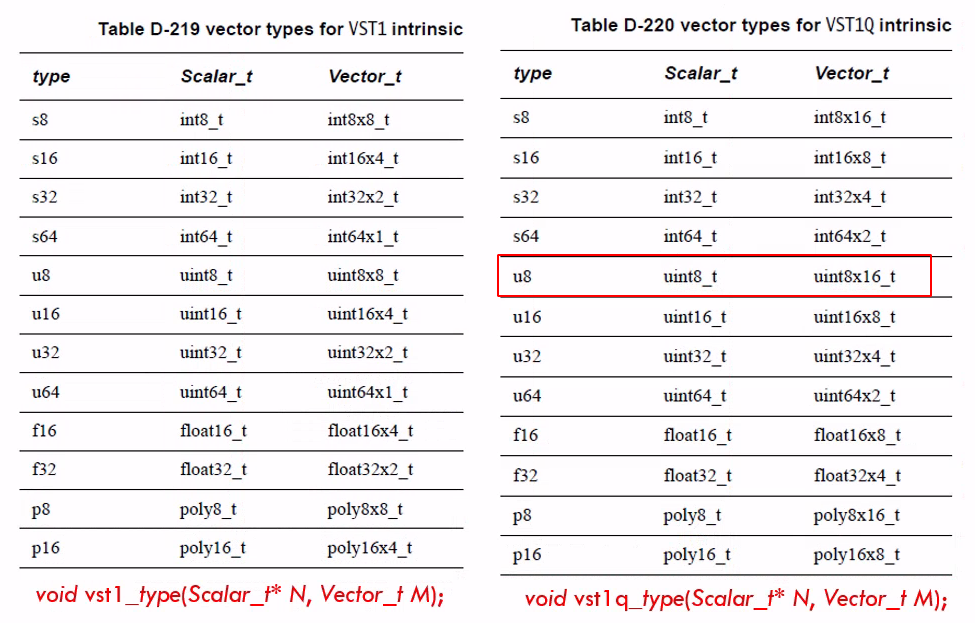
// vst1 -> stores a vector into memory
void vst1_f32 (float32_t * ptr, float32x2_t temp); // store 2 float32 64-bit
void vst1q_f32 (float32_t * ptr, float32x4_t temp); // store 4 float32 64-bit
- 交织存储
// vst2 -> stores 2 vector into memory,It interleaves the 2 vectors into memory.
void vst2_f32 (float32_t * ptr, float32x2x2_t temp); // store 4 float32 64-bit
void vst2q_f32 (float32_t * ptr, float32x4x2_t temp); // store 8 float32 64-bit
3.3、数据处理指令
3.3.1 获取寄存器的值
// 从寄存器中访问具体元素:extract a single lane (element) from a vector
uint8_t vgetq_lane_u8(uint8x16_t vec, __constrange(0,15) int lane);
3.3.2 设置寄存器的值
// 设置寄存器具体元素值:set a single lane (element) within a vector.
// 注意:返回值要用参数中的 vec 寄存器来接收
uint16x8_t vsetq_lane_u16(uint16_t value, uint16x8_t vec, __constrange(0,7) int lane);
eg: vec = vsetq_lane_u16(111, vec, 5);// 设置寄存器所有元素的值(以某一个通道的值):Set all lanes to the value of one lane of a vector
uint8x8_t vdup_lane_u8(uint8x8_t vec, __constrange(0,7) int lane)
eg: vec = vdup_lane_u8(vec, 5); // 所有元素都设置成第五通道的值// 设置寄存器所有元素的值(以某一个固定的值)
uint8x16_t vmovq_n_u8(uint8_t value);
eg: uint8x16_t vec = vmovq_n_u8(5); // 所有元素都设置成 5
3.3.3 加减乘除运算
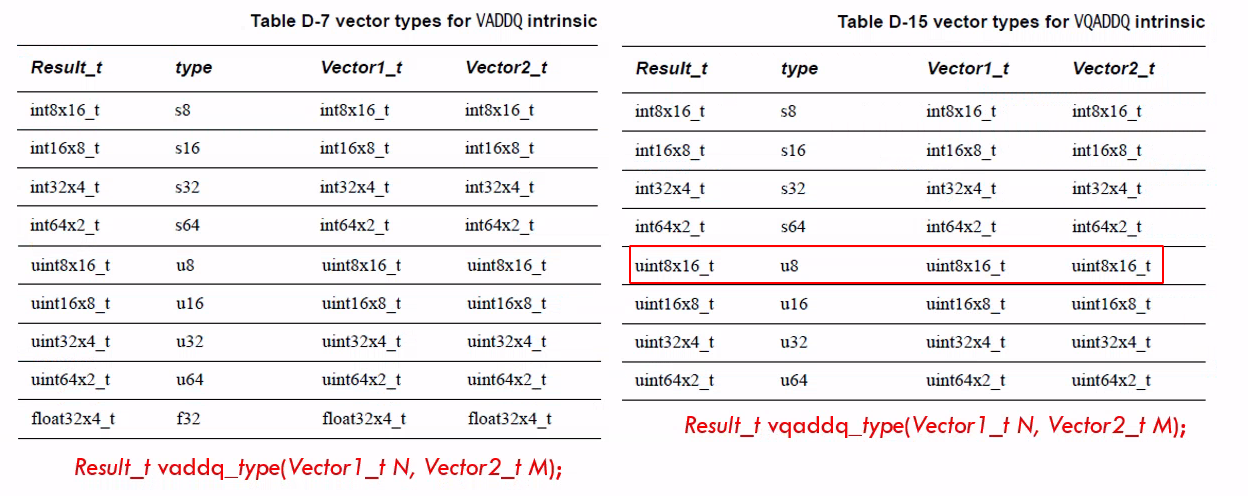
- 加法
// 正常指令加法运算
int32x2_t vadd_s32(int32x2_t __a, int32x2_t __b);// 饱和指令加法,结果超出元素类型的最大值时,元素就取最大值;小于元素类型的最小值时,元素就取最小值
int32x2_t vqadd_s32(int32x2_t __a, int32x2_t __b);// 长指令加法运算,为了防止溢出,输出向量长度是输入的两倍
int64x2_t vaddl_s32(int32x2_t __a, int32x2_t __b);// 向量半加:相加结果再除 2(向下取整),ri = (ai + bi) >> 1:
int32x2_t vhadd_s32(int32x2_t __a, int32x2_t __b);// 向量舍入半加:相加结果再除 2,ri = (ai + bi + 1) >> 1:
int32x2_t vrhadd_s32(int32x2_t __a, int32x2_t __b);// pairwise add,r0 = a0 + a1, ...,r3 = a6 + a7, r4 = b0 + b1, ...,r7 = b6 + b7
int8x8_t vpadd_s8(int8x8_t __a, int8x8_t __b);// long pairwise add, r0 = a0 + a1, ..., r3 = a6 + a7
int16x4_t vpaddl_s8(int8x8_t __a); // Long pairwise add and accumulate,r0 = a0 + (b0 + b1), ..., r3 = a3 + (b6 + b7)
int16x4_t vpadal_s8(int16x4_t __a, int8x8_t __b);// 宽指令加法运算,第一个输入向量的长度是第二个输入向量长度的两倍
int64x2_t vaddw_s32(int64x2_t __a, int32x2_t __b);// 窄指令加法,结果的类型大小是输入类型大小的一半,待验证???
int16x4_t vaddhn_s32(int32x4_t __a, int32x4_t __b);
- 减法
// 正常减法运算
int32x4_t vsubq_s32(int32x4_t __a, int32x4_t __b);// 饱和指令减法,结果超出元素类型的最大值时,元素就取最大值
int32x2_t vqsub_s32 (int32x2_t __a, int32x2_t __b);// 长指令减法运算,为了防止溢出
int64x2_t vsubl_s32(int32x2_t __a, int32x2_t __b);// 向量半减:相减结果再除 2,ri = (ai - bi) >> 1
int32x2_t vhsub_s32 (int32x2_t __a, int32x2_t __b);// 宽指令减法运算,第一个元素宽度大于第二个
int64x2_t vsubw_s32(int64x2_t __a, int32x2_t __b);// 窄指令减法,结果的类型大小是输入类型大小的一半
int16x4_t vsubhn_s32 (int32x4_t __a, int32x4_t __b);

- 乘法
// ri = ai * bi,正常指令,逐元素相乘
int32x2_t vmul_s32 (int32x2_t __a, int32x2_t __b);// ri = ai * bi, 长指令, 为了防止溢出
int64x2_t vmull_s32 (int32x2_t __a, int32x2_t __b)// ri = ai * b,有标量参与向量运算
int32x2_t vmul_n_s32 (int32x2_t __a, int32_t __b);// ri = ai * b, 长指令, 为了防止溢出
int64x2_t vmull_n_s32 (int32x2_t __a, int32_t __b);// ri = ai * b[c]
int32x2_t vmul_lane_s32 (int32x2_t __a, int32x2_t __b, const int __c);// ri = ai * b[c], 长指令,为了防止溢出
int64x2_t vmull_lane_s32 (int32x2_t __a, int32x2_t __b, const int __c);// ri = sat(ai * bi) 饱和指令,当结果溢出时,取饱和值
int32x2_t vqdmulh_s32 (int32x2_t __a, int32x2_t __b);
- 乘加
// ri = ai + bi * ci,正常指令
int32x2_t vmla_s32 (int32x2_t __a, int32x2_t __b, int32x2_t __c)// ri = ai + bi * ci,长指令
int64x2_t vmlal_s32 (int64x2_t __a, int32x2_t __b, int32x2_t __c);// ri = ai + bi * c,正常指令,乘以标量
int32x2_t vmla_n_s32 (int32x2_t __a, int32x2_t __b, int32_t __c);// ri = ai + bi * c,长指令,乘以标量
int64x2_t vmlal_n_s32 (int64x2_t __a, int32x2_t __b, int32_t __c);// ri = ai + bi * c[d]
int32x2_t vmla_lane_s32 (int32x2_t __a, int32x2_t __b, int32x2_t __c, const int __d);// ri = ai + bi * c[d] 长指令
int64x2_t vmlal_lane_s32 (int64x2_t __a, int32x2_t __b, int32x2_t __c, const int __d);// ri = ai + bi * ci 在加法之前,bi、ci相乘的结果不会被四舍五入
float32x2_t vfma_f32 (float32x2_t __a, float32x2_t __b, float32x2_t __c)// ri = sat(ai + bi * c)
int64x2_t vqdmlal_n_s32 (int64x2_t __a, int32x2_t __b, int32_t __c);// ri = sat(ai + bi * c[d])
int64x2_t vqdmlal_lane_s32 (int64x2_t __a, int32x2_t __b, int32x2_t __c, const int __d);
- 乘减
// ri = ai - bi * ci
int32x2_t vmls_s32 (int32x2_t __a, int32x2_t __b, int32x2_t __c);// ri = ai - bi * ci 长指令,正常指令
int64x2_t vmlsl_s32 (int64x2_t __a, int32x2_t __b, int32x2_t __c);// ri = ai - bi * c,正常指令,乘以标量
int32x2_t vmls_n_s32 (int32x2_t __a, int32x2_t __b, int32_t __c);// ri = ai - bi * c,长指令,乘以标量
int64x2_t vmlsl_n_s32 (int64x2_t __a, int32x2_t __b, int32_t __c);// ri = ai - bi * c[d]
int32x2_t vmls_lane_s32 (int32x2_t __a, int32x2_t __b, int32x2_t __c, const int __d);// ri = ai - bi * c[d] 长指令
int64x2_t vmlsl_lane_s32 (int64x2_t __a, int32x2_t __b, int32x2_t __c, const int __d); // ri = ai - bi * ci 在减法之前,bi、ci相乘的结果不会被四舍五入
float32x2_t vfms_f32 (float32x2_t __a, float32x2_t __b, float32x2_t __c);// ri = sat(ai - bi * c)
int64x2_t vqdmlsl_n_s32 (int64x2_t __a, int32x2_t __b, int32_t __c);// ri = sat(ai - bi * c[d])
int64x2_t vqdmlsl_lane_s32 (int64x2_t __a, int32x2_t __b, int32x2_t __c, const int __d);
- 倒数/平方根
// finds an approximate reciprocal of each element in a vector
float32x2_t vrecpe_f32 (float32x2_t __a);
// 注:vrecpe_type 计算倒数能保证千分之一左右的精度,如 1.0 的倒数为 0.998047
// 执行完如下语句后能提高百万分之一精度
// float32x4_t recip = vrecpeq_f32(src); 此时能达到千分之一左右的精度,如 1.0 的倒数为 0.998047
// recip = vmulq_f32 (vrecpsq_f32 (src, rec), rec); 执行后能达到百万分之一左右的精度,如1.0的倒数为0.999996
// recip = vmulq_f32 (vrecpsq_f32 (src, rec), rec); 再次执行后能基本能达到完全精度,如1.0的倒数为1.000000// performs a Newton-Raphson step for finding the reciprocal
float32x2_t vrecps_f32 (float32x2_t a, float32x2_t b);
float32x4_t vrecpsq_f32(float32x4_t a, float32x4_t b);// 近似平方根
float32x2_t vrsqrts_f32(float32x2_t a, float32x2_t b);
float32x4_t vrsqrtsq_f32(float32x4_t a, float32x4_t b);
- 取负
// vneg -> ri = -ai
int32x2_t vneg_s32 (int32x2_t __a);
3.3.4 逻辑运算
- 取整
/*--1、to nearest, ties to even--*/
float32x2_t vrndn_f32 (float32x2_t __a); /*--2、to nearest, ties away from zero--*/
float32x2_t vrnda_f32 (float32x2_t __a); /*--3、towards +Inf--*/
float32x2_t vrndp_f32 (float32x2_t __a);/*--4、towards -Inf--*/
float32x2_t vrndm_f32 (float32x2_t __a); /*--5、towards 0--*/
float32x2_t vrnd_f32 (float32x2_t __a);
- 比较运算:注意返回类型为无符号整数类型
// 逻辑比较操作,结果为 true,则该元素的所有 bit 位被设置为 1;结果为 false,则该元素的所有 bit 位被设置为 0
// 注意返回类型为无符号整数类型// compares equal : vceq -> ri = ai == bi ? 1...1 : 0...0
uint32x2_t vceq_s32 (int32x2_t __a, int32x2_t __b); // compares greater-than or equal : vcge-> ri = ai >= bi ? 1...1:0...0
uint32x2_t vcge_s32 (int32x2_t __a, int32x2_t __b);// compares less-than or equal : vcle -> ri = ai <= bi ? 1...1:0...0
uint32x2_t vcle_s32 (int32x2_t __a, int32x2_t __b); // compares greater-than : vcgt -> ri = ai > bi ? 1...1:0...0
uint32x2_t vcgt_s32 (int32x2_t __a, int32x2_t __b);// compares less-than : vclt -> ri = ai < bi ? 1...1:0...0
uint32x2_t vclt_s32 (int32x2_t __a, int32x2_t __b);// 向量的绝对值比较
// compares absolute greater-than or equal : vcage -> ri = |ai| >= |bi| ? 1...1:0...0;
uint32x2_t vcage_f32 (float32x2_t __a, float32x2_t __b); // compares absolute less-than or equal : vcale -> ri = |ai| <= |bi| ? 1...1:0...0;
uint32x2_t vcale_f32 (float32x2_t __a, float32x2_t __b);// compares absolute greater-than : vcage -> ri = |ai| > |bi| ? 1...1:0...0;
uint32x2_t vcagt_f32 (float32x2_t __a, float32x2_t __b);// compares absolute less-than : vcalt -> ri = |ai| < |bi| ? 1...1:0...0;
uint32x2_t vcalt_f32 (float32x2_t __a, float32x2_t __b); // 向量与不等于零判断
// vtst -> ri = (ai & bi != 0) ? 1...1:0...0;
uint32x2_t vtst_s32 (int32x2_t __a, int32x2_t __b);
- 绝对值
// Absolute : vabs -> ri = |ai|
int32x2_t vabs_s32 (int32x2_t __a);// Absolute difference : vabd -> ri = |ai - bi|
int32x2_t vabd_s32 (int32x2_t __a, int32x2_t __b);// Absolute difference and accumulate: vaba -> ri = ai + |bi - ci|
int32x2_t vaba_s32 (int32x2_t __a, int32x2_t __b, int32x2_t __c);
- 最大最小值
// vmax -> ri = ai >= bi ? ai : bi; 取向量元素中较大的那一个输出
int32x2_t vmax_s32 (int32x2_t __a, int32x2_t __b);// vmin -> ri = ai >= bi ? bi : ai;
int32x2_t vmin_s32 (int32x2_t __a, int32x2_t __b);// compares adjacent pairs of elements, 获取相邻对的最大值
// vpmax -> vpmax r0 = a0 >= a1 ? a0 : a1, ..., r4 = b0 >= b1 ? b0 : b1, ...;
int32x2_t vpmax_s32 (int32x2_t __a, int32x2_t __b); // compares adjacent pairs of elements, 获取相邻对的最小值
// vpmin -> r0 = a0 >= a1 ? a1 : a0, ..., r4 = b0 >= b1 ? b1 : b0, ...;
int32x2_t vpmin_s32 (int32x2_t __a, int32x2_t __b);
- 移位运算:第二个参数是 int 型,参数均为 vector 的时候可为
负数
// Vector shift left: vshl -> ri = ai << bi,如果 bi 是负数,则变成右移
// The bits shifted out of each element are lost
uint16x8_t vshlq_u16 (uint16x8_t __a, int16x8_t __b); // 正常指令
uint16x8_t vrshlq_u16 (uint16x8_t __a, int16x8_t __b); // 正常指令结果 + 四舍五入
uint16x8_t vqshlq_u16 (uint16x8_t __a, int16x8_t __b); // 饱和指令截断到 (0,65535)
uint16x8_t vqrshlq_u16 (uint16x8_t __a, int16x8_t __b); // 饱和指令截断到 (0,65535) + 四舍五入// Vector shift left by constant: vshlq -> ri = ai << b,如果 b 是负数,则变成右移
// The bits shifted out of the left of each element are lost
uint16x8_t vshlq_n_u16(uint16x8_t a, __constrange(0,15) int b); // 正常指令
uint16x8_t vqshlq_n_u16(uint16x8_t a, __constrange(0,15) int b); // 饱和指令截断到 (0,65535), ri = sat(ai << b);// Vector signed->unsigned rounding narrowing saturating shift right by constant
uint8x8_t vqrshrun_n_s16 (int16x8_t __a, const int __b); // 移位后舍入// Vector shift right:可以通过左移传入负数来实现// Vector shift left by constant: vshrq -> ri = ai >> b
uint16x8_t vshrq_n_u16(uint16x8_t a, __constrange(1,16) int b);
uint16x8_t vrshrq_n_u16(uint16x8_t a, __constrange(1,16) int b);
// 右移累加,vsra -> ri = (ai >> c) + (bi >> c);
uint16x8_t vsraq_n_u16(uint16x8_t a, uint16x8_t b, __constrange(1,16) int c);
uint16x8_t vrsraq_n_u16(uint16x8_t a, uint16x8_t b, __constrange(1,16) int c);/*--Vector shift left and insert: vsli ->; The least significant bit in each element
in the destination vector is unchanged. left shifts each element in the second input
vector by an immediate value, and inserts the results in the destination vector.
It does not affect the lowest n significant bits of the elements in the destination
register. Bits shifted out of the left of each element are lost. The first input vector
holds the elements of the destination vector before the operation is performed.--*/
uint16x8_t vsliq_n_u16 (uint16x8_t __a, uint16x8_t __b, const int __c);/*--Vector shift right and insert: vsri -> ; The two most significant bits in the
destination vector are unchanged. right shifts each element in the second input vector
by an immediate value, and inserts the results in the destination vector. It does not
affect the highest n significant bits of the elements in the destination register.
Bits shifted out of the right of each element are lost.The first input vector holds
the elements of the destination vector before the operation is performed.--*/
uint16x8_t vsriq_n_u16 (uint16x8_t __a, uint16x8_t __b, const int __c);
- 按位运算
// vmvn -> ri = ~ai
int32x2_t vmvn_s32 (int32x2_t __a);// vand -> ri = ai & bi
int32x2_t vand_s32 (int32x2_t __a, int32x2_t __b);// vorr -> ri = ai | bi
int32x2_t vorr_s32 (int32x2_t __a, int32x2_t __b);// veor -> ri = ai ^ bi
int32x2_t veor_s32 (int32x2_t __a, int32x2_t __b);// vbic -> ri = ~ai & bi
int32x2_t vbic_s32 (int32x2_t __a, int32x2_t __b);// vorn -> ri = ai | (~bi)
int32x2_t vorn_s32 (int32x2_t __a, int32x2_t __b);
3.3.5 数据类型转换
// 浮点转定点
// 在 f32 转到 u32 时,是向下取整,且如果是负数,则转换后为 0
uint32x4_t vcvtq_u32_f32(float32x4_t a);
uint32x4_t vcvtq_n_u32_f32(float32x4_t a, __constrange(1,32) int b);// 定点转浮点
float32x4_t vcvtq_f32_u32(uint32x4_t a);
float32x4_t vcvtq_n_f32_u32(uint32x4_t a, __constrange(1,32) int b);// 浮点之间转换
float16x4_t vcvt_f16_f32(float32x4_t a); // VCVT.F16.F32 d0, q0
float32x4_t vcvt_f32_f16(float16x4_t a); // 定点之间转换
int16x8_t vmovl_s8 (int8x8_t a);
int8x8_t vqmovn_s16 (int16x8_t a);
int32x4_t vmovl_s16 (int16x4_t a);
int16x4_t vqmovn_s32 (int32x4_t a);// 向量重新解释类型转换运算:将元素类型为 type2 的 vector 转换为元素类型为 type1 的 vector
// 将向量视为另一类型而不更改其值
float32x2_t vreinterpret_f32_u32 (uint32x2_t __a);
3.3.6 寄存器数据重排
- 按索引重排
// vext -> 提取第二个 vector 的低端的 c 个元素和第一个 vector 的高端的剩下的几个元素
// 如:src1 = {1,2,3,4,5,6,7,8}// src2 = {9,10,11,12,13,14,15,16}// dst = vext_s8(src1,src2,3)时,则dst = {4,5,6,7,8, 9,10,11}
int8x8_t vext_s8 (int8x8_t __a, int8x8_t __b, const int __c);// vtbl1 -> 第二个vector是索引,根据索引去第一个vector(相当于数组)中搜索相应的元素
// 并输出新的vector,超过范围的索引返回的是 0
// 如:src1 = {1,2,3,4,5,6,7,8}
// src2 = {0,0,1,1,2,2,7,8}
// dst = vtbl1_u8(src1,src2)时,则dst = {1,1,2,2,3,3,8,0}
int8x8_t vtbl1_s8 (int8x8_t __a, int8x8_t __b); // vtbl2 -> 数组长度扩大到2个vector
// 如:src.val[0] = {1,2,3,4,5,6,7,8}// src.val[1] = {9,10,11,12,13,14,15,16}// src2 = {0,0,1,1,2,2,8,10}// dst = vtbl2_u8(src,src2)时,则 dst = {1,1,2,2,3,3,9,11}
int8x8_t vtbl2_s8 (int8x8x2_t __a, int8x8_t __b);
//vtbl3 vtbl4类似// vtbx1 -> 与vtbl1功能一样,不过搜索到的元素是用来替换第一个vector中的元素,
// 并输出替换后的新vector,当索引超出范围时,则不替换第一个vector中相应的元素。
int8x8_t vtbx1_s8 (int8x8_t __a, int8x8_t __b, int8x8_t __c);
// vtbx2 vtbx3 vtbx4类似// vbsl -> Bitwise Select, 按位选择,参数为(mask, src1, src2)
// mask 的某个 bit 为1,则选择 src1 中对应的 bit,为 0,则选择 src2 中对应的 bit
int8x8_t vbsl_s8 (uint8x8_t __a, int8x8_t __b, int8x8_t __c);
- 反转向量元素
// vrev -> 将vector中的元素位置反转
// 如:src1 = {1,2,3,4,5,6,7,8}
// dst = vrev64_s8(src1)时,则dst = {8,7,6,5,4,3,2,1}
int8x8_t vrev64_s8 (int8x8_t __a); // 如:src1 = {1,2,3,4,5,6,7,8}
// dst = vrev32_s8(src1)时,则dst = {4,3,2,1,8,7,6,5}
int8x8_t vrev32_s8 (int8x8_t __a); // 如:src1 = {1,2,3,4,5,6,7,8}
// dst = vrev16_s8(src1)时,则dst = {2,1,4,3,6,5,8,7}
int8x8_t vrev16_s8 (int8x8_t __a);
- 转置
// vtrn -> 将两个输入 vector 的元素通过转置生成一个有两个 vector 的矩阵
// 如:src.val[0] = {1,2,3,4,5,6,7,8}
// src.val[1] = {9,10,11,12,13,14,15,16}
// dst = vtrn_u8(src.val[0], src.val[1])时,
// 则 dst.val[0] = {1,9, 3,11,5,13,7,15}
// dst.val[1] = {2,10,4,12,6,14,8,16}
int8x8x2_t vtrn_s8 (int8x8_t __a, int8x8_t __b);
- 交叉
// vzip_type: 将两个输入 vector 的元素通过交叉生成一个有两个vector的矩阵
// 如:src.val[0] = {1,2,3,4,5,6,7,8}
// src.val[1] = {9,10,11,12,13,14,15,16}
// dst = vzip_u8(src.val[0], src.val[1])时,
// 则dst.val[0] = {1,9, 2,10,3,11,4,12}
// dst.val[1] = {5,13,6,14,7,15,8,16}
int8x8x2_t vzip_s8 (int8x8_t __a, int8x8_t __b);
- 反交叉
// vuzp_type: 将两个输入vector的元素通过反交叉生成一个有两个vector的矩阵(通过这个可实现n-way 交织)
// 如:src.val[0] = {1,2,3,4,5,6,7,8}
// src.val[1] = {9,10,11,12,13,14,15,16}
// dst = vuzp_u8(src.val[0], src.val[1])时,
// 则dst.val[0] = {1,3,5,7,9, 11,13,15}
// dst.val[1] = {2,4,6,8,10,12,14,16}
int8x8x2_t vuzp_s8 (int8x8_t __a, int8x8_t __b);
- 组合向量:将两个 64 位向量组合为单个 128 位向量
// vcombine -> 将两个元素类型相同的输入 vector 拼接成一个同类型但大小是输入vector两倍的新vector。
uint8x16_t vcombine_u8(uint8x8_t low, uint8x8_t high);
- 拆分向量:将一个 128 位向量拆分为 2 个 64 位向量
// 从寄存器中获取低半部分元素
uint8x8_t vget_low_u8(uint8x16_t a);// 从寄存器中获取高半部分元素
uint8x8_t vget_high_u8(uint8x16_t a);
四、NEON 进阶
-
CPU优化技术 - NEON 开发进阶:对齐问题解决
-
ARM 官方算子优化:https://github.com/ARM-software/ComputeLibrary
-
NCNN NEON 优化参考:包含常用算子 sigmoid/softmax/relu 等
-
OPENCV 第三方库 carotene NEON 算子优化
-
NEON 使用建议:
- 每次读入的数据尽可能的占满
128位 - 除法使用
乘法进行代替,浮点计算使用定点加移位的方式进行 - 合并算法种的一些系数,
进行化简 算子进行融合,避免内存的多次读写- 使用多核多线程进行加速
- 每次读入的数据尽可能的占满
五、参考连接
1、Neon Intrinsics各函数介绍(*****)
2、https://developer.arm.com/documentation(*****)
3、ARM Neon Intrinsics 学习指北:从入门、进阶到学个通透(*****)
4、ARM NEON 技术之 NEON 基础介绍(***)
5、移动端算法优化(******)
6、利用 ARM NEON intrinsic 优化常用数学运算(***)
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!
这篇关于性能优化(CPU优化技术)-NEON指令详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






