nccl专题

并行计算的艺术:PyTorch中torch.cuda.nccl的多GPU通信精粹
并行计算的艺术:PyTorch中torch.cuda.nccl的多GPU通信精粹 在深度学习领域,模型的规模和复杂性不断增长,单GPU的计算能力已难以满足需求。多GPU并行计算成为提升训练效率的关键。PyTorch作为灵活且强大的深度学习框架,通过torch.cuda.nccl模块提供了对NCCL(NVIDIA Collective Communications Library)的支持,为多GP

英伟达GPU NCCL原理介绍
NVIDIA Collective Communications Library (NCCL) 是一个专为GPU集群设计的高性能通信库,旨在加速分布式深度学习和GPU密集型计算任务。NCCL提供了一系列集体通信原语(collective communication primitives)和点对点通信功能,使得多GPU之间能够高效地同步和交换数据。其核心原理和特性包括: 1. **集体通信原语**
分析解读NCCL_SHM_Disable与NCCL_P2P_Disable
在NVIDIA的NCCL(NVIDIA Collective Communications Library)库中,`NCCL_SHM_Disable` 和 `NCCL_P2P_Disable` 是两个重要的环境变量,它们控制着NCCL在多GPU通信中的行为和使用的通信机制。下面是对这两个环境变量的详细解读: ### NCCL_SHM_Disable - **作用**:当 `NCCL_SHM_D
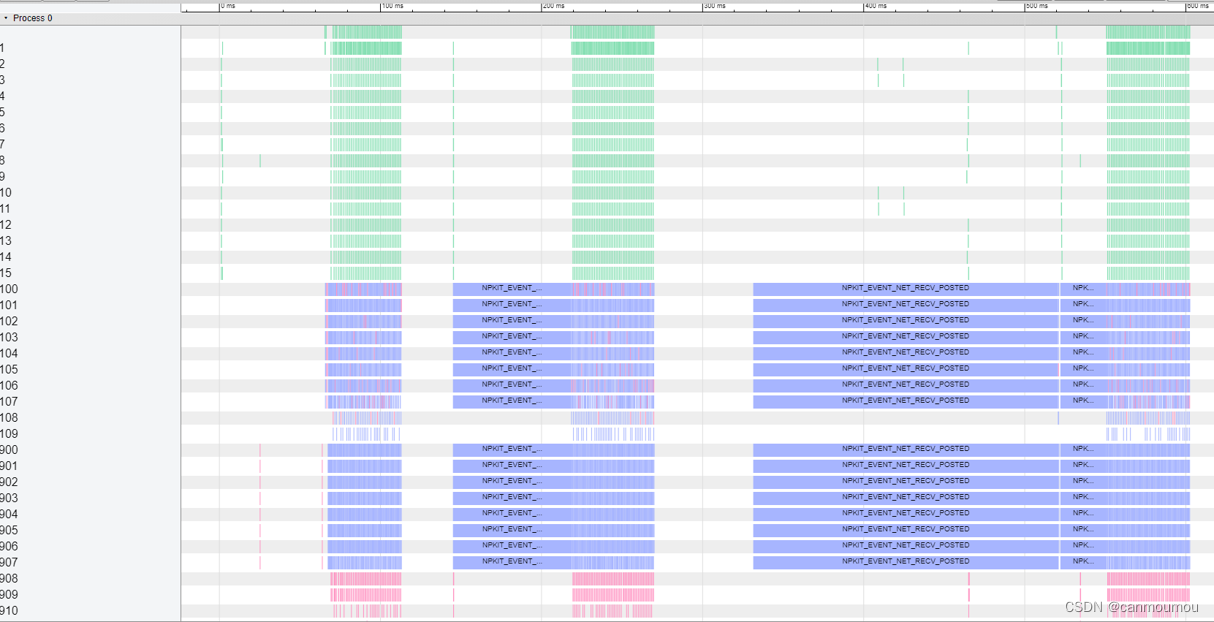
【分布式通信】NPKit,NCCL的Profiling工具
NPKit介绍 NPKit (Networking Profiling Kit) is a profiling framework designed for popular collective communication libraries (CCLs), including Microsoft MSCCL, NVIDIA NCCL and AMD RCCL. It enables user

NVIDIA NCCL 源码学习(十四)- NVLink SHARP
背景 上节我们介绍了IB SHARP的工作原理,进一步的,英伟达在Hopper架构机器中引入了第三代NVSwitch,就像机间IB SHARP一样,机内可以通过NVSwitch执行NVLink SHARP,简称nvls,这节我们会介绍下NVLink SHARP如何工作的。 后续为了方便都是以nranks为2举例的,但值得注意的是nranks为2实际上不会用到nvls。 图搜索 ncclRe

NCCL集合通信算子DEMO及性能测试
NCCL集合通信算子DEMO及性能测试 一.复现代码 以下代码用于测试NCCL算子的性能及正确性 一.复现代码 tee ccl_benchmark.py <<-'EOF'import osimport torchimport argparseimport torch.distributed as distfrom torch.distributed import R
NCCL实现分布式矩阵乘法的CUDA代码
我们以矩阵乘法C=AB,其中A形状为[M,K],B形状为[K,N],C形状为[M,N]举例子,下面的分布式算法我们默认以MPI来切分数据,其中每个进程之前的数据都是私有,进程之间的数据交互使用通信来完成。 A = ( a 0 , 0

分布式训练通信NCCL之Ring-Allreduce详解
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活! 前言 随着Chat GPT、文生图、多模态等模型的发展,海量的训练数据、超大规模的模型给深度学习带来了日益严峻的挑战,因此,经常需要使用多加速卡和多节点来并行化训练深度神经网络。目前
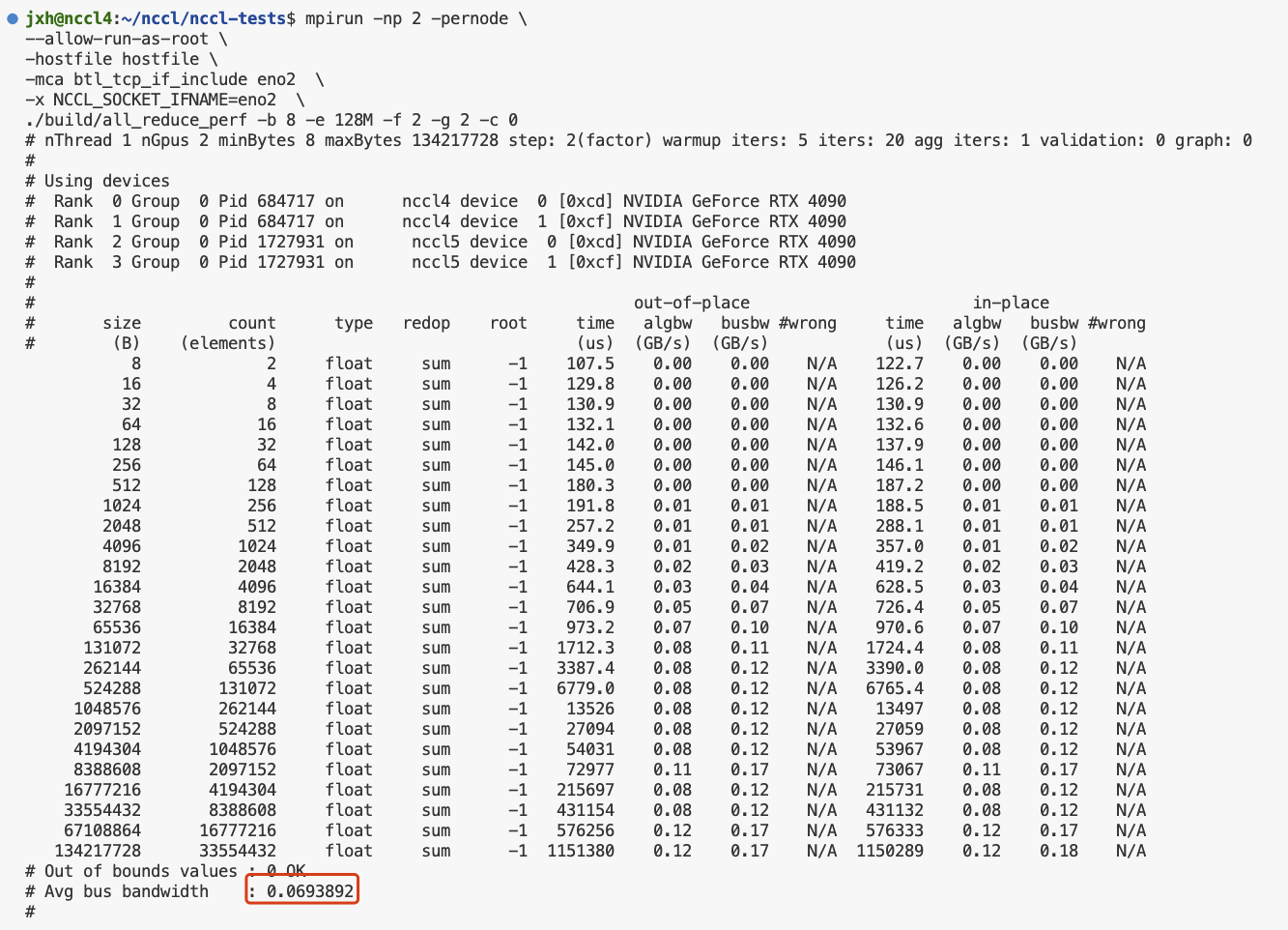
多机多卡运行nccl-tests和channel获取
nccl-tests 环境1. 安装nccl2. 安装openmpi3. 单机测试4. 多机测试mpirun多机多进程多节点运行nccl-testschannel获取 环境 Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)cuda 11.8+ cudnn 8nccl 2.15.1NVIDIA GeForce RTX

Pytorch+NCCL源码编译
目录 环境1. 安装cudnn2. 使用pytorch自带NCCL库进行编译3. 修改NCCL源代码并重新编译后测试,体现出源码更改 环境 Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)cuda 11.8+ cudnn 8python 3.10torch V2.0.1+ nccl 2.14.3NVIDIA GeFo
NCCL源码解析: P2P 连接的建立
文章目录 前言概括详解ncclTransportP2pSetup() 前言 NCCL 源码解析总目录 我尽量在每个函数之前介绍每个函数的作用,建议先不要投入到函数内部实现,先把函数作用搞清楚,有了整体框架,再回归到细节。 习惯: 我的笔记习惯:为了便于快速理解,函数调用关系通过缩进表示,也可能是函数展开,根据情况而定。 如下 // 调用 proxyConnInitNC
NCCL源码解析: proxy 线程
文章目录 前言概括详解1. 用到的变量2. proxy 线程创建2.1 ncclProxyService()2.2 proxyServiceInitOp()2.2 proxyProgressAsync() 4. ncclProxyConnect()4.1 ncclProxyCallBlocking()4.2 ncclPollProxyResponse() 前言 NCCL 源

nvidia nccl安装和测试的实战教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了nvidia nccl安装和测试

nccl cudaLaunch kernel
这次希望看一下,ncclAllReduce( )中的 ncclSum 是如何转换成 对应的 cuda Kernel来被执行到的。 其中,cudaLaunchKernel的参数的数据流如下图所示: 我们需要弄清楚,其中的变量 __thread struct ncclComm* ncclGroupCommHead = nullptr; 是如何关联到fn上的。
分布式训练通信NCCL之Ring-Allreduce详解
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍+点赞👍+评论📝+收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活! 前言 随着Chat GPT、文生图、多模态等模型的发展,海量的训练数据、超大规模的模型给深度学习带来了日益严峻的挑战,因此,经常需要使用多加速卡和多节点来并行化训练深度神经网络。目前
NCCL 实践与体会
1. 介绍 2. NCCL 开启IB/ROCE/的环境变量设置 export NCCL_IB_DISABLE=0;export NCCL_P2P_DISABLE=1;NCCL_SHM_DISABLE=1 NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_4,mlx5_5;sendrecv_perf -b 8 -e 8192M -f 2 -g 4
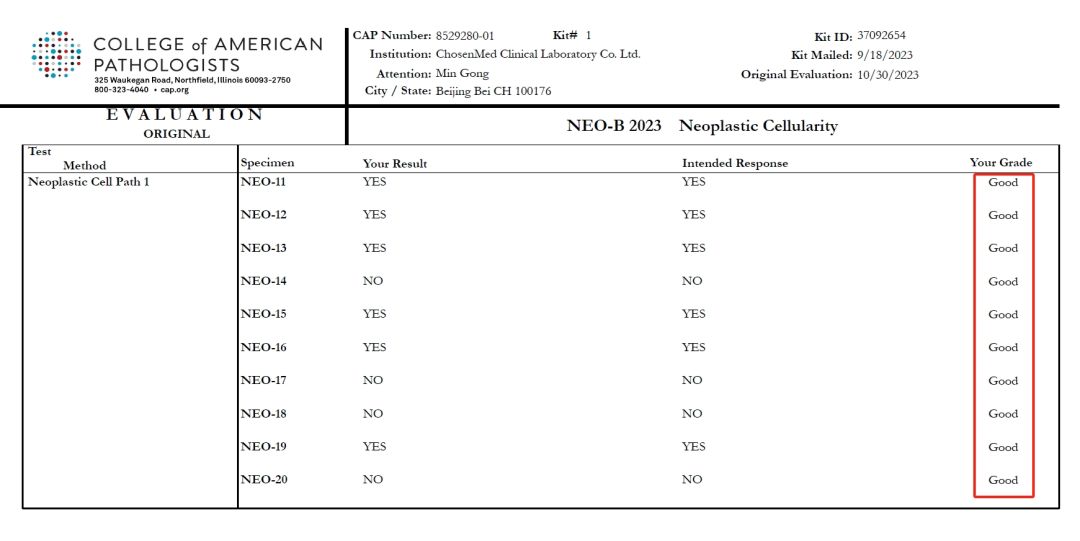
实力验证 | 求臻医学满分通过CAP及NCCL组织的国内外三项室间质评
近日,求臻医学以满分的优异成绩通过了由美国病理学家协会(College of American Pathologists,CAP)组织的NGS−A 2023:Next−Generation Sequencing (NGS) – Germline、NEO-B 2023 Neoplastic Cellularity能力验证项目;同时,北京、杭州两地实验室以双满分完美通过国家卫生健康委临床检验中心(NC
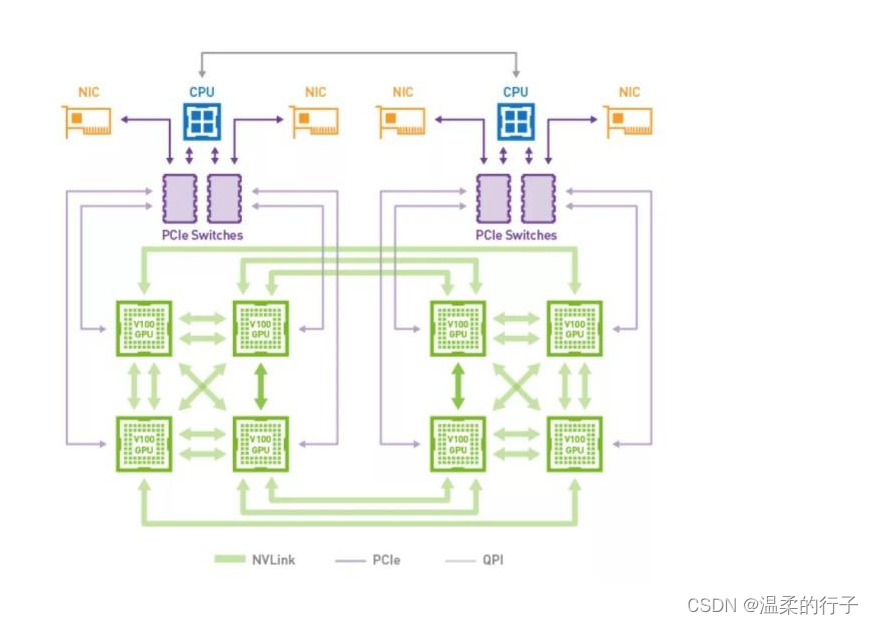
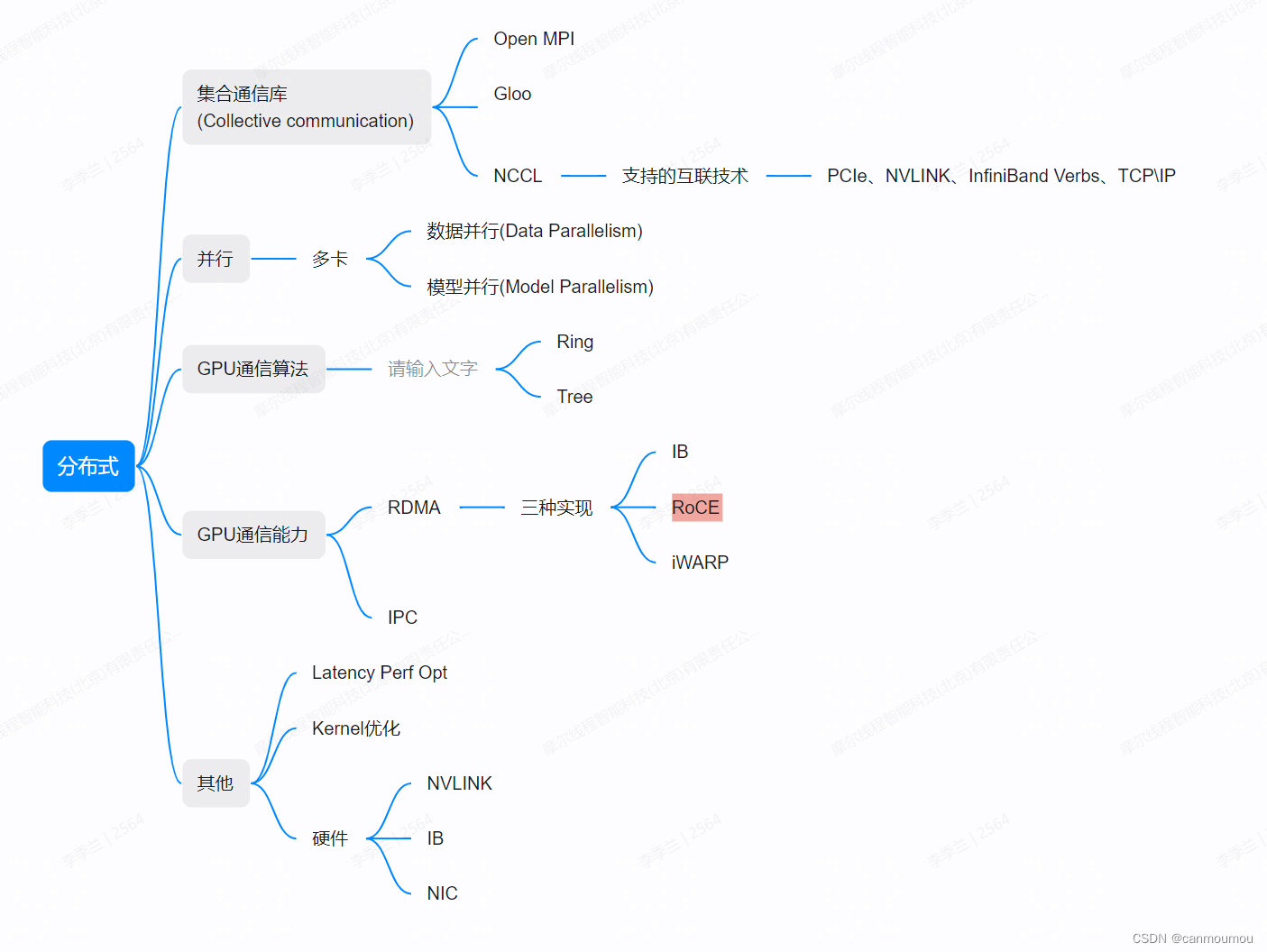
【分布式】入门级NCCL多机并行实践 - 02
# 背景知识 大模型和分布式训练对数据的吞吐量以及并行度都有很高的要求,NCCL就是在这个背景下诞生的。 如果你是一个只会写写Python,调用PyTorch和Horovod的算法萌新,可能对于分布式底层的东西不太了解,在下岗热潮中被主管逼着转变成算子或者通讯库的搬砖工,就会像我一样两眼蒙蔽。因此本文只对自己踩到的坑做一个整理,如果有说错的地方,那就是我说错了。 1. 从PyTorch开始理

RuntimeError: NCCL error in: /opt/ conda/ conda-bld/pytorch 1607370117127/work/ torch/lib/c10d/Proce
1问题 运行pytorch_lightning训练模型时报错如下 RuntimeError: NCCL error in: /opt/ conda/ conda-bld/pytorch 1607370117127/work/torch/lib/c10d/ ProcessGroupNCcL.cpp 784, unhandLed system error, NCCL version 2.7.8