本文主要是介绍论文阅读《Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:https://arxiv.org/abs/2203.13903
代码地址:https://github.com/facebookresearch/sylph-few-shot-detection
目录
- 1、存在的问题
- 2、算法简介
- 3、算法细节
- 3.1、基础检测器
- 3.2、小样本超网络
- 3.2.1、支持集特征提取
- 3.2.2、代码预测
- 3.2.3、代码聚合和归一化
- 3.3、基础检测器的训练
- 3.4、超网络的训练
- 3.5、元测试
- 4、实验
- 4.1、对比实验
- 4.2、消融实验
- 4.3、学习能力测试
- 5、结论
1、存在的问题
目前的小样本目标检测方法:基于两阶段微调、基于元学习。
基于微调:首先在基类上进行预训练,然后在来自基类和新类的一个小的平衡数据集上进行微调,即采用新类+基类联合训练。但由于计算和内存需求,将很难扩展到许多现实世界的应用。
基于元学习:侧重于检测新类别,而在面对已经学习到的基础类别时,往往无法保持原始检测器的性能,或者说会遗忘掉基础类别的信息。
大多数小样本目标检测方法由backbone和检测头组成,backbone从输入图像中提取特征图并输入到检测头中,检测头中并行执行多元分类分支和回归分支。
对于 N 路分类问题,分类器通常生成 N+1 个 logits,对应于 N 个类别和1个背景。回归器生成与每个类别相关联的边界框预测。通常,为每个类别生成一个权重,共N个权重,预测得分最高的类选择其对应的回归量作为输出。但由于所有参数都来自很少的新类训练样本,这就导致准确的回归和分类很难实现。
2、算法简介
针对增量小样本学习问题,探索一种可以快速从小样本中学习新类别,又不会忘记以前见过的类别的模型Sylph,且不需要对模型参数进行任何额外的优化。
面对新类别会直接训练,不用联合训练(连带着基类和已经学习到的新类别一起训练)
在基础训练的时候训练出一个和类别无关的回归器,在适应新类别时,只需要用这个回归器进行定位操作就可以了;
因此只需要考虑小样本分类问题,只关注分类器的参数;
训练新类别时,生成一组新的分类器参数(新类类代码),再通过元测试阶段将新类类代码和基类类代码合成在一起。
3、算法细节
包含两个部分:
1、一个基础目标检测器,将回归任务与分类任务解耦,对图像中的显著目标进行类别不可知的定位。使用多个二元分类器来代替一个多元分类器。
2、一个小样本超网络,为每个二元分类器提供特定的参数。

3.1、基础检测器
使用FCOS(Fully Convolutional One-Stage Object Detection)作为基础检测器
FCOS:基于像素级预测一阶段全卷积目标检测网络 anchor-free
FCOS的检测头由两部分组成:
1、与类别无关的回归器 B β B_\beta Bβ(基础训练部分学习得到)
2、多个二元分类器 C γ c ∗ C_{\gamma_{c}^*} Cγc∗(每个类别都对应一个二元分类器)
FCOS的回归过程:
直接对feature map中每个位置对应原图的边框都进行回归。
假设当前这张输出特征图的shape为:HW(C+1+4),其中,H和W是特征图的尺寸;C是类别数;
那么,在center-ness分支中的1是center-ness数值(当前位置与要预测的物体中心点之间的归一化距离,值在[0, 1]之间);
在回归分支中的4是4维关于检测框的输出值t、b、r、l(为当前位置与GT框4个顶点间的距离)。
将特征图解码为检测框的过程如下:
确定中心点:对于特征图中的某点(x,y),可以找到这个点对应原始图像的中心点。如果这个中心点在GT框内,那么为正样本点,它的类别就标记为这个GT框的类别,如果不在任何GT内,则为负样本点。
解码检测框:有了中心点,再加上网络预测值t、b、r、l,就可以得到检测框。
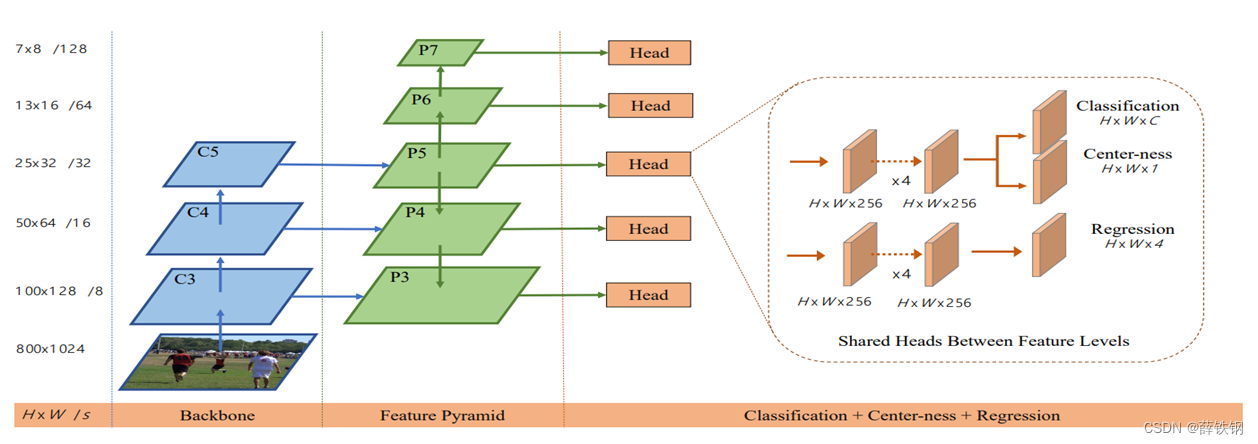
基础检测器完成回归,接下来只需要进行小样本分类即可
3.2、小样本超网络
解决小样本分类问题,为每个二元分类器提供参数
包括三个部分:支持集特征提取、代码预测、代码聚合和归一化
3.2.1、支持集特征提取
输入:支持集图像
输出:支持样本特征
1、超网络和基础网络共享主干,使用共享的主干网络提取支持集图像的特征(提取整张图片的特征);
2、ROIAlignV2 完成裁剪和映射,为每个目标实例生成一个固定大小的支持样本特征。
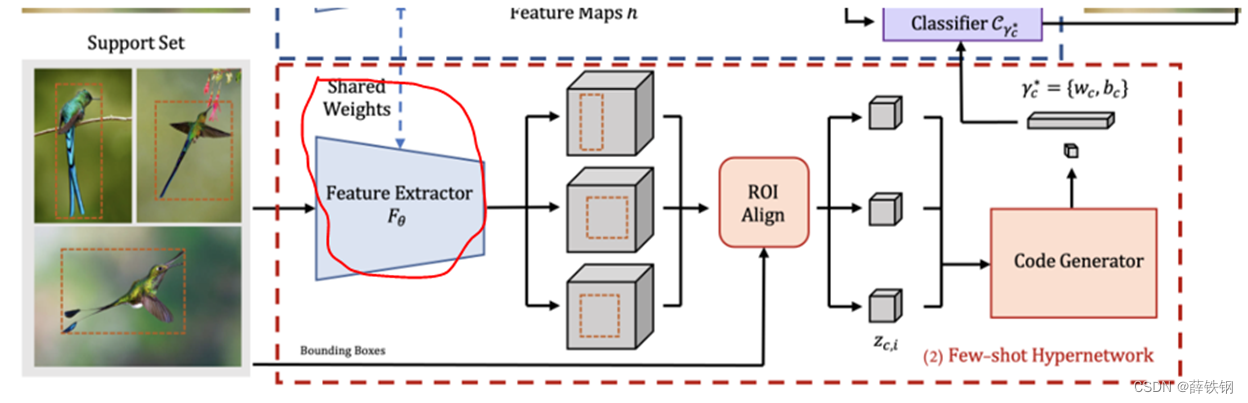
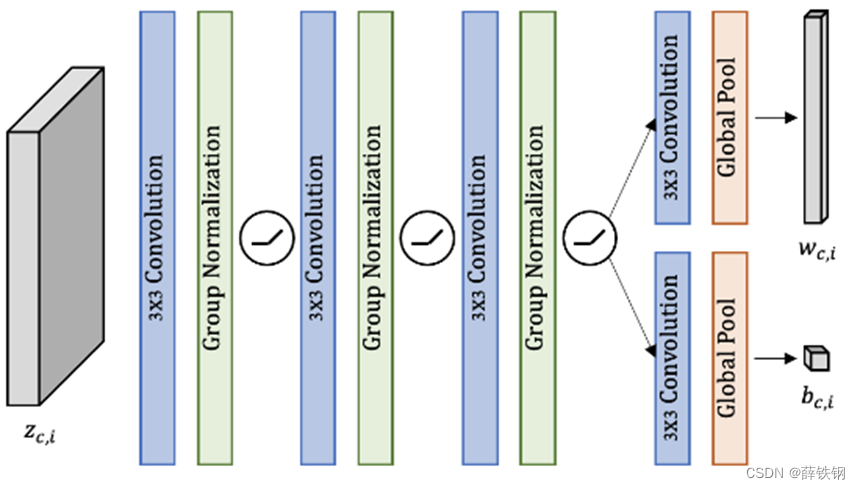
3.2.2、代码预测
输入:支持样本特征
输出:特征的权重和偏置
网络由3 × 3卷积层组成,与组归一化和ReLU激活函数交织在一起,然后是一个用于预测权重和偏置的层。最后使用全局平均池化将预测权重降至最终维度。
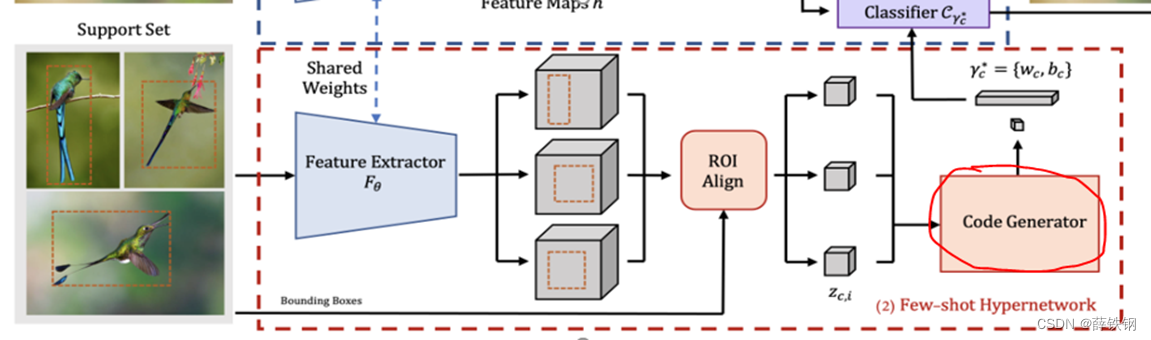
3.2.3、代码聚合和归一化
输入:特征的权重和偏置
输出:聚合和归一化结果
将特征的权重和偏置聚合在一起: w c = 1 K ∑ i = 0 k − 1 ( w c , i ) \begin{aligned}w_c=\frac{1}{K}\sum_{i=0}^{k-1}(w_{c,i})\end{aligned} wc=K1i=0∑k−1(wc,i); b c = 1 K ∑ i = 0 k − 1 ( b c , i ) b_c=\frac1K\sum_{i=0}^{k-1}(b_{c,i}) bc=K1∑i=0k−1(bc,i)
为避免梯度爆炸,聚合完成之后再沿通道轴进行L2归一化: w c ∣ ∣ w c ∣ ∣ \frac{w_c}{||w_c||} ∣∣wc∣∣wc
为增加兼容性,归一化完成后对权重进行缩放: w c ∗ = g ∣ ∣ w c ∣ ∣ w c w_c^*=\frac{g}{||w_c||}w_c wc∗=∣∣wc∣∣gwc
对于偏置,再额外增加一个先验偏置和标量,用于解决方差小的问题: b c ∗ = g b ∗ b c + b p b_c^*=g_b*b_c+b_p bc∗=gb∗bc+bp; b p = − log ( ( 1 − π ) / π ) , π = 0.01 b_p=-\log((1-\pi)/\pi),\pi=0.01 bp=−log((1−π)/π),π=0.01
3.3、基础检测器的训练
定义:
基类数据: C b C^b Cb
新类数据: C n C^n Cn
未经训练过的新类数据: c t n ∈ C n c^{n}_{t} \in C^n ctn∈Cn
已经训练过的新类数据: c t ′ n ∀ t ′ < t c^{n}_{t'} \forall t^′ < t ct′n∀t′<t
输入:丰富的基类数据
输出:与类别无关的边界框回归参数: β \beta β
基类的类代码: γ b = { w c b , b c b } ∀ c b ∈ C b \begin{aligned}\gamma_b=\{w_{c_b},b_{c_b}\} \forall c_b\in C^b\end{aligned} γb={wcb,bcb}∀cb∈Cb
生成基础检测器 D ϕ D_\phi Dϕ,能够在图像中为基类和潜在的新类生成边界框。
3.4、超网络的训练
定义:
基类数据: C b C^b Cb
新类数据: C n C^n Cn
从基类数据中采样一组包含N个类别的小样本集及其边界框(I,b)
包含N X K个样本的支持集
包含 N X 1个样本的查询集
输入:查询集
输出:新类的类代码: γ c b ∗ = ( w c b ∗ , b c b ∗ ) \gamma_{c_b}^*=(w_{c_b}^*,b_{c_b}^*) γcb∗=(wcb∗,bcb∗)
除了FCOS中分类器的前四层卷积不冻结之外,其他模块的参数都冻结
生成超网络 H ψ H_\psi Hψ,能够采用类代码对查询图像特征进行分类预测。
3.5、元测试
元测试阶段的作用:用于合成新类和基类类代码
从整个集合中对每个类选取 K 个样本,并通过超网络一次一个类进行前向传递以合成新类+基类类代码: γ c ∗ = { w c ∗ , b c ∗ } ∀ c ∈ C b ∪ C n \begin{aligned}\gamma_{c}^{*}=\{w_{c}^{*},b_{c}^{*}\}\forall c\in C^{b}\cup C^{n}\end{aligned} γc∗={wc∗,bc∗}∀c∈Cb∪Cn.
使用合成的类代码,基础检测器能够以与普通检测器相同的推理速度和行为进行推理。
4、实验
4.1、对比实验
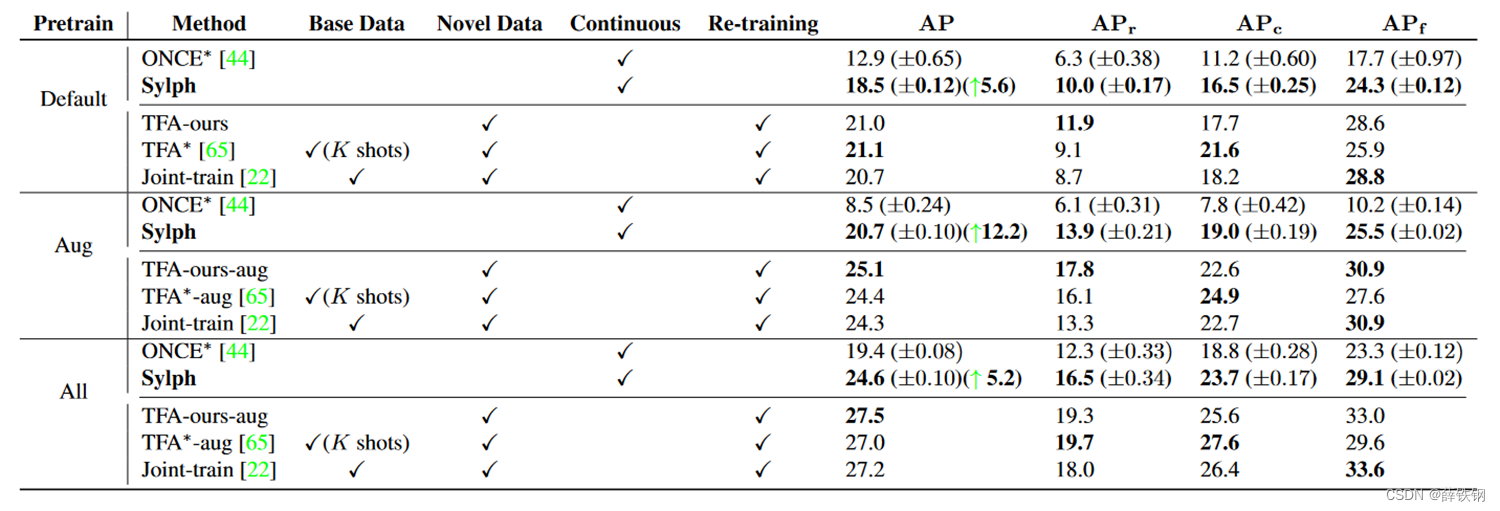
1、大规模数据集 LVIS :
使用罕见类作为新类,常见类作为基类。
Sylph 在不同的预训练策略上平均超过 ONCE 8%。在大量数据增强的情况下,ONCE∗ 在训练过程中难以收敛,导致其性能比 Sylph 差很多。
Default:模型在ImageNet-1k上进行预训练;
Aug:应用大规模抖动(LSJ)和RandAugment;
All:除上述增强外,还使用了IG-50M预训练骨干权重。
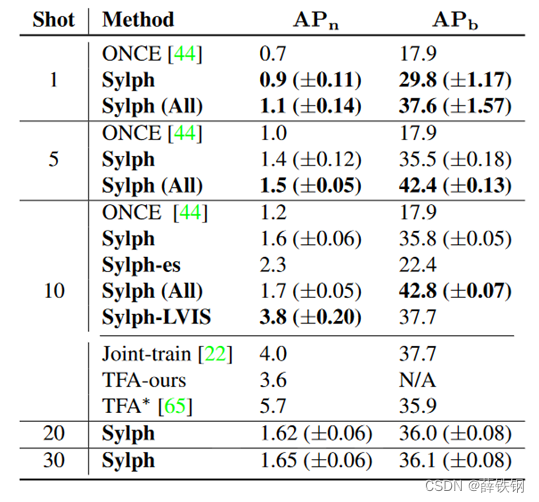
2、COCO数据集:
当K = 1,5,10时,我们将Sylph与ONCE进行基准测试,并为Sylph增加K = 20,30。还包括10shot TFA(基于两阶段微调的方法)。
Sylph-LVIS 在 COCO 的新类分割上(3.8%)与 Sylph 在 LVIS 的罕见类上(16.5%)存在很大的精度差距,这表明大规模预训练是必不可少的,因为它能产生:
(1)更精确的边界框定位器;
(2)能更好地泛化到新分类的特征提取器。
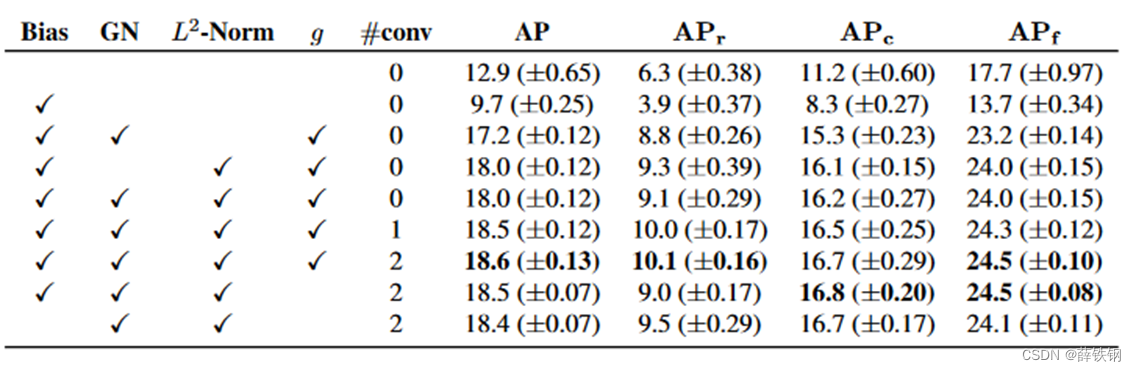
4.2、消融实验
1、组成模块的消融:
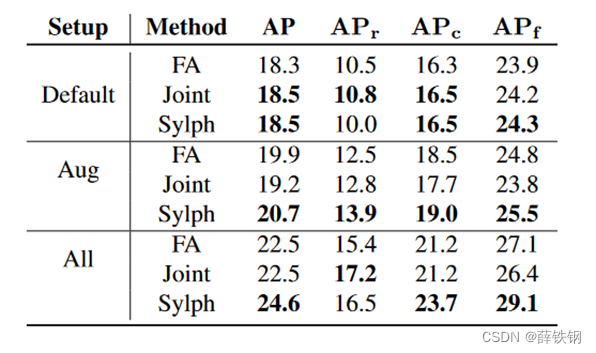
2、训练方式的消融:
FA:在元训练期间严格冻结整个基类检测器,保留预训练的基类代码。
Joint:使用默认设置对所有可用类进行预训练和元训练。
Sylph:元训练期间除了FCOS中分类器的前四层卷积不冻结之外,其他模块的参数都冻结
Joint的表现与FA相当,落后于Sylph。
这可能由两个原因来解释:
(1)随着基类数量的增加,Joint在元训练努力提升在基类上的性能;
(2)由于在类级别上使用均匀抽样,当与罕见类混合时,频繁类得到的抽样较少,从而导致在这些拆分上的AP下降。
4.3、学习能力测试
测试不同微调方法在新类上的平均精度。
本文方法遵循:在基类上训练FCOS,在新类上微调。
TFA-ours:遵循本文的训练方式,在微调阶段,只使用新类数据,回归器保持冻结,且分类器没有使用任何预训练的基类参数初始化。
TFA * -st:同时微调回归器和分类器。
结论:本文提出的Sylph并不需要对新类的学习潜力做出很大的牺牲也能够完成新类的学习。

5、结论
本方法也有局限性:
1、仍然依赖于大规模数据集。由于标注者的错误或标签集中不包含某个类别而导致的未标注对象会在数据集中产生假阴性,这可能会导致模型无法显示此类对象。
2、融合支持集特征的更复杂的聚合方法也可能带来进一步的改进。
这篇关于论文阅读《Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






