maptask专题

【硬刚Hadoop】HADOOP MAPREDUCE(8):MapReduce内核源码解析(1)MapTask工作机制
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 MapTask工作机制 MapTask工作机制如图4-12所示。 图4-12 MapTask工作机制 (1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。 (2)Map阶段:该节点主要是将解析出

大数据技术之_05_Hadoop学习_03_MapReduce_MapTask工作机制+ReduceTask工作机制+OutputFormat数据输出+Join多种应用+计数器应用+数据清洗(ETL)
大数据技术之_05_Hadoop学习_03_MapReduce 3.3.4 WritableComparable排序3.3.5 WritableComparable排序案例实操(全排序)3.3.6 WritableComparable排序案例实操(区内排序)3.3.7 Combiner合并3.3.8 Combiner合并案例实操3.3.9 GroupingComparator分组(辅助排序/

Hadoop 1.x的Task,ReduceTask,MapTask随想
Hadoop的技术体系,最令人称赞的是细节。它的基本原理是非常容易理解的,细节是魔鬼。 hadoop的hdfs是文件系统存储,它有三类节点namenode, scondraynamenode, datanode,前两种在集群分别只有一个节点,而datanode在集群有很多个。hdfs的解耦做的非常好,以至于它可以单独运行,做一个海量数据的文件存储系统。它可以跟mapreduce分别运行。
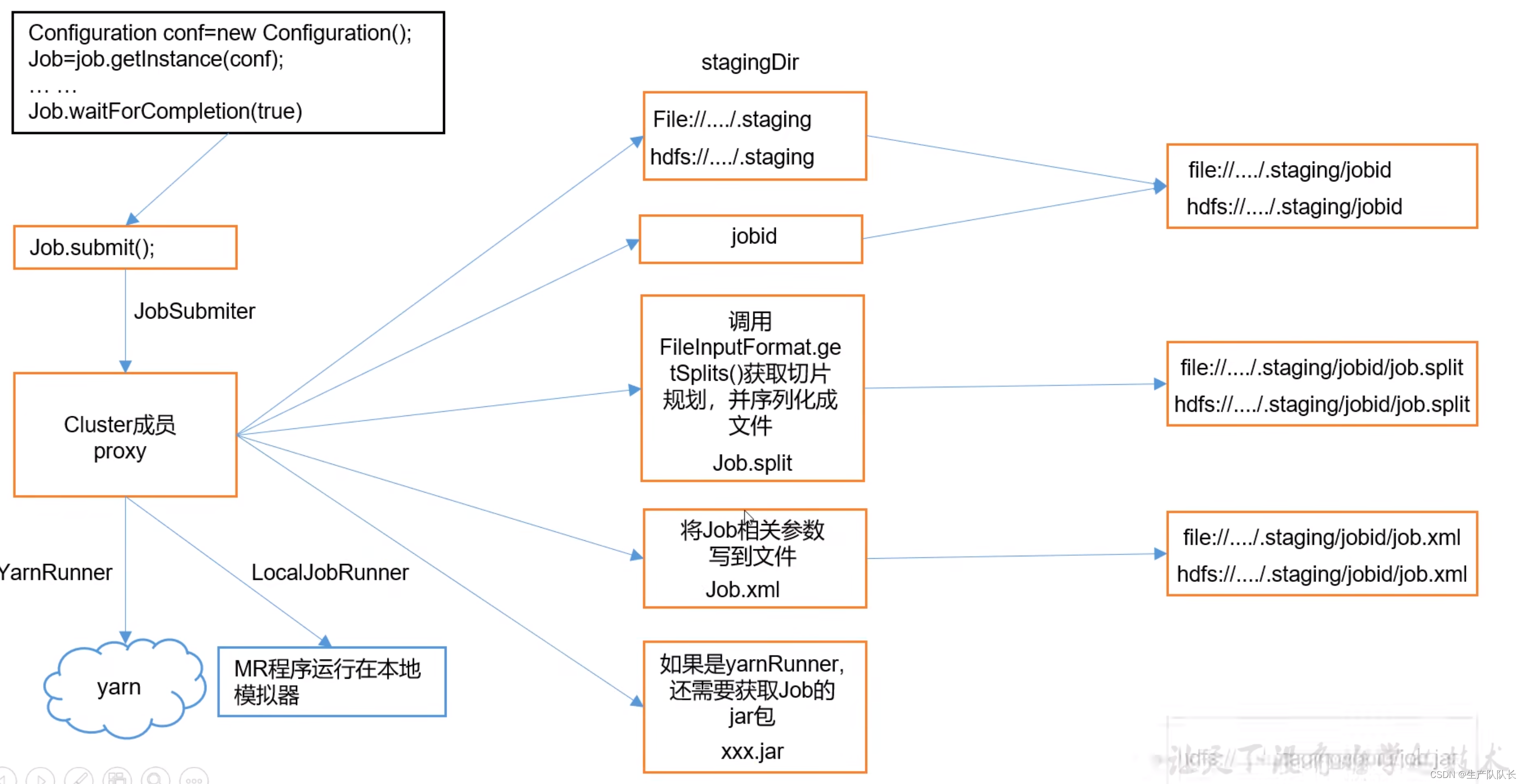
Hadoop3:MapReduce之MapTask的Job任务提交流程原理解读(1)
3、Job工作机制源码解读 用之前wordcount案例进行源码阅读,debug断点打在Job任务提交时 提交任务前,建立客户单连接 如下图,可以看出,只有两个客户端提供者,一个是YarnClient,一个是LocalClient。 显然,我这里是LocalClient模式 检查输出路径是否存在,存在则报错 这里的两串提示就很熟悉了,如果输出路径存在,则报错。 提交任务前会创建一个j

mapreduce的内部核心工作机制Shuffle-maptask生成的数据传输给reducetask的过程(fifteen day)
seven day second 学习了MapReduce的整体工作机制https://blog.csdn.net/ZJX103RLF/article/details/88965770 经过做了几个mapreduce练习,今儿再看看内部的核心工作机制(先学难的再回顾基础): 首先mapreduce是个分布式的,它的第一个工作进程叫maptask(真正的进程名字叫yarn child-->

Java大数据学习07--Mapreduce--MapTask和ReduceTask并行度的决定机制
一、mapTask并行度的决定机制 1、maptask的并行度决定map阶段的任务处理并发度,它可以决定job的处理速度。但并不是MapTask并行实例越多越好,它是综合了很多因素来决定的。 2、一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每

MapReduce源码分析——MapTask流程分析
前言 首先要说,MapTask,分为4种,分别是Job-setup Task,Job-cleanup Task,Task-cleanup和Map Task。 Job-setup Task、Job-cleanup Task分别是作业运行时启动的第一个任务和最后一个任务,主要工作分别是进行一些作业初始化和收尾工作,比如创建和删除作业临时输出目录;Task-cleanup Task则是任务失败或者被杀
关于Maptask任务单线程与多线程执行器解读
相比Mpareduce 老版本的API, 新版本的API 在maptask执行map任务的接口设计上有比较大的改动。 在老版的API中, MapRunner的run函数中: public void run(RecordReader input, OutputCollector output, Reporter reporter) throws IOException

【Hadoop】8.MapReduce框架原理-MapTask和ReduceTask的工作机制
MapTask工作机制 MapTask工作机制一共分为:Read阶段,Map阶段,Collect阶段,溢写阶段,Combine阶段 ps: 来自尚学堂ppt Read阶段: MapTask通过用户编写的ReacordReader,从输入Insplit中解析出一个个key/value。Map阶段: 该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/