incremental专题

CV-Paper-增量学习-Large Scale Incremental Learning
目录 0 简介1 什么是偏差2 网络3 loss4 偏差矫正层 0 简介 就简单的说明一下好了,首先是使用蒸馏学习,然后再利用验证集来学习一个简单的线性变换 ax + b 来减少偏差。 这里是把验证集也拿过来训练了,虽然只是学习一个简单的线性变换,因为这个线性变换只有两个参数,所以需要的数据量非常少,虽然这个变换很简单,但是非常有效的提高精度。 文章中说的偏差指的是增量学习

CV-笔记-增量学习incremental learning
又是一种深度学习的学习策略。 自然学习(Natural learning)系统本质上是渐进的,新知识是随着时间的推移而不断学习的,而现有的知识是保持不变的。现实世界中的许多计算机视觉应用程序都需要增量学习能力。例如,人脸识别系统应该能够在不忘记已学过的面孔的情况下添加新面孔。然而,大多数深度学习方法都存在灾难性的遗忘——当无法获得过去的数据时,性能会显著下降。 旧类数据的缺失带来了两个挑战:(
Error:scalac: Error: org.jetbrains.jps.incremental.scala.remote.ServerException
使用idea 编译scala程序时,如果出现上述错误, 原因是因为JDK与Scala的版本不匹配造成的。 解决方法: 方法1.重新安装1.8版本的的JDK。 方法2.如果当前已经是1.8版本的JDK时,需要做的就是降低scala的版本。 首先,在官网下载scala;(http://confluence.jetbrains.com/display/SCA/Scala+Pl

LinuxC语言中的增量式(incremental)开发思路
文章目录 一、题目需求5和分析如下:二、解决步骤如下:1.首先编写 distance 这个函数,可以先写一个简单的函数定义:2.可以测试这个函数定义是否有错3.继续写,并用打印语句测试函数4.继续写出最终的函数5.将其它函数写完6.如何组合所写函数来解决整个问题呢? 三、总结:函数的分层设计 假设要从头开始编写一个程序来解决问题 一、题目需求5和分析如下: 二、解决步骤

warning LNK4075: 忽略”/EDITANDCONTINUE”(由于”/INCREMENTAL:NO”规范)
有两种方法解决: 1. 配置属性 --> 链接器 --> 常规 --> 启动增量链接, 选择“是(/INCREMENTAL)”; 2. 配置属性 --> C/C++ --> 常规 --> 调试信息格式,选择“程序数据库(/Zi)”。

【论文笔记】基于预训练模型的持续学习(Continual Learning)(增量学习,Incremental Learning)
论文链接:Continual Learning with Pre-Trained Models: A Survey 代码链接:Github: LAMDA-PILOT 持续学习(Continual Learning, CL)旨在使模型在学习新知识的同时能够保留原来的知识信息了,然而现实任务中,模型并不能很好地保留原始信息,这也就是常说的灾害性遗忘(Catastrophic forgetting)
YOLOv3:A Incremental Improvement
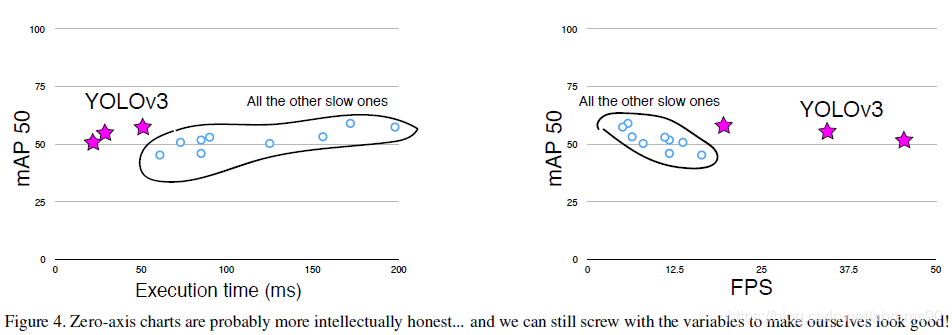
摘要: 我们对YOLO做了更新。我们做了一些列的小设计来优化效果。我们训练了这个新网络。与上次相比网络变大了但准确率更高。但不用担心,速度还是很快。320×320的YOLOv3在与SSD一样28.2mAP时只需22ms,是SSD的三倍快。在YOLOv3上使用原来0.5的IoU阈值检测mAP的效果非常好。算法在TitanX上AP50达到了57.9,速度51ms,RetinaNet则用198m
关于VC Linker的/INCREMENTAL链接选项(转)
VC Linker默认会使用/INCREMENTAL选项产生incremental linking效果。使用此选项产生的exe或dll文件将比不使用此选项产生的文件要大一些,因为Linker会向代码中插入填料代码或数据。Linker这样做的目的是为了在代码有变化时不用重新产生整个exe或者dll,而只用将里面的填料替换掉,从而达到incremental linking的目的。由于Linker向其

论文阅读《Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection》
论文地址:https://arxiv.org/abs/2203.13903 代码地址:https://github.com/facebookresearch/sylph-few-shot-detection 目录 1、存在的问题2、算法简介3、算法细节3.1、基础检测器3.2、小样本超网络3.2.1、支持集特征提取3.2.2、代码预测3.2.3、代码聚合和归一化 3.3、基础检测器的训练3
鸿蒙系统开发身份证阅读器报错:ERROR: Failed to find the incremental input file:xxxx/key/donsee.cer
最近在做身份证阅读器鸿蒙系统适配工作,碰到几点问题,记录下: 解决办法:登录DevEco Studio账号 ERROR: Failed to find the incremental input file:D:/donsee/Harmoyos/Donsee_Harmoryos_Project/key/donsee.cer 解决办法:进入项目配置,选择key文件夹下面的文件。

flink generic log-based incremental checkpoints 设计
背景 flink 在1.15版本后开始提供generic log-based incremental checkpoints的检查点方案,目的在于减少checkpoint的耗时,尽量缩短端到端的数据处理延迟,本文就来看下这种新类型的checkpoint的设计 generic log-based incremental checkpoints 设计 generic log-based incr
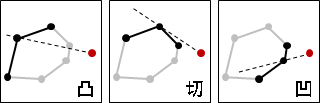
2D凸包算法(六):Incremental Method
Incremental Method 图示 Incremental Method 实时的保持一个凸包。每当输入一点,如果点在外面,计算此点与当前凸包的两条切线,去除凸包内的边以连接两条切线为新的边。如果在凸包内部就删除该点。 通过遍历凸包边界点。如果点的左右邻点都在改点与请求点连线的同侧,则说明该点就是切点,这个连线就是切线。反之则不是,需要继续查找。 时间复杂度为O(N²) 每次需要遍历所
rman incremental merge 增量备份自动合并 不再需要做多次0级备份
There are several ways to use a Merged Incremental Backup Strategy. However, before implementing the strategy, there are several things to consider when not using the basic Oracle Suggested Strategy a

《On the Shoulders of Giants: Incremental InfluenceMaximization in Evolving Social Networks》——解析
中文翻译——动态社会网络的增量式影响最大化算法 1.什么是影响力最大化 在2003年Kempe 等人就给出了准确的影响力最大化的定义,同时也证明了影响力最大化问题是一个NP难问题。影响力最大化问题可以定义如下:给定一个G=(V,E)的网络图,其中V表示图中的节点,E表示图中的边,同时给定一个正整数k,影响力最大化问题就是要在给定的传播模型下,找到一组数量为k的种子节点集,使得在

论文笔记:YOLOv3: An Incremental Improvement(yolo v3)
一、基本信息 标题:YOLOv3: An Incremental Improvement 时间:2018 引用格式:Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018). 二、研究背景 YOLOv1: 提出和R-CNN不同的方式
Incremental Object Detection via Meta-Learning【论文解析】
Incremental Object Detection via Meta-Learning 摘要1 介绍2 相关工作3 方法3.1 问题描述3.2元学习梯度预处理3.3增量式目标检测器 摘要 摘要:在真实世界的情境中,目标检测器可能会不断遇到来自新类别的物体实例。当现有的目标检测器应用于这种情景时,它们对旧类别的性能会显著下降。已经有一些努力来解决这个限制,它们都应用了知识

iCaRL Incremental Classifier and Representation Learning 翻译
摘要 在通往人工智能的道路上,一个主要的开放问题是逐步学习系统的开发,该系统可以随着时间的推移从数据流中学习越来越多的概念。 在这项工作中,我们引入了一种新的培训策略,iCaRL,它允许以这样一种类增量的方式学习:只有少量类的培训数据必须同时出现,并且可以逐步添加新的类 iCaRL同时学习强分类器和数据表示。 这与早期的工作不同,早期的工作从根本上局限于固定的数据表示,因此与深度学习架构不兼容
【论文总结】Incremental Few-Shot Object Detection(附翻译)
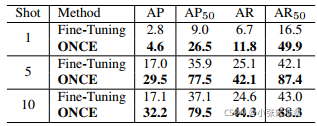
Incremental Few-Shot Object Detection 小样本增量目标检测 论文地址:https://arxiv.org/abs/2003.04668 代码暂未公开 思路:文章使用方法 Opened CenterNet(ONCE)以 CenterNet 单阶段检测方法为基础,加入一个元学习训练的类别编码生成模型来注册新类。新类样本只需要在 meta-training

Take Goods from Shelves A Dataset for Class-Incremental 翻译
摘要 在自助售货机中实现自动可视化结账的目标检测在零售业中引起了广泛的关注。 然而,一些关键性的挑战还没有得到足够的重视。 首先,迫切需要大规模、高质量的零售图像数据集来训练和评估检测模型。 其次,训练有素的模型应该能够以较低的成本应对频繁增加的新产品,而大多数前沿模型则不能。 本文提出了一种新的分层的大规模目标检测数据集——货架取货(TGFS),包含24个细粒度和3个粗类的38K图像。 提出了
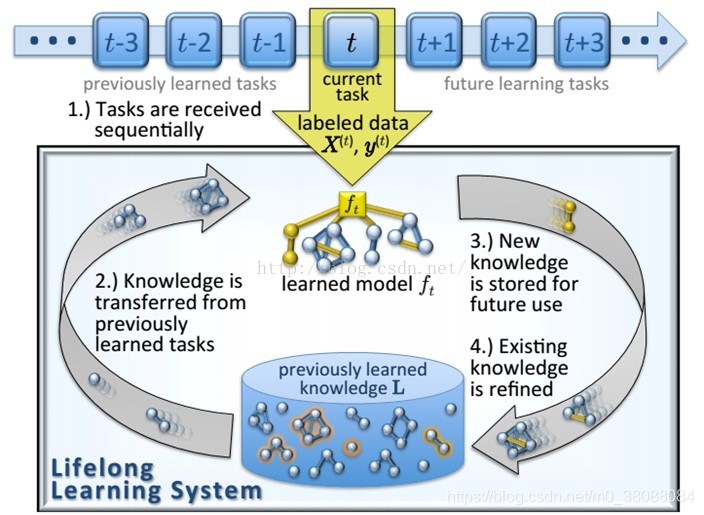
Life Long Learning(LLL) 终身学习(增量学习)(Continuous Learning Incremental Learning)
什么是lifelong learning 人在学习的时候,只有一个大脑,从初中到高中到大学,都是用同一个大脑在学习的 然而在机器学习当中,机器学习的情形真的和人很不一样 机器学习对于每一个作业都会训练一个不同的模型吗,例如从作业1到作业3会训练3个不同的模型 那么为什么我们不每一次作业都训练同一个模型呢 使用同一个模型来进行学习,就是life long learning Life Long L
INCREMENTAL BACKUP
增量备份:ORACLE允许我们使用RMAN只备份上次增量备份以来被更改的数据库。增量备份只能是在RMAN中执行,既可以联机,也可以脱机,既可以ARCHIVELOG,也可以NOARCHIVELOG。对于增量备份,他只能作用于数据文件,不能作用于归档日志。 增量备份的类型:差异备份,累积备份。 差异备份:差异备份是增量备份的默认类型,对于差异备份,RMAN会备份自上次同级或
![[论文分享] Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning](https://img-blog.csdnimg.cn/63780069390a4674b6a2637bb3a5459d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAZmx5aW5nIGJ1Zw==,size_20,color_FFFFFF,t_70,g_se,x_16)
[论文分享] Self-Promoted Prototype Refinement for Few-Shot Class-Incremental Learning
这篇论文是CVPR’ 2021的一篇Few-Shot增量学习(FSCIL)文章 No.contentPAPER{CVPR’ 2021} Self-Promoted Prototype Refinement for Few-Shot Class-Incremental LearningURL论文地址CODE代码地址 1.1 Motivation · 小样本增量学习增量类别样本过少,不足以训练好
FULL VS INCREMENTAL OTA
转载:http://www.xanh.co.uk/full-vs-incremental-ota/#more-144 There are two types of OTA. Each with its own advantages and usages. But there is only one type typical customer would see (the other one